 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Images to 3D Shape Attributes
Dec 03, 2017
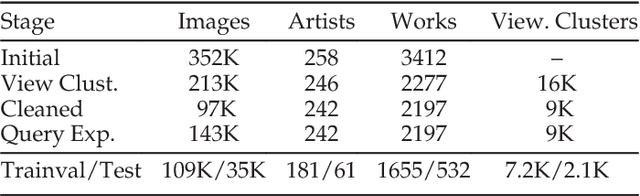

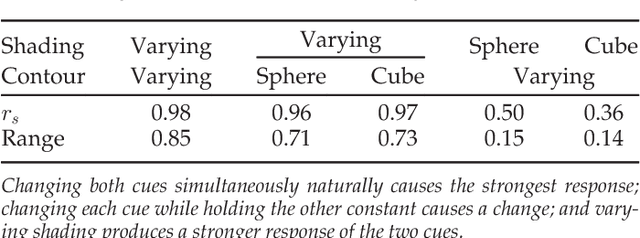
Our goal in this paper is to investigate properties of 3D shape that can be determined from a single image. We define 3D shape attributes -- generic properties of the shape that capture curvature, contact and occupied space. Our first objective is to infer these 3D shape attributes from a single image. A second objective is to infer a 3D shape embedding -- a low dimensional vector representing the 3D shape. We study how the 3D shape attributes and embedding can be obtained from a single image by training a Convolutional Neural Network (CNN) for this task. We start with synthetic images so that the contribution of various cues and nuisance parameters can be controlled. We then turn to real images and introduce a large scale image dataset of sculptures containing 143K images covering 2197 works from 242 artists. For the CNN trained on the sculpture dataset we show the following: (i) which regions of the imaged sculpture are used by the CNN to infer the 3D shape attributes; (ii) that the shape embedding can be used to match previously unseen sculptures largely independent of viewpoint; and (iii) that the 3D attributes generalize to images of other (non-sculpture) object classes.
Sentiment Classification using Images and Label Embeddings
Dec 03, 2017

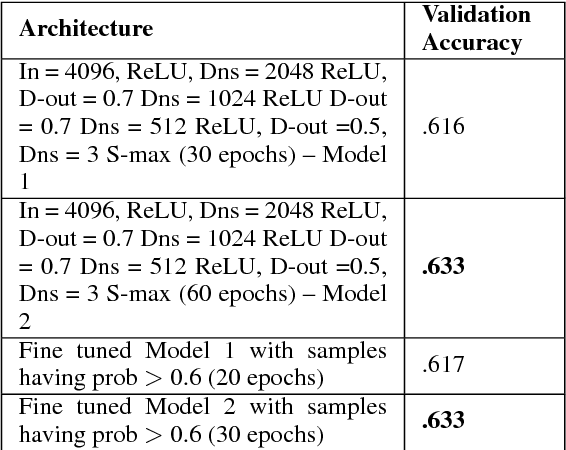
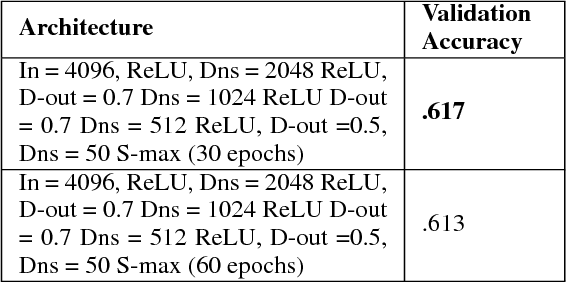
In this project we analysed how much semantic information images carry, and how much value image data can add to sentiment analysis of the text associated with the images. To better understand the contribution from images, we compared models which only made use of image data, models which only made use of text data, and models which combined both data types. We also analysed if this approach could help sentiment classifiers generalize to unknown sentiments.
