 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Gender-GAP Pipeline: A Gender-Aware Polyglot Pipeline for Gender Characterisation in 55 Languages
Aug 31, 2023



Gender biases in language generation systems are challenging to mitigate. One possible source for these biases is gender representation disparities in the training and evaluation data. Despite recent progress in documenting this problem and many attempts at mitigating it, we still lack shared methodology and tooling to report gender representation in large datasets. Such quantitative reporting will enable further mitigation, e.g., via data augmentation. This paper describes the Gender-GAP Pipeline (for Gender-Aware Polyglot Pipeline), an automatic pipeline to characterize gender representation in large-scale datasets for 55 languages. The pipeline uses a multilingual lexicon of gendered person-nouns to quantify the gender representation in text. We showcase it to report gender representation in WMT training data and development data for the News task, confirming that current data is skewed towards masculine representation. Having unbalanced datasets may indirectly optimize our systems towards outperforming one gender over the others. We suggest introducing our gender quantification pipeline in current datasets and, ideally, modifying them toward a balanced representation.
DIG In: Evaluating Disparities in Image Generations with Indicators for Geographic Diversity
Aug 15, 2023



The unprecedented photorealistic results achieved by recent text-to-image generative systems and their increasing use as plug-and-play content creation solutions make it crucial to understand their potential biases. In this work, we introduce three indicators to evaluate the realism, diversity and prompt-generation consistency of text-to-image generative systems when prompted to generate objects from across the world. Our indicators complement qualitative analysis of the broader impact of such systems by enabling automatic and efficient benchmarking of geographic disparities, an important step towards building responsible visual content creation systems. We use our proposed indicators to analyze potential geographic biases in state-of-the-art visual content creation systems and find that: (1) models have less realism and diversity of generations when prompting for Africa and West Asia than Europe, (2) prompting with geographic information comes at a cost to prompt-consistency and diversity of generated images, and (3) models exhibit more region-level disparities for some objects than others. Perhaps most interestingly, our indicators suggest that progress in image generation quality has come at the cost of real-world geographic representation. Our comprehensive evaluation constitutes a crucial step towards ensuring a positive experience of visual content creation for everyone.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Weisfeiler and Lehman Go Measurement Modeling: Probing the Validity of the WL Test
Jul 11, 2023The expressive power of graph neural networks is usually measured by comparing how many pairs of graphs or nodes an architecture can possibly distinguish as non-isomorphic to those distinguishable by the $k$-dimensional Weisfeiler-Lehman ($k$-WL) test. In this paper, we uncover misalignments between practitioners' conceptualizations of expressive power and $k$-WL through a systematic analysis of the reliability and validity of $k$-WL. We further conduct a survey ($n = 18$) of practitioners to surface their conceptualizations of expressive power and their assumptions about $k$-WL. In contrast to practitioners' opinions, our analysis (which draws from graph theory and benchmark auditing) reveals that $k$-WL does not guarantee isometry, can be irrelevant to real-world graph tasks, and may not promote generalization or trustworthiness. We argue for extensional definitions and measurement of expressive power based on benchmarks; we further contribute guiding questions for constructing such benchmarks, which is critical for progress in graph machine learning.
Call for Papers -- The BabyLM Challenge: Sample-efficient pretraining on a developmentally plausible corpus
Jan 27, 2023

We present the call for papers for the BabyLM Challenge: Sample-efficient pretraining on a developmentally plausible corpus. This shared task is intended for participants with an interest in small scale language modeling, human language acquisition, low-resource NLP, and cognitive modeling. In partnership with CoNLL and CMCL, we provide a platform for approaches to pretraining with a limited-size corpus sourced from data inspired by the input to children. The task has three tracks, two of which restrict the training data to pre-released datasets of 10M and 100M words and are dedicated to explorations of approaches such as architectural variations, self-supervised objectives, or curriculum learning. The final track only restricts the amount of text used, allowing innovation in the choice of the data, its domain, and even its modality (i.e., data from sources other than text is welcome). We will release a shared evaluation pipeline which scores models on a variety of benchmarks and tasks, including targeted syntactic evaluations and natural language understanding.
