 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefined $α$-Divergence Variational Inference via Rejection Sampling
Oct 29, 2019
We present an approximate inference method, based on a synergistic combination of R\'enyi $\alpha$-divergence variational inference (RDVI) and rejection sampling (RS). RDVI is based on minimization of R\'enyi $\alpha$-divergence $D_\alpha(p||q)$ between the true distribution $p(x)$ and a variational approximation $q(x)$; RS draws samples from a distribution $p(x) = \tilde{p}(x)/Z_{p}$ using a proposal $q(x)$, s.t. $Mq(x) \geq \tilde{p}(x), \forall x$. Our inference method is based on a crucial observation that $D_\infty(p||q)$ equals $\log M(\theta)$ where $M(\theta)$ is the optimal value of the RS constant for a given proposal $q_\theta(x)$. This enables us to develop a \emph{two-stage} hybrid inference algorithm. Stage-1 performs RDVI to learn $q_\theta$ by minimizing an estimator of $D_\alpha(p||q)$, and uses the learned $q_\theta$ to find an (approximately) optimal $\tilde{M}(\theta)$. Stage-2 performs RS using the constant $\tilde{M}(\theta)$ to improve the approximate distribution $q_\theta$ and obtain a sample-based approximation. We prove that this two-stage method allows us to learn considerably more accurate approximations of the target distribution as compared to RDVI. We demonstrate our method's efficacy via several experiments on synthetic and real datasets.
Weakly Supervised Disentanglement with Guarantees
Oct 22, 2019


Learning disentangled representations that correspond to factors of variation in real-world data is critical to interpretable and human-controllable machine learning. Recently, concerns about the viability of learning disentangled representations in a purely unsupervised manner has spurred a shift toward the incorporation of weak supervision. However, there is currently no formalism that identifies when and how weak supervision will guarantee disentanglement. To address this issue, we provide a theoretical framework to assist in analyzing the disentanglement guarantees (or lack thereof) conferred by weak supervision when coupled with learning algorithms based on distribution matching. We empirically verify the guarantees and limitations of several weak supervision methods (restricted labeling, match-pairing, and rank-pairing), demonstrating the predictive power and usefulness of our theoretical framework.
A Scale Invariant Flatness Measure for Deep Network Minima
Feb 06, 2019
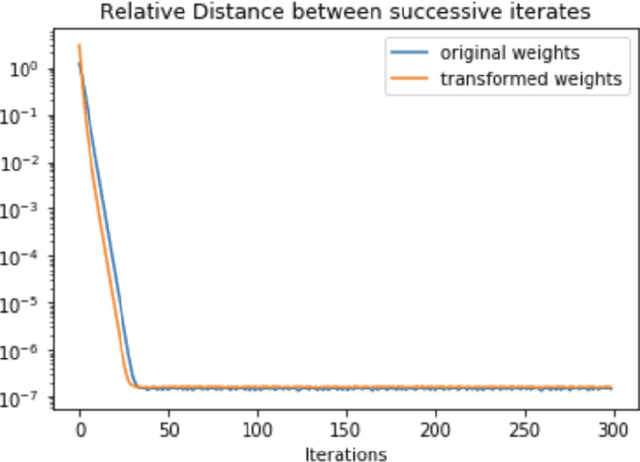
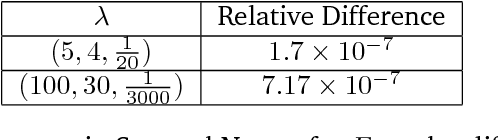
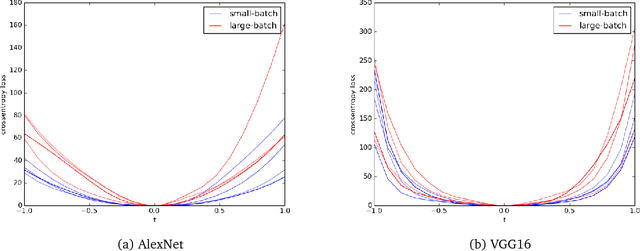
It has been empirically observed that the flatness of minima obtained from training deep networks seems to correlate with better generalization. However, for deep networks with positively homogeneous activations, most measures of sharpness/flatness are not invariant to rescaling of the network parameters, corresponding to the same function. This means that the measure of flatness/sharpness can be made as small or as large as possible through rescaling, rendering the quantitative measures meaningless. In this paper we show that for deep networks with positively homogenous activations, these rescalings constitute equivalence relations, and that these equivalence relations induce a quotient manifold structure in the parameter space. Using this manifold structure and an appropriate metric, we propose a Hessian-based measure for flatness that is invariant to rescaling. We use this new measure to confirm the proposition that Large-Batch SGD minima are indeed sharper than Small-Batch SGD minima.
