 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACE: Pose Annotations in Cluttered Environments
Dec 23, 2023Pose estimation is a crucial task in computer vision, enabling tracking and manipulating objects in images or videos. While several datasets exist for pose estimation, there is a lack of large-scale datasets specifically focusing on cluttered scenes with occlusions. This limitation is a bottleneck in the development and evaluation of pose estimation methods, particularly toward the goal of real-world application in environments where occlusions are common. Addressing this, we introduce PACE (Pose Annotations in Cluttered Environments), a large-scale benchmark designed to advance the development and evaluation of pose estimation methods in cluttered scenarios. PACE encompasses 54,945 frames with 257,673 annotations across 300 videos, covering 576 objects from 44 categories and featuring a mix of rigid and articulated items in cluttered scenes. To annotate the real-world data efficiently, we developed an innovative annotation system utilizing a calibrated 3-camera setup. We test state-of-the-art algorithms in PACE along two tracks: pose estimation, and object pose tracking, revealing the benchmark's challenges and research opportunities. We plan to release PACE as a public evaluation benchmark, along the annotations tools we developed, to stimulate further advancements in the field. Our code and data is available on https://github.com/qq456cvb/PACE.
Zero-Shot Open-Vocabulary Tracking with Large Pre-Trained Models
Oct 10, 2023



Object tracking is central to robot perception and scene understanding. Tracking-by-detection has long been a dominant paradigm for object tracking of specific object categories. Recently, large-scale pre-trained models have shown promising advances in detecting and segmenting objects and parts in 2D static images in the wild. This begs the question: can we re-purpose these large-scale pre-trained static image models for open-vocabulary video tracking? In this paper, we re-purpose an open-vocabulary detector, segmenter, and dense optical flow estimator, into a model that tracks and segments objects of any category in 2D videos. Our method predicts object and part tracks with associated language descriptions in monocular videos, rebuilding the pipeline of Tractor with modern large pre-trained models for static image detection and segmentation: we detect open-vocabulary object instances and propagate their boxes from frame to frame using a flow-based motion model, refine the propagated boxes with the box regression module of the visual detector, and prompt an open-world segmenter with the refined box to segment the objects. We decide the termination of an object track based on the objectness score of the propagated boxes, as well as forward-backward optical flow consistency. We re-identify objects across occlusions using deep feature matching. We show that our model achieves strong performance on multiple established video object segmentation and tracking benchmarks, and can produce reasonable tracks in manipulation data. In particular, our model outperforms previous state-of-the-art in UVO and BURST, benchmarks for open-world object tracking and segmentation, despite never being explicitly trained for tracking. We hope that our approach can serve as a simple and extensible framework for future research.
Cross-Image Context Matters for Bongard Problems
Sep 07, 2023Current machine learning methods struggle to solve Bongard problems, which are a type of IQ test that requires deriving an abstract "concept" from a set of positive and negative "support" images, and then classifying whether or not a new query image depicts the key concept. On Bongard-HOI, a benchmark for natural-image Bongard problems, existing methods have only reached 66% accuracy (where chance is 50%). Low accuracy is often attributed to neural nets' lack of ability to find human-like symbolic rules. In this work, we point out that many existing methods are forfeiting accuracy due to a much simpler problem: they do not incorporate information contained in the support set as a whole, and rely instead on information extracted from individual supports. This is a critical issue, because unlike in few-shot learning tasks concerning object classification, the "key concept" in a typical Bongard problem can only be distinguished using multiple positives and multiple negatives. We explore a variety of simple methods to take this cross-image context into account, and demonstrate substantial gains over prior methods, leading to new state-of-the-art performance on Bongard-LOGO (75.3%) and Bongard-HOI (72.45%) and strong performance on the original Bongard problem set (60.84%).