Language model acceptability judgements are not always robust to context
Dec 18, 2022Targeted syntactic evaluations of language models ask whether models show stable preferences for syntactically acceptable content over minimal-pair unacceptable inputs. Most targeted syntactic evaluation datasets ask models to make these judgements with just a single context-free sentence as input. This does not match language models' training regime, in which input sentences are always highly contextualized by the surrounding corpus. This mismatch raises an important question: how robust are models' syntactic judgements in different contexts? In this paper, we investigate the stability of language models' performance on targeted syntactic evaluations as we vary properties of the input context: the length of the context, the types of syntactic phenomena it contains, and whether or not there are violations of grammaticality. We find that model judgements are generally robust when placed in randomly sampled linguistic contexts. However, they are substantially unstable for contexts containing syntactic structures matching those in the critical test content. Among all tested models (GPT-2 and five variants of OPT), we significantly improve models' judgements by providing contexts with matching syntactic structures, and conversely significantly worsen them using unacceptable contexts with matching but violated syntactic structures. This effect is amplified by the length of the context, except for unrelated inputs. We show that these changes in model performance are not explainable by simple features matching the context and the test inputs, such as lexical overlap and dependency overlap. This sensitivity to highly specific syntactic features of the context can only be explained by the models' implicit in-context learning abilities.