Understanding Unequal Gender Classification Accuracy from Face Images
Nov 30, 2018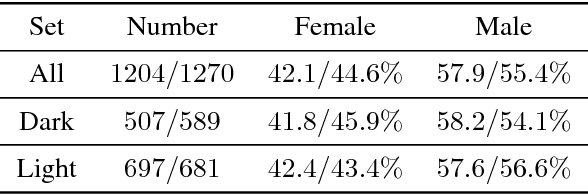
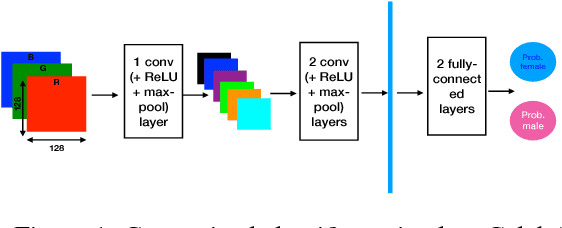
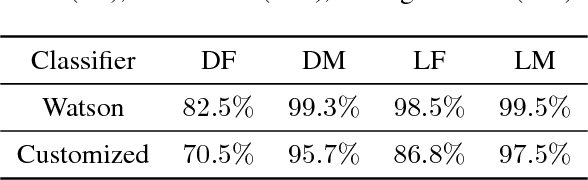
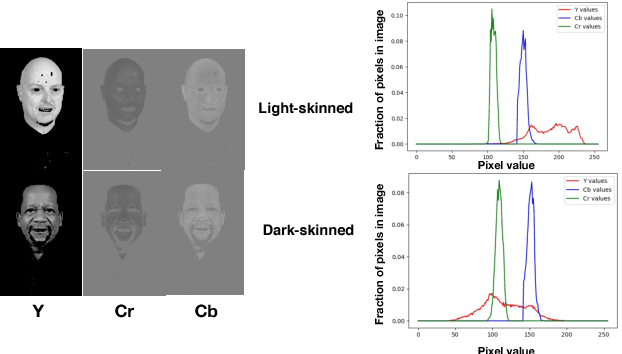
Recent work shows unequal performance of commercial face classification services in the gender classification task across intersectional groups defined by skin type and gender. Accuracy on dark-skinned females is significantly worse than on any other group. In this paper, we conduct several analyses to try to uncover the reason for this gap. The main finding, perhaps surprisingly, is that skin type is not the driver. This conclusion is reached via stability experiments that vary an image's skin type via color-theoretic methods, namely luminance mode-shift and optimal transport. A second suspect, hair length, is also shown not to be the driver via experiments on face images cropped to exclude the hair. Finally, using contrastive post-hoc explanation techniques for neural networks, we bring forth evidence suggesting that differences in lip, eye and cheek structure across ethnicity lead to the differences. Further, lip and eye makeup are seen as strong predictors for a female face, which is a troubling propagation of a gender stereotype.