PointOdyssey: A Large-Scale Synthetic Dataset for Long-Term Point Tracking
Jul 27, 2023



We introduce PointOdyssey, a large-scale synthetic dataset, and data generation framework, for the training and evaluation of long-term fine-grained tracking algorithms. Our goal is to advance the state-of-the-art by placing emphasis on long videos with naturalistic motion. Toward the goal of naturalism, we animate deformable characters using real-world motion capture data, we build 3D scenes to match the motion capture environments, and we render camera viewpoints using trajectories mined via structure-from-motion on real videos. We create combinatorial diversity by randomizing character appearance, motion profiles, materials, lighting, 3D assets, and atmospheric effects. Our dataset currently includes 104 videos, averaging 2,000 frames long, with orders of magnitude more correspondence annotations than prior work. We show that existing methods can be trained from scratch in our dataset and outperform the published variants. Finally, we introduce modifications to the PIPs point tracking method, greatly widening its temporal receptive field, which improves its performance on PointOdyssey as well as on two real-world benchmarks. Our data and code are publicly available at: https://pointodyssey.com
TIDEE: Tidying Up Novel Rooms using Visuo-Semantic Commonsense Priors
Jul 21, 2022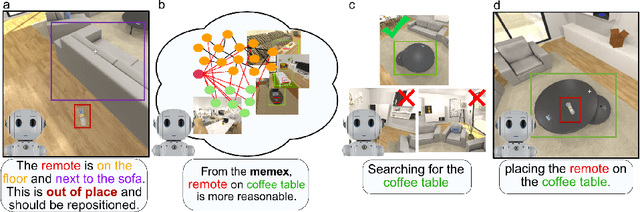
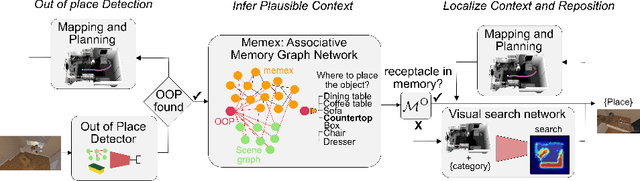

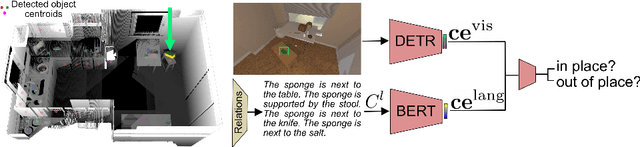
We introduce TIDEE, an embodied agent that tidies up a disordered scene based on learned commonsense object placement and room arrangement priors. TIDEE explores a home environment, detects objects that are out of their natural place, infers plausible object contexts for them, localizes such contexts in the current scene, and repositions the objects. Commonsense priors are encoded in three modules: i) visuo-semantic detectors that detect out-of-place objects, ii) an associative neural graph memory of objects and spatial relations that proposes plausible semantic receptacles and surfaces for object repositions, and iii) a visual search network that guides the agent's exploration for efficiently localizing the receptacle-of-interest in the current scene to reposition the object. We test TIDEE on tidying up disorganized scenes in the AI2THOR simulation environment. TIDEE carries out the task directly from pixel and raw depth input without ever having observed the same room beforehand, relying only on priors learned from a separate set of training houses. Human evaluations on the resulting room reorganizations show TIDEE outperforms ablative versions of the model that do not use one or more of the commonsense priors. On a related room rearrangement benchmark that allows the agent to view the goal state prior to rearrangement, a simplified version of our model significantly outperforms a top-performing method by a large margin. Code and data are available at the project website: https://tidee-agent.github.io/.