Visual Features for Context-Aware Speech Recognition
Dec 01, 2017
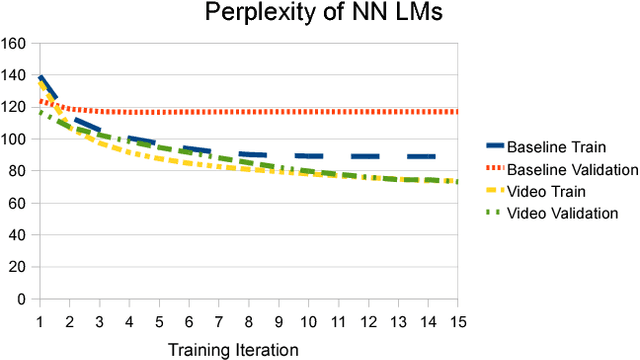

Automatic transcriptions of consumer-generated multi-media content such as "Youtube" videos still exhibit high word error rates. Such data typically occupies a very broad domain, has been recorded in challenging conditions, with cheap hardware and a focus on the visual modality, and may have been post-processed or edited. In this paper, we extend our earlier work on adapting the acoustic model of a DNN-based speech recognition system to an RNN language model and show how both can be adapted to the objects and scenes that can be automatically detected in the video. We are working on a corpus of "how-to" videos from the web, and the idea is that an object that can be seen ("car"), or a scene that is being detected ("kitchen") can be used to condition both models on the "context" of the recording, thereby reducing perplexity and improving transcription. We achieve good improvements in both cases and compare and analyze the respective reductions in word error rate. We expect that our results can be used for any type of speech processing in which "context" information is available, for example in robotics, man-machine interaction, or when indexing large audio-visual archives, and should ultimately help to bring together the "video-to-text" and "speech-to-text" communities.
* 5 pages and 3 figures
Beyond Skip Connections: Top-Down Modulation for Object Detection
Sep 19, 2017

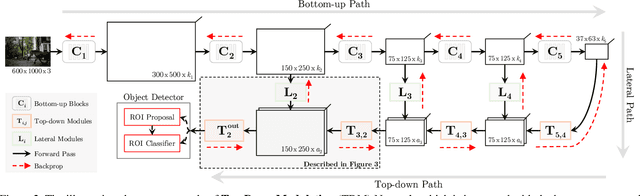
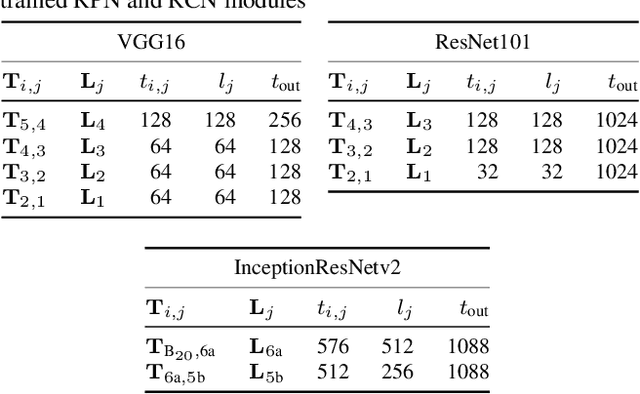
In recent years, we have seen tremendous progress in the field of object detection. Most of the recent improvements have been achieved by targeting deeper feedforward networks. However, many hard object categories such as bottle, remote, etc. require representation of fine details and not just coarse, semantic representations. But most of these fine details are lost in the early convolutional layers. What we need is a way to incorporate finer details from lower layers into the detection architecture. Skip connections have been proposed to combine high-level and low-level features, but we argue that selecting the right features from low-level requires top-down contextual information. Inspired by the human visual pathway, in this paper we propose top-down modulations as a way to incorporate fine details into the detection framework. Our approach supplements the standard bottom-up, feedforward ConvNet with a top-down modulation (TDM) network, connected using lateral connections. These connections are responsible for the modulation of lower layer filters, and the top-down network handles the selection and integration of contextual information and low-level features. The proposed TDM architecture provides a significant boost on the COCO testdev benchmark, achieving 28.6 AP for VGG16, 35.2 AP for ResNet101, and 37.3 for InceptionResNetv2 network, without any bells and whistles (e.g., multi-scale, iterative box refinement, etc.).