SpotTune: Transfer Learning through Adaptive Fine-tuning
Nov 21, 2018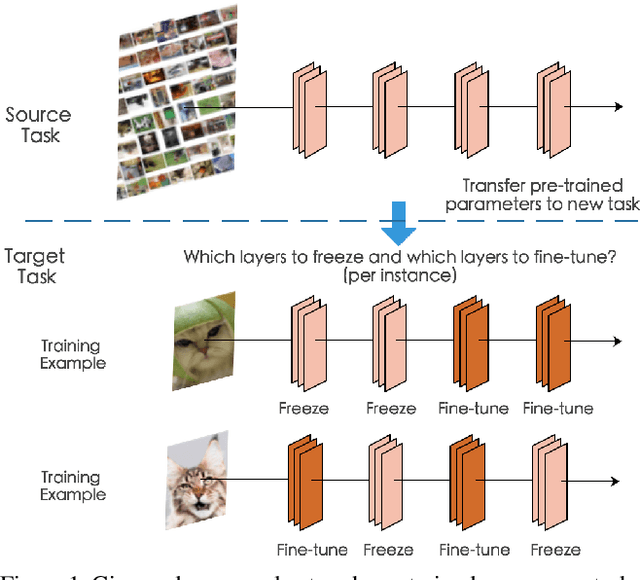
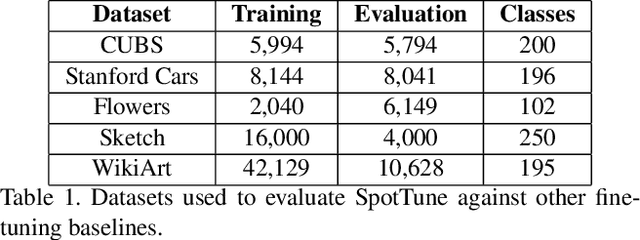
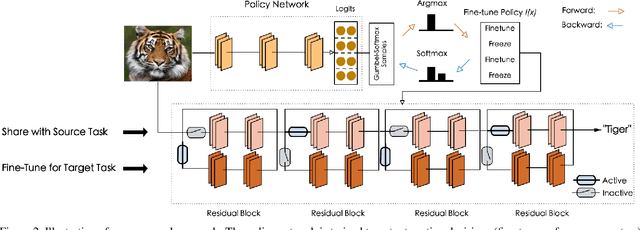
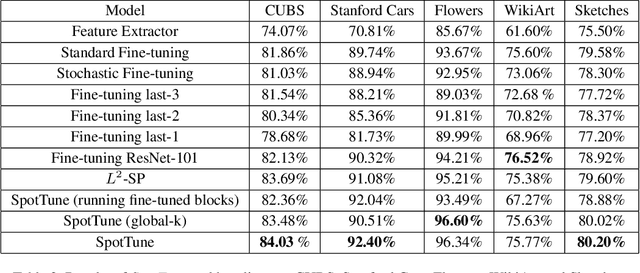
Transfer learning, which allows a source task to affect the inductive bias of the target task, is widely used in computer vision. The typical way of conducting transfer learning with deep neural networks is to fine-tune a model pre-trained on the source task using data from the target task. In this paper, we propose an adaptive fine-tuning approach, called SpotTune, which finds the optimal fine-tuning strategy per instance for the target data. In SpotTune, given an image from the target task, a policy network is used to make routing decisions on whether to pass the image through the fine-tuned layers or the pre-trained layers. We conduct extensive experiments to demonstrate the effectiveness of the proposed approach. Our method outperforms the traditional fine-tuning approach on 12 out of 14 standard datasets.We also compare SpotTune with other state-of-the-art fine-tuning strategies, showing superior performance. On the Visual Decathlon datasets, our method achieves the highest score across the board without bells and whistles.
MT-CGCNN: Integrating Crystal Graph Convolutional Neural Network with Multitask Learning for Material Property Prediction
Nov 14, 2018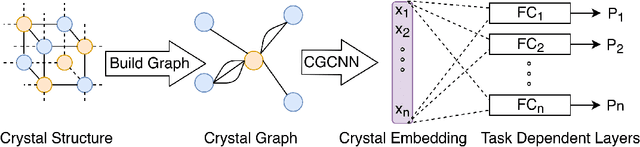

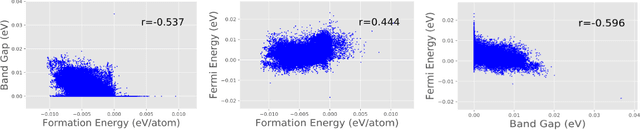
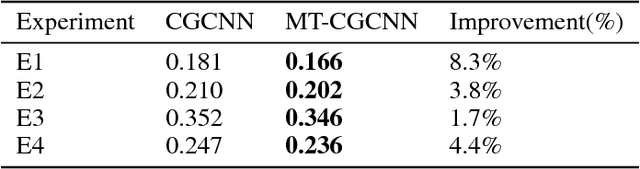
Developing accurate, transferable and computationally inexpensive machine learning models can rapidly accelerate the discovery and development of new materials. Some of the major challenges involved in developing such models are, (i) limited availability of materials data as compared to other fields, (ii) lack of universal descriptor of materials to predict its various properties. The limited availability of materials data can be addressed through transfer learning, while the generic representation was recently addressed by Xie and Grossman [1], where they developed a crystal graph convolutional neural network (CGCNN) that provides a unified representation of crystals. In this work, we develop a new model (MT-CGCNN) by integrating CGCNN with transfer learning based on multi-task (MT) learning. We demonstrate the effectiveness of MT-CGCNN by simultaneous prediction of various material properties such as Formation Energy, Band Gap and Fermi Energy for a wide range of inorganic crystals (46774 materials). MT-CGCNN is able to reduce the test error when employed on correlated properties by upto 8%. The model prediction has lower test error compared to CGCNN, even when the training data is reduced by 10%. We also demonstrate our model's better performance through prediction of end user scenario related to metal/non-metal classification. These results encourage further development of machine learning approaches which leverage multi-task learning to address the aforementioned challenges in the discovery of new materials. We make MT-CGCNN's source code available to encourage reproducible research.