A Simple Baseline for BEV Perception Without LiDAR
Jun 16, 2022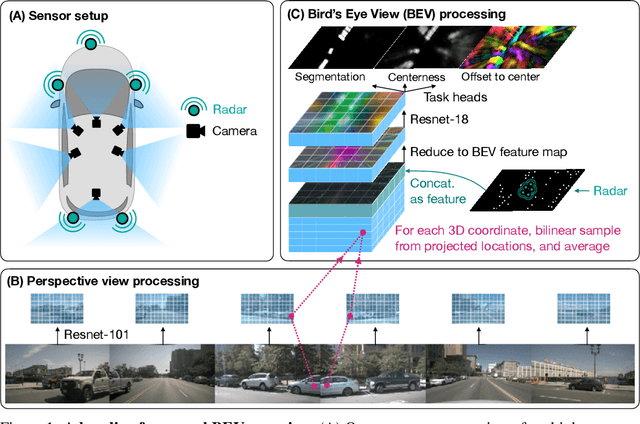



Building 3D perception systems for autonomous vehicles that do not rely on LiDAR is a critical research problem because of the high expense of LiDAR systems compared to cameras and other sensors. Current methods use multi-view RGB data collected from cameras around the vehicle and neurally "lift" features from the perspective images to the 2D ground plane, yielding a "bird's eye view" (BEV) feature representation of the 3D space around the vehicle. Recent research focuses on the way the features are lifted from images to the BEV plane. We instead propose a simple baseline model, where the "lifting" step simply averages features from all projected image locations, and find that it outperforms the current state-of-the-art in BEV vehicle segmentation. Our ablations show that batch size, data augmentation, and input resolution play a large part in performance. Additionally, we reconsider the utility of radar input, which has previously been either ignored or found non-helpful by recent works. With a simple RGB-radar fusion module, we obtain a sizable boost in performance, approaching the accuracy of a LiDAR-enabled system.
Particle Videos Revisited: Tracking Through Occlusions Using Point Trajectories
Apr 08, 2022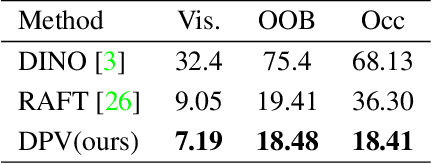
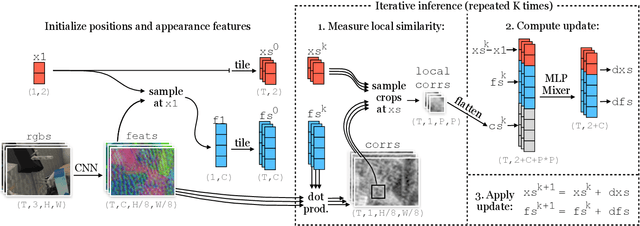
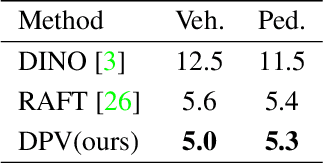
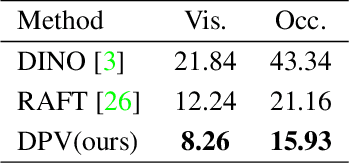
Tracking pixels in videos is typically studied as an optical flow estimation problem, where every pixel is described with a displacement vector that locates it in the next frame. Even though wider temporal context is freely available, prior efforts to take this into account have yielded only small gains over 2-frame methods. In this paper, we revisit Sand and Teller's "particle video" approach, and study pixel tracking as a long-range motion estimation problem, where every pixel is described with a trajectory that locates it in multiple future frames. We re-build this classic approach using components that drive the current state-of-the-art in flow and object tracking, such as dense cost maps, iterative optimization, and learned appearance updates. We train our models using long-range amodal point trajectories mined from existing optical flow datasets that we synthetically augment with occlusions. We test our approach in trajectory estimation benchmarks and in keypoint label propagation tasks, and compare favorably against state-of-the-art optical flow and feature tracking methods.