Visual Semantic Planning using Deep Successor Representations
Aug 15, 2017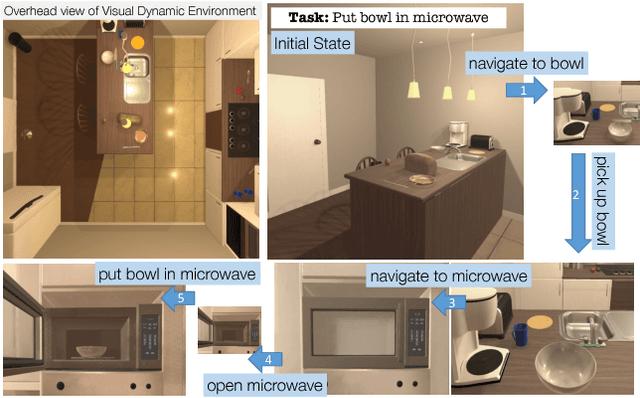
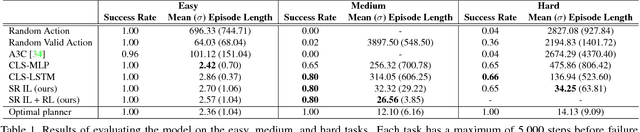

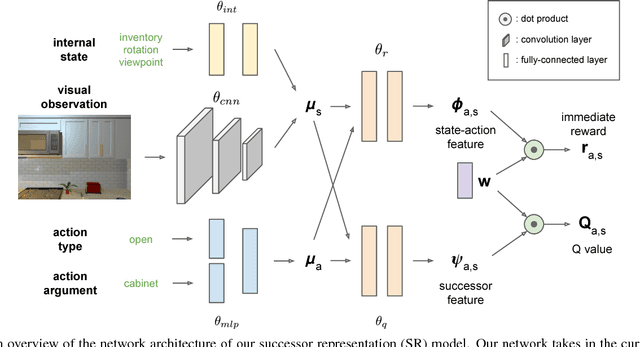
A crucial capability of real-world intelligent agents is their ability to plan a sequence of actions to achieve their goals in the visual world. In this work, we address the problem of visual semantic planning: the task of predicting a sequence of actions from visual observations that transform a dynamic environment from an initial state to a goal state. Doing so entails knowledge about objects and their affordances, as well as actions and their preconditions and effects. We propose learning these through interacting with a visual and dynamic environment. Our proposed solution involves bootstrapping reinforcement learning with imitation learning. To ensure cross task generalization, we develop a deep predictive model based on successor representations. Our experimental results show near optimal results across a wide range of tasks in the challenging THOR environment.
Transitive Invariance for Self-supervised Visual Representation Learning
Aug 15, 2017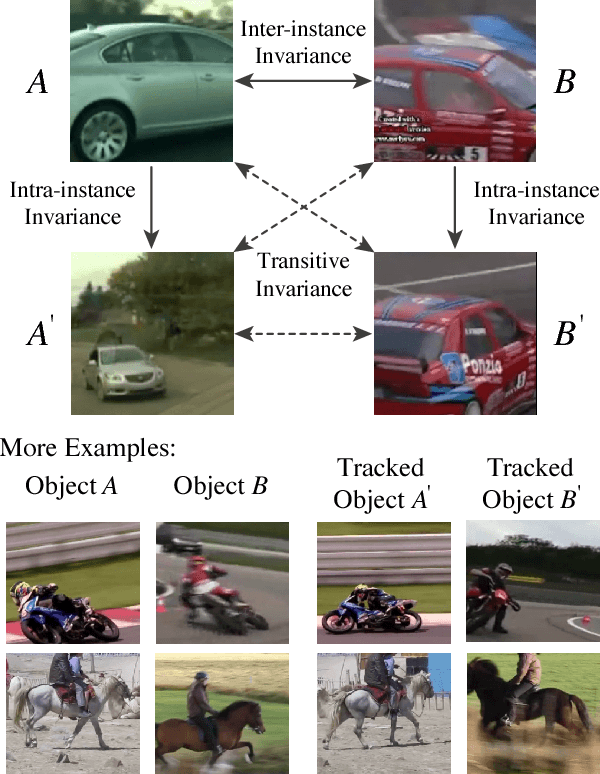

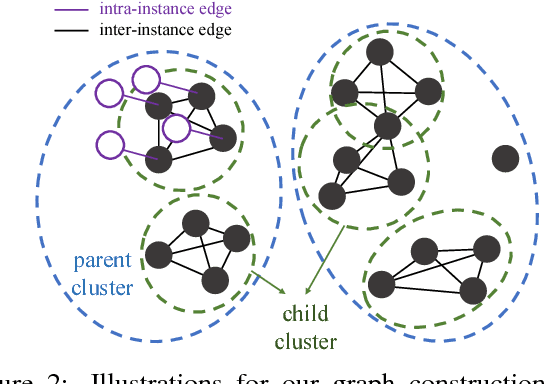

Learning visual representations with self-supervised learning has become popular in computer vision. The idea is to design auxiliary tasks where labels are free to obtain. Most of these tasks end up providing data to learn specific kinds of invariance useful for recognition. In this paper, we propose to exploit different self-supervised approaches to learn representations invariant to (i) inter-instance variations (two objects in the same class should have similar features) and (ii) intra-instance variations (viewpoint, pose, deformations, illumination, etc). Instead of combining two approaches with multi-task learning, we argue to organize and reason the data with multiple variations. Specifically, we propose to generate a graph with millions of objects mined from hundreds of thousands of videos. The objects are connected by two types of edges which correspond to