 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndexing Multimodal Language Models for Large-scale Image Retrieval
Apr 14, 2026Multimodal Large Language Models (MLLMs) have demonstrated strong cross-modal reasoning capabilities, yet their potential for vision-only tasks remains underexplored. We investigate MLLMs as training-free similarity estimators for instance-level image-to-image retrieval. Our approach prompts the model with paired images and converts next-token probabilities into similarity scores, enabling zero-shot re-ranking within large-scale retrieval pipelines. This design avoids specialized architectures and fine-tuning, leveraging the rich visual discrimination learned during multimodal pre-training. We address scalability by combining MLLMs with memory-efficient indexing and top-$k$ candidate re-ranking. Experiments across diverse benchmarks show that MLLMs outperform task-specific re-rankers outside their native domains and exhibit superior robustness to clutter, occlusion, and small objects. Despite strong results, we identify failure modes under severe appearance changes, highlighting opportunities for future research. Our findings position MLLMs as a promising alternative for open-world large-scale image retrieval.
ELViS: Efficient Visual Similarity from Local Descriptors that Generalizes Across Domains
Mar 30, 2026Large-scale instance-level training data is scarce, so models are typically trained on domain-specific datasets. Yet in real-world retrieval, they must handle diverse domains, making generalization to unseen data critical. We introduce ELViS, an image-to-image similarity model that generalizes effectively to unseen domains. Unlike conventional approaches, our model operates in similarity space rather than representation space, promoting cross-domain transfer. It leverages local descriptor correspondences, refines their similarities through an optimal transport step with data-dependent gains that suppress uninformative descriptors, and aggregates strong correspondences via a voting process into an image-level similarity. This design injects strong inductive biases, yielding a simple, efficient, and interpretable model. To assess generalization, we compile a benchmark of eight datasets spanning landmarks, artworks, products, and multi-domain collections, and evaluate ELViS as a re-ranking method. Our experiments show that ELViS outperforms competing methods by a large margin in out-of-domain scenarios and on average, while requiring only a fraction of their computational cost. Code available at: https://github.com/pavelsuma/ELViS/
LOCORE: Image Re-ranking with Long-Context Sequence Modeling
Mar 27, 2025We introduce LOCORE, Long-Context Re-ranker, a model that takes as input local descriptors corresponding to an image query and a list of gallery images and outputs similarity scores between the query and each gallery image. This model is used for image retrieval, where typically a first ranking is performed with an efficient similarity measure, and then a shortlist of top-ranked images is re-ranked based on a more fine-grained similarity measure. Compared to existing methods that perform pair-wise similarity estimation with local descriptors or list-wise re-ranking with global descriptors, LOCORE is the first method to perform list-wise re-ranking with local descriptors. To achieve this, we leverage efficient long-context sequence models to effectively capture the dependencies between query and gallery images at the local-descriptor level. During testing, we process long shortlists with a sliding window strategy that is tailored to overcome the context size limitations of sequence models. Our approach achieves superior performance compared with other re-rankers on established image retrieval benchmarks of landmarks (ROxf and RPar), products (SOP), fashion items (In-Shop), and bird species (CUB-200) while having comparable latency to the pair-wise local descriptor re-rankers.