CoCoNets: Continuous Contrastive 3D Scene Representations
Apr 08, 2021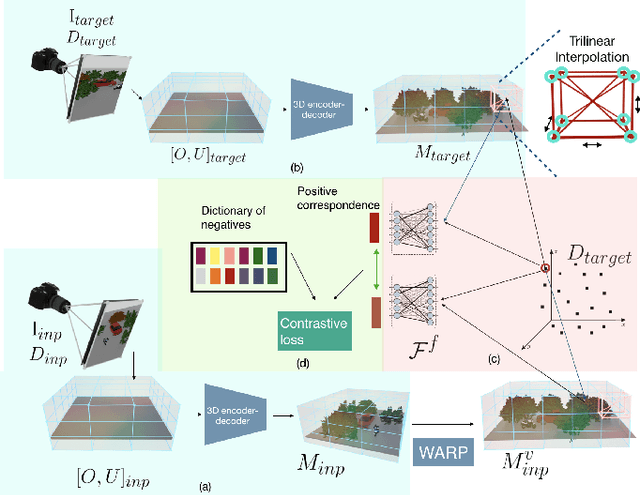
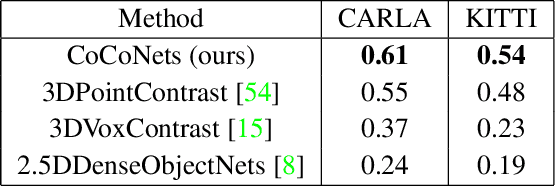
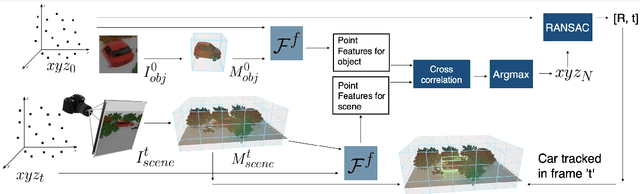

This paper explores self-supervised learning of amodal 3D feature representations from RGB and RGB-D posed images and videos, agnostic to object and scene semantic content, and evaluates the resulting scene representations in the downstream tasks of visual correspondence, object tracking, and object detection. The model infers a latent3D representation of the scene in the form of 3D feature points, where each continuous world 3D point is mapped to its corresponding feature vector. The model is trained for contrastive view prediction by rendering 3D feature clouds in queried viewpoints and matching against the 3D feature point cloud predicted from the query view. Notably, the representation can be queried for any 3D location, even if it is not visible from the input view. Our model brings together three powerful ideas of recent exciting research work: 3D feature grids as a neural bottleneck for view prediction, implicit functions for handling resolution limitations of 3D grids, and contrastive learning for unsupervised training of feature representations. We show the resulting 3D visual feature representations effectively scale across objects and scenes, imagine information occluded or missing from the input viewpoints, track objects over time, align semantically related objects in 3D, and improve 3D object detection. We outperform many existing state-of-the-art methods for 3D feature learning and view prediction, which are either limited by 3D grid spatial resolution, do not attempt to build amodal 3D representations, or do not handle combinatorial scene variability due to their non-convolutional bottlenecks.
Track, Check, Repeat: An EM Approach to Unsupervised Tracking
Apr 07, 2021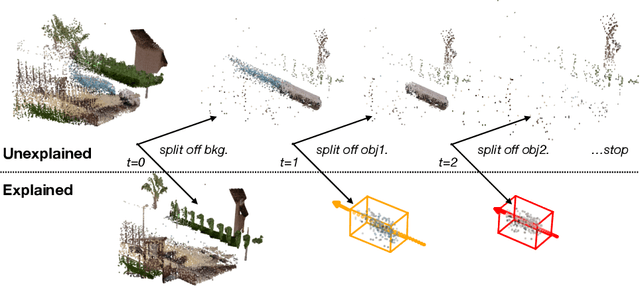
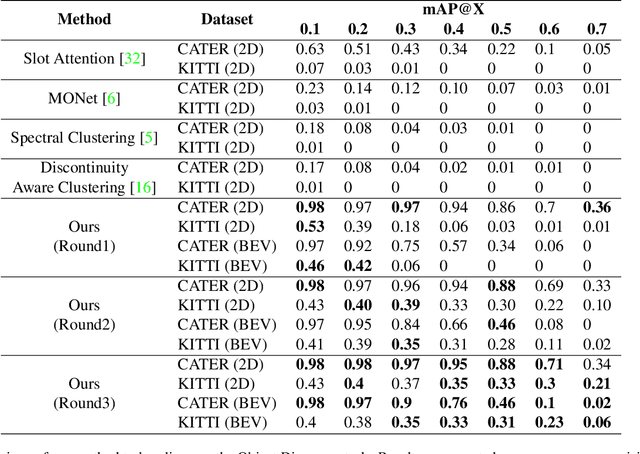


We propose an unsupervised method for detecting and tracking moving objects in 3D, in unlabelled RGB-D videos. The method begins with classic handcrafted techniques for segmenting objects using motion cues: we estimate optical flow and camera motion, and conservatively segment regions that appear to be moving independently of the background. Treating these initial