Co-regularized Alignment for Unsupervised Domain Adaptation
Nov 13, 2018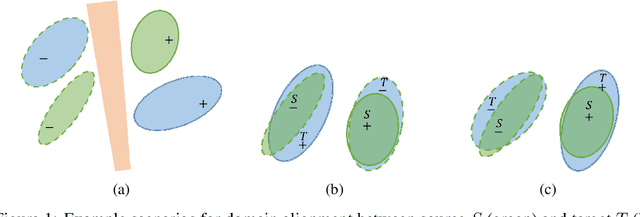
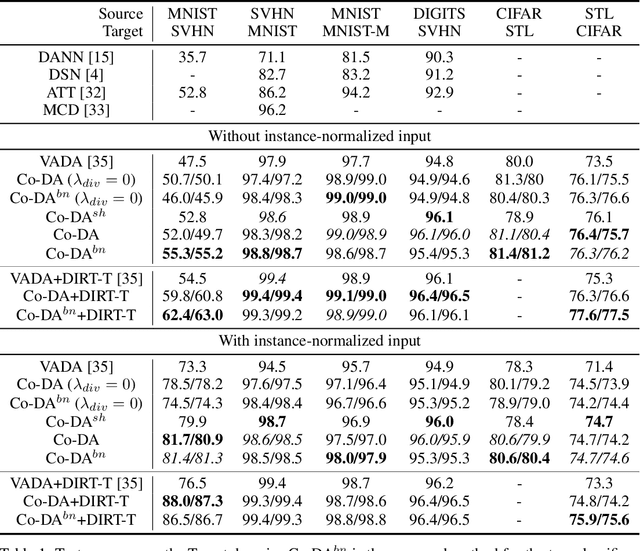
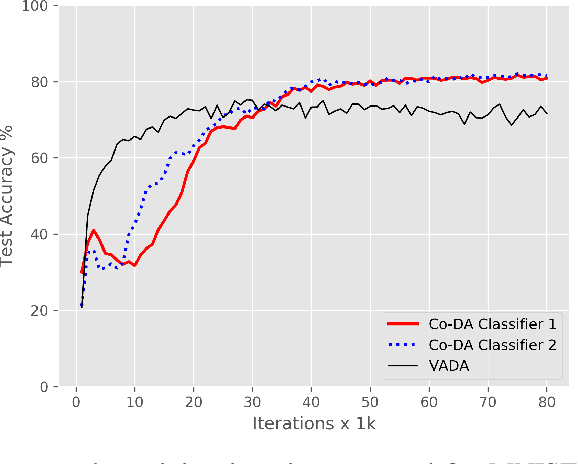
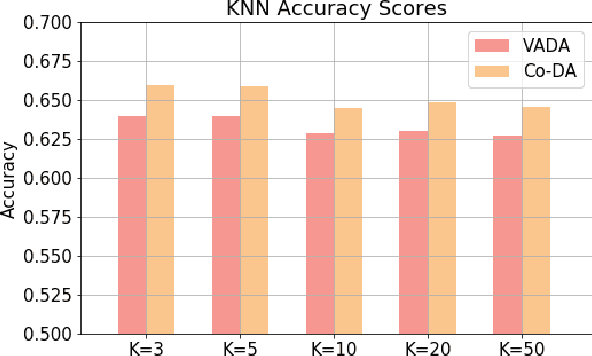
Deep neural networks, trained with large amount of labeled data, can fail to generalize well when tested with examples from a \emph{target domain} whose distribution differs from the training data distribution, referred as the \emph{source domain}. It can be expensive or even infeasible to obtain required amount of labeled data in all possible domains. Unsupervised domain adaptation sets out to address this problem, aiming to learn a good predictive model for the target domain using labeled examples from the source domain but only unlabeled examples from the target domain. Domain alignment approaches this problem by matching the source and target feature distributions, and has been used as a key component in many state-of-the-art domain adaptation methods. However, matching the marginal feature distributions does not guarantee that the corresponding class conditional distributions will be aligned across the two domains. We propose co-regularized domain alignment for unsupervised domain adaptation, which constructs multiple diverse feature spaces and aligns source and target distributions in each of them individually, while encouraging that alignments agree with each other with regard to the class predictions on the unlabeled target examples. The proposed method is generic and can be used to improve any domain adaptation method which uses domain alignment. We instantiate it in the context of a recent state-of-the-art method and observe that it provides significant performance improvements on several domain adaptation benchmarks.