two types of invariance: "different instances but a similar viewpoint and category" and "different viewpoints of the same instance". By applying simple transitivity on the graph with these edges, we can obtain pairs of images exhibiting richer visual invariance. We use this data to train a Triplet-Siamese network with VGG16 as the base architecture and apply the learned representations to different recognition tasks. For object detection, we achieve 63.2% mAP on PASCAL VOC 2007 using Fast R-CNN (compare to 67.3% with ImageNet pre-training). For the challenging COCO dataset, our method is surprisingly close (23.5%) to the ImageNet-supervised counterpart (24.4%) using the Faster R-CNN framework. We also show that our network can perform significantly better than the ImageNet network in the surface normal estimation task.
What Actions are Needed for Understanding Human Actions in Videos?
Aug 09, 2017

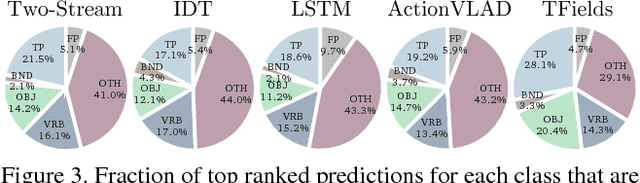
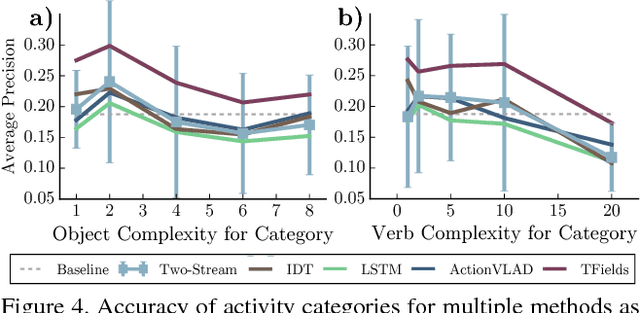
What is the right way to reason about human activities? What directions forward are most promising? In this work, we analyze the current state of human activity understanding in videos. The goal of this paper is to examine datasets, evaluation metrics, algorithms, and potential future directions. We look at the qualitative attributes that define activities such as pose variability, brevity, and density. The experiments consider multiple state-of-the-art algorithms and multiple datasets. The results demonstrate that while there is inherent ambiguity in the temporal extent of activities, current datasets still permit effective benchmarking. We discover that fine-grained understanding of objects and pose when combined with temporal reasoning is likely to yield substantial improvements in algorithmic accuracy. We present the many kinds of information that will be needed to achieve substantial gains in activity understanding: objects, verbs, intent, and sequential reasoning. The software and additional information will be made available to provide other researchers detailed diagnostics to understand their own algorithms.