AMES: Asymmetric and Memory-Efficient Similarity Estimation for Instance-level Retrieval
Aug 06, 2024This work investigates the problem of instance-level image retrieval re-ranking with the constraint of memory efficiency, ultimately aiming to limit memory usage to 1KB per image. Departing from the prevalent focus on performance enhancements, this work prioritizes the crucial trade-off between performance and memory requirements. The proposed model uses a transformer-based architecture designed to estimate image-to-image similarity by capturing interactions within and across images based on their local descriptors. A distinctive property of the model is the capability for asymmetric similarity estimation. Database images are represented with a smaller number of descriptors compared to query images, enabling performance improvements without increasing memory consumption. To ensure adaptability across different applications, a universal model is introduced that adjusts to a varying number of local descriptors during the testing phase. Results on standard benchmarks demonstrate the superiority of our approach over both hand-crafted and learned models. In particular, compared with current state-of-the-art methods that overlook their memory footprint, our approach not only attains superior performance but does so with a significantly reduced memory footprint. The code and pretrained models are publicly available at: https://github.com/pavelsuma/ames
Large-to-small Image Resolution Asymmetry in Deep Metric Learning
Oct 11, 2022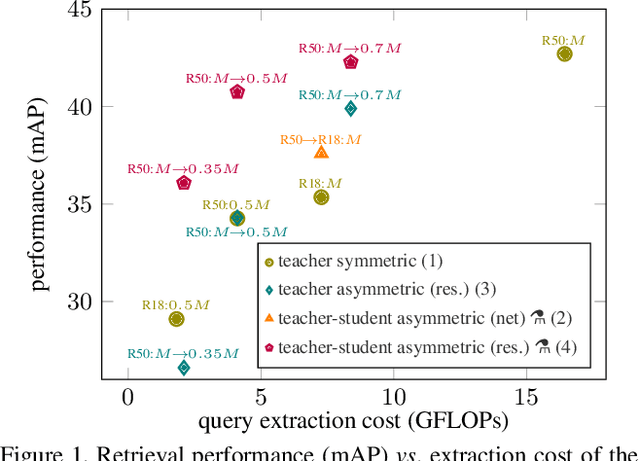
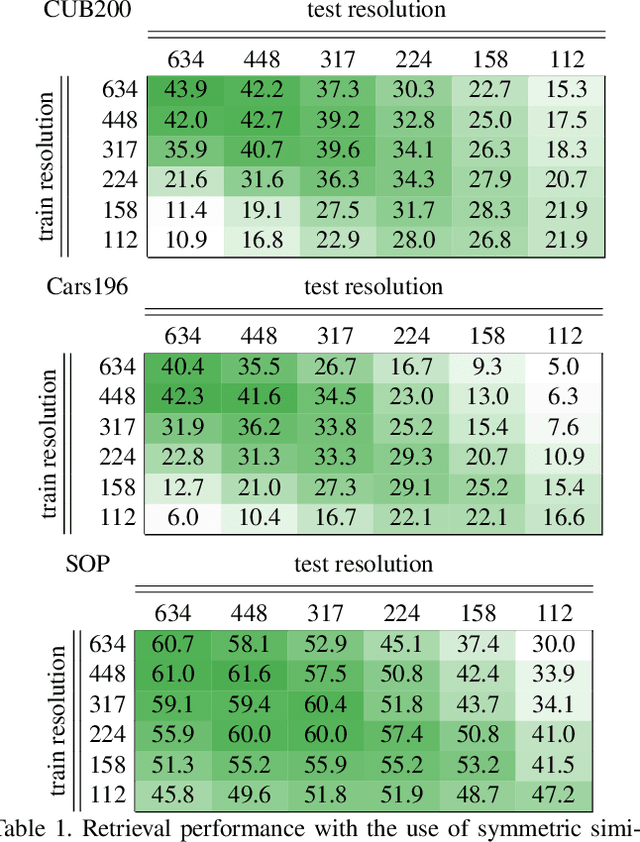
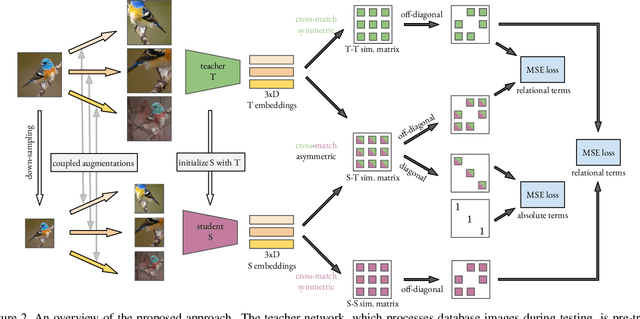
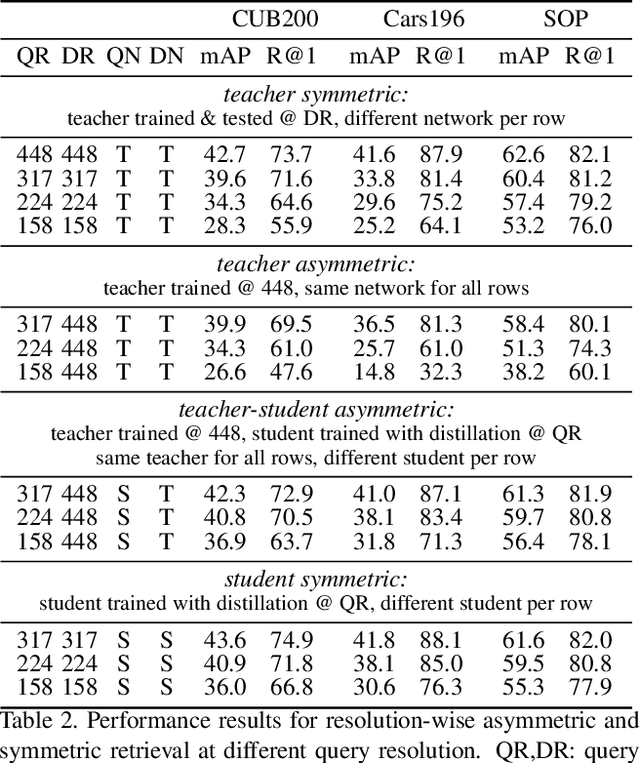
Deep metric learning for vision is trained by optimizing a representation network to map (non-)matching image pairs to (non-)similar representations. During testing, which typically corresponds to image retrieval, both database and query examples are processed by the same network to obtain the representation used for similarity estimation and ranking. In this work, we explore an asymmetric setup by light-weight processing of the query at a small image resolution to enable fast representation extraction. The goal is to obtain a network for database examples that is trained to operate on large resolution images and benefits from fine-grained image details, and a second network for query examples that operates on small resolution images but preserves a representation space aligned with that of the database network. We achieve this with a distillation approach that transfers knowledge from a fixed teacher network to a student via a loss that operates per image and solely relies on coupled augmentations without the use of any labels. In contrast to prior work that explores such asymmetry from the point of view of different network architectures, this work uses the same architecture but modifies the image resolution. We conclude that resolution asymmetry is a better way to optimize the performance/efficiency trade-off than architecture asymmetry. Evaluation is performed on three standard deep metric learning benchmarks, namely CUB200, Cars196, and SOP. Code: https://github.com/pavelsuma/raml