segments as pseudo-labels, we learn an ensemble of appearance-based 2D and 3D detectors, under heavy data augmentation. We use this ensemble to detect new instances of the "moving" type, even if they are not moving, and add these as new pseudo-labels. Our method is an expectation-maximization algorithm, where in the expectation step we fire all modules and look for agreement among them, and in the maximization step we re-train the modules to improve this agreement. The constraint of ensemble agreement helps combat contamination of the generated pseudo-labels (during the E step), and data augmentation helps the modules generalize to yet-unlabelled data (during the M step). We compare against existing unsupervised object discovery and tracking methods, using challenging videos from CATER and KITTI, and show strong improvements over the state-of-the-art.
Move to See Better: Towards Self-Supervised Amodal Object Detection
Nov 30, 2020
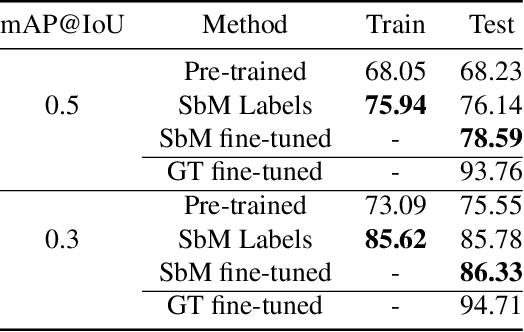
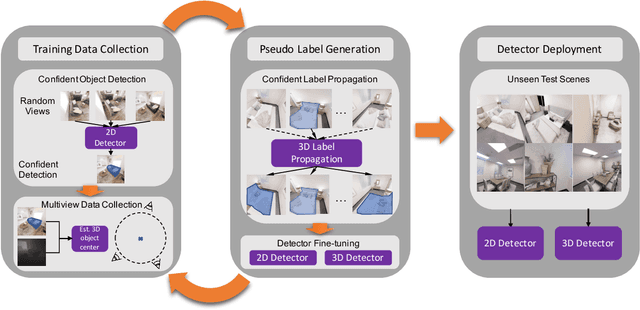
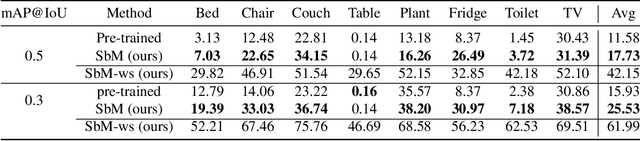
Humans learn to better understand the world by moving around their environment to get more informative viewpoints of the scene. Most methods for 2D visual recognition tasks such as object detection and segmentation treat images of the same scene as individual samples and do not exploit object permanence in multiple views. Generalization to novel scenes and views thus requires additional training with lots of human annotations. In this paper, we propose a self-supervised framework to improve an object detector in unseen scenarios by moving an agent around in a 3D environment and aggregating multi-view RGB-D information. We unproject confident 2D object detections from the pre-trained detector and perform unsupervised 3D segmentation on the point cloud. The segmented 3D objects are then re-projected to all other views to obtain pseudo-labels for fine-tuning. Experiments on both indoor and outdoor datasets show that (1) our framework performs high-quality 3D segmentation from raw RGB-D data and a pre-trained 2D detector; (2) fine-tuning with self-supervision improves the 2D detector significantly where an unseen RGB image is given as input at test time; (3) training a 3D detector with self-supervision outperforms a comparable self-supervised method by a large margin.