 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombating Reinforcement Learning's Sisyphean Curse with Intrinsic Fear
Paper and Code
Mar 13, 2018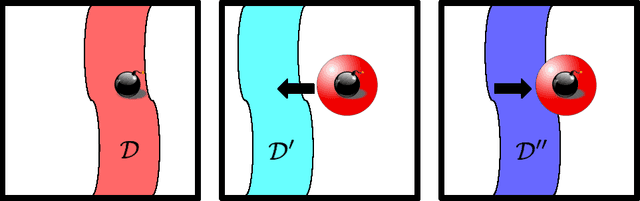
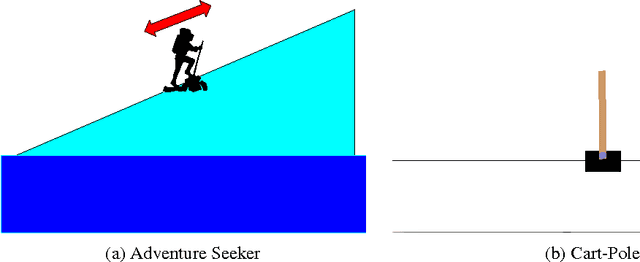
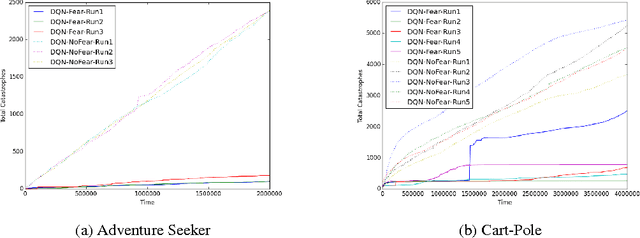
Many practical environments contain catastrophic states that an optimal agent would visit infrequently or never. Even on toy problems, Deep Reinforcement Learning (DRL) agents tend to periodically revisit these states upon forgetting their existence under a new policy. We introduce intrinsic fear (IF), a learned reward shaping that guards DRL agents against periodic catastrophes. IF agents possess a fear model trained to predict the probability of imminent catastrophe. This score is then used to penalize the Q-learning objective. Our theoretical analysis bounds the reduction in average return due to learning on the perturbed objective. We also prove robustness to classification errors. As a bonus, IF models tend to learn faster, owing to reward shaping. Experiments demonstrate that intrinsic-fear DQNs solve otherwise pathological environments and improve on several Atari games.