Knowledge-enriched Two-layered Attention Network for Sentiment Analysis
Jun 16, 2018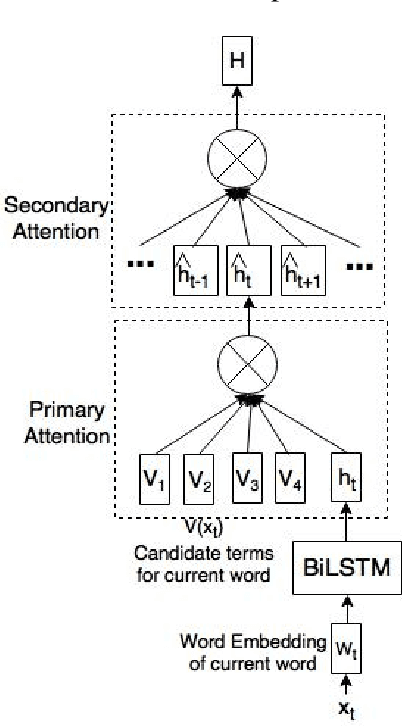
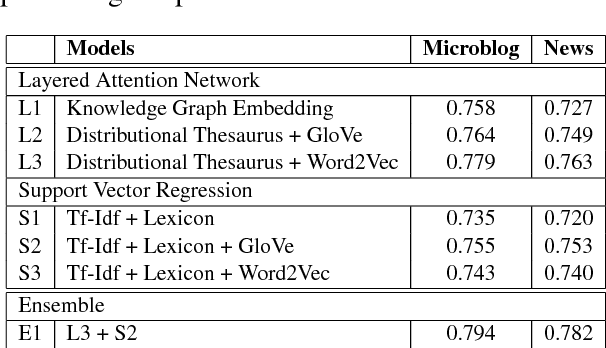
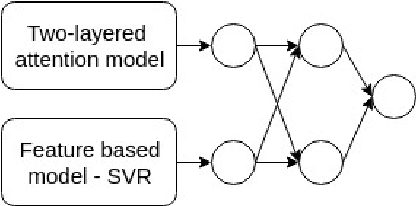
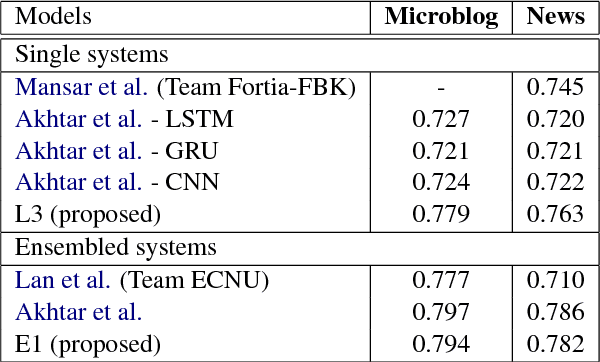
We propose a novel two-layered attention network based on Bidirectional Long Short-Term Memory for sentiment analysis. The novel two-layered attention network takes advantage of the external knowledge bases to improve the sentiment prediction. It uses the Knowledge Graph Embedding generated using the WordNet. We build our model by combining the two-layered attention network with the supervised model based on Support Vector Regression using a Multilayer Perceptron network for sentiment analysis. We evaluate our model on the benchmark dataset of SemEval 2017 Task 5. Experimental results show that the proposed model surpasses the top system of SemEval 2017 Task 5. The model performs significantly better by improving the state-of-the-art system at SemEval 2017 Task 5 by 1.7 and 3.7 points for sub-tracks 1 and 2 respectively.