The Curious Case of Absolute Position Embeddings
Oct 23, 2022



Transformer language models encode the notion of word order using positional information. Most commonly, this positional information is represented by absolute position embeddings (APEs), that are learned from the pretraining data. However, in natural language, it is not absolute position that matters, but relative position, and the extent to which APEs can capture this type of information has not been investigated. In this work, we observe that models trained with APE over-rely on positional information to the point that they break-down when subjected to sentences with shifted position information. Specifically, when models are subjected to sentences starting from a non-zero position (excluding the effect of priming), they exhibit noticeably degraded performance on zero to full-shot tasks, across a range of model families and model sizes. Our findings raise questions about the efficacy of APEs to model the relativity of position information, and invite further introspection on the sentence and word order processing strategies employed by these models.
Learning Transductions to Test Systematic Compositionality
Aug 17, 2022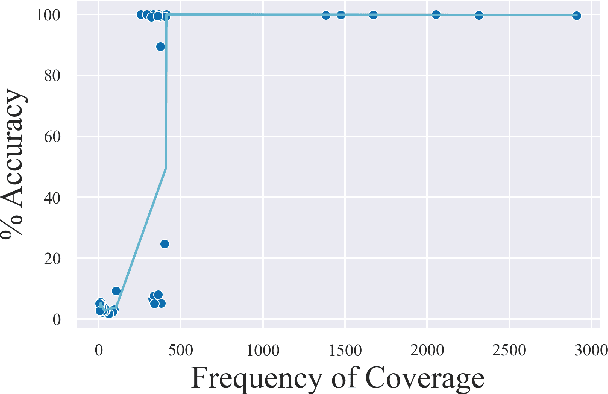
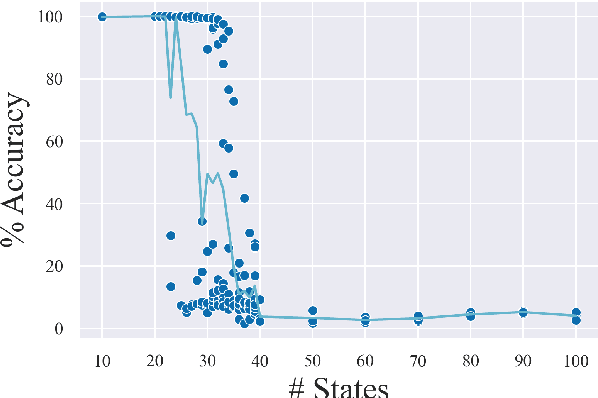
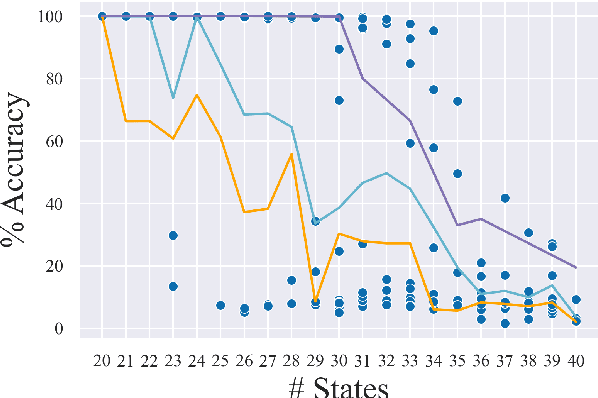
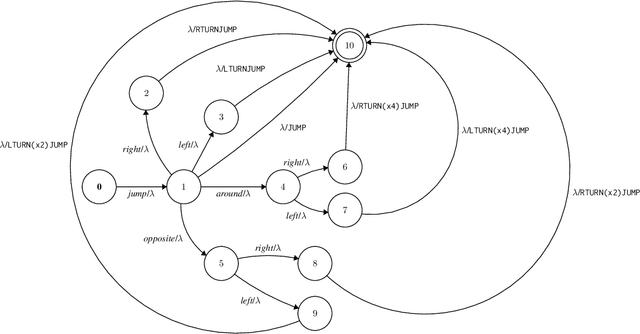
Recombining known primitive concepts into larger novel combinations is a quintessentially human cognitive capability. Whether large neural models in NLP acquire this ability while learning from data is an open question. In this paper, we look at this problem from the perspective of formal languages. We use deterministic finite-state transducers to make an unbounded number of datasets with controllable properties governing compositionality. By randomly sampling over many transducers, we