RepMet: Representative-based metric learning for classification and one-shot object detection
Jun 15, 2018
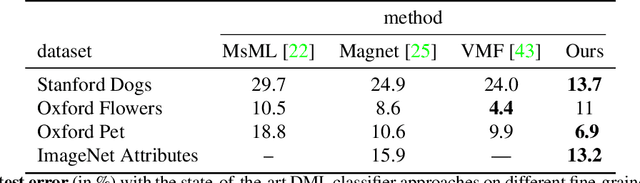
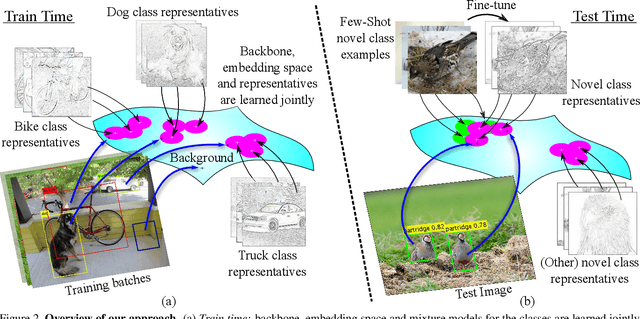
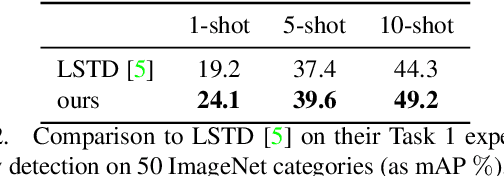
Distance metric learning (DML) has been successfully applied to object classification, both in the standard regime of rich training data and in the few-shot scenario, where each category is represented by only few examples. In this work, we propose a new method for DML, featuring a joint learning of the embedding space and of the data distribution of the training categories, in a single training process. Our method improves upon leading algorithms for DML-based object classification. Furthermore, it opens the door for a new task in Computer Vision - a few-shot object detection, since the proposed DML architecture can be naturally embedded as the classification head of any standard object detector. In numerous experiments, we achieve state-of-the-art classification results on a variety of fine-grained datasets, and offer the community a benchmark on the few-shot detection task, performed on the Imagenet-LOC dataset. The code will be made available upon acceptance.
Delta-encoder: an effective sample synthesis method for few-shot object recognition
Jun 12, 2018
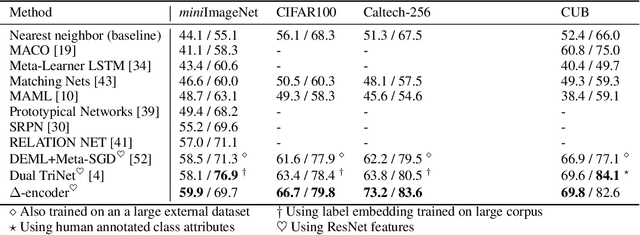
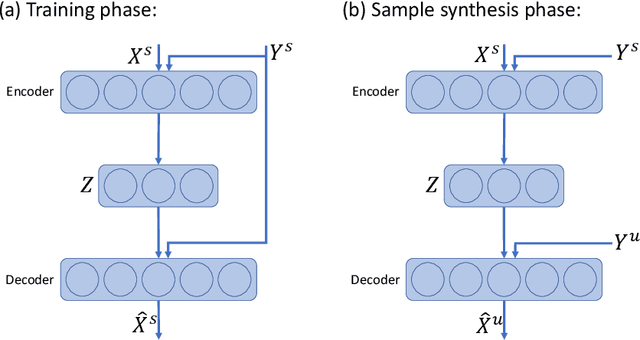

Learning to classify new categories based on just one or a few examples is a long-standing challenge in modern computer vision. In this work, we proposes a simple yet effective method for few-shot (and one-shot) object recognition. Our approach is based on a modified auto-encoder, denoted Delta-encoder, that learns to synthesize new samples for an unseen category just by seeing few examples from it. The synthesized samples are then used to train a classifier. The proposed approach learns to both extract transferable intra-class deformations, or "deltas", between same-class pairs of training examples, and to apply those deltas to the few provided examples of a novel class (unseen during training) in order to efficiently synthesize samples from that new class. The proposed method improves over the state-of-the-art in one-shot object-recognition and compares favorably in the few-shot case. Upon acceptance code will be made available.