explore which of their properties (number of states, alphabet size, number of transitions etc.) contribute to learnability of a compositional relation by a neural network. In general, we find that the models either learn the relations completely or not at all. The key is transition coverage, setting a soft learnability limit at 400 examples per transition.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022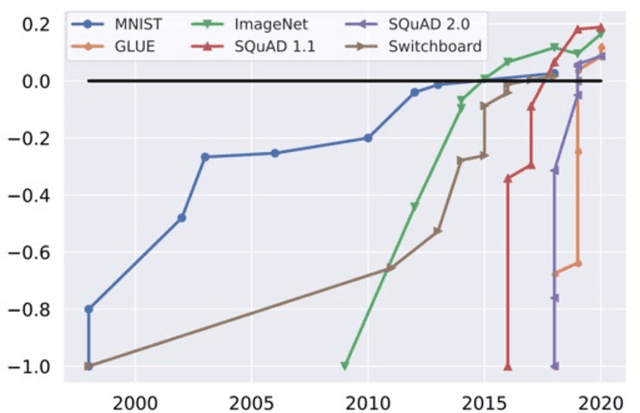
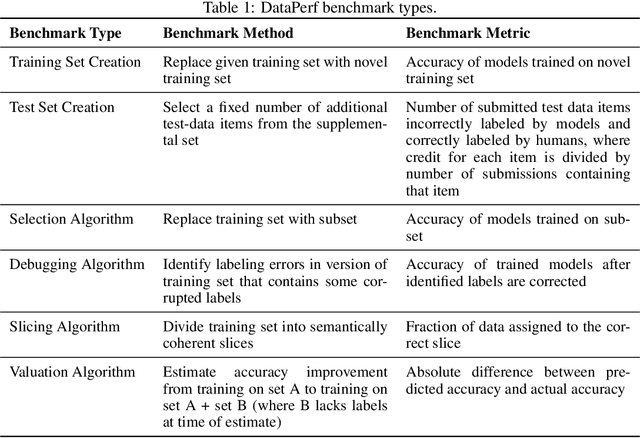
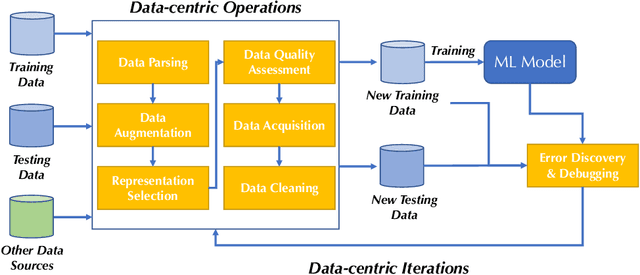
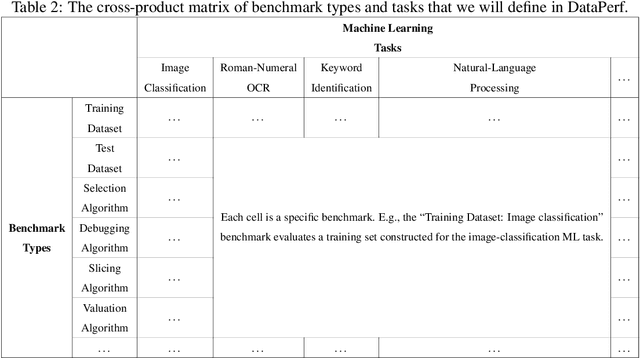
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.
Perturbation Augmentation for Fairer NLP
May 25, 2022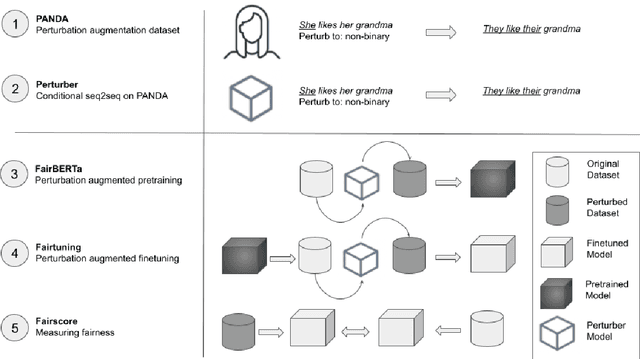

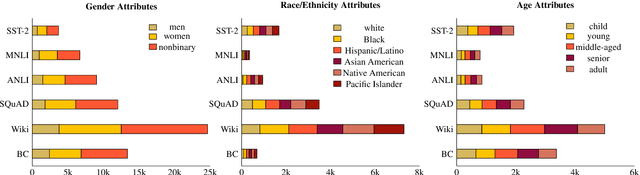
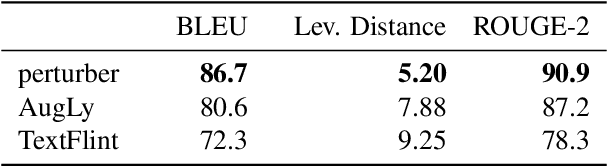
Unwanted and often harmful social biases are becoming ever more salient in NLP research, affecting both models and datasets. In this work, we ask: does training on demographically perturbed data lead to more fair language models? We collect a large dataset of human annotated text perturbations and train an automatic perturber on it, which we show to outperform heuristic alternatives. We find: (i) Language models (LMs) pre-trained on demographically perturbed corpora are more fair, at least, according to our current best metrics for measuring model fairness, and (ii) LMs finetuned on perturbed GLUE datasets exhibit less demographic bias on downstream tasks. We find that improved fairness does not come at the expense of accuracy. Although our findings appear promising, there are still some limitations, as well as outstanding questions about how best to evaluate the (un)fairness of large language models. We hope that this initial exploration of neural demographic perturbation will help drive more improvement towards fairer NLP.