Revisiting Unreasonable Effectiveness of Data in Deep Learning Era
Aug 04, 2017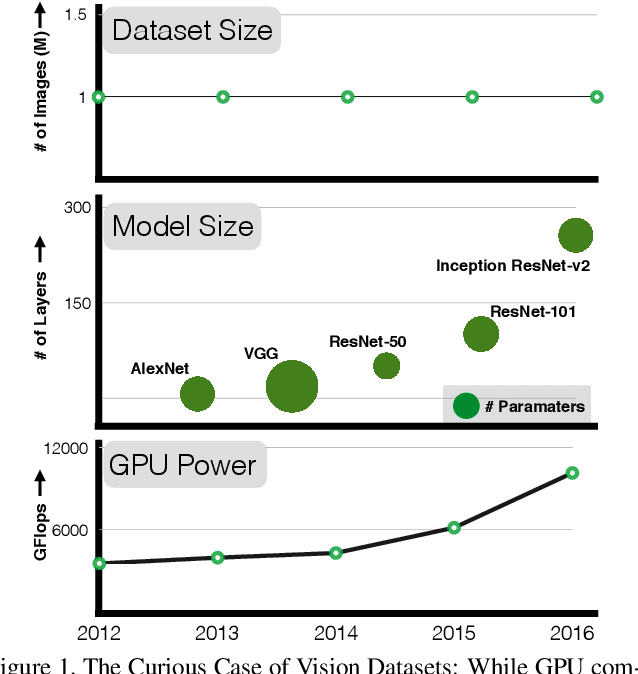
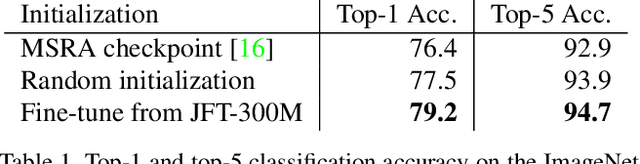
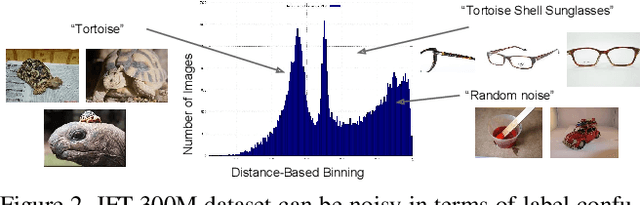
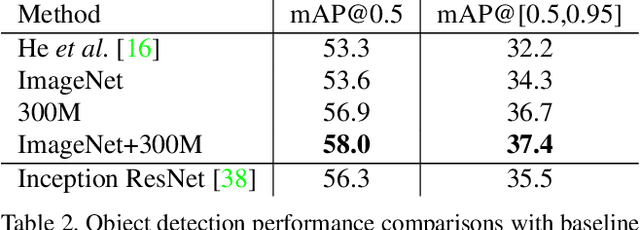
The success of deep learning in vision can be attributed to: (a) models with high capacity; (b) increased computational power; and (c) availability of large-scale labeled data. Since 2012, there have been significant advances in representation capabilities of the models and computational capabilities of GPUs. But the size of the biggest dataset has surprisingly remained constant. What will happen if we increase the dataset size by 10x or 100x? This paper takes a step towards clearing the clouds of mystery surrounding the relationship between `enormous data' and visual deep learning. By exploiting the JFT-300M dataset which has more than 375M noisy labels for 300M images, we investigate how the performance of current vision tasks would change if this data was used for representation learning. Our paper delivers some surprising (and some expected) findings. First, we find that the performance on vision tasks increases logarithmically based on volume of training data size. Second, we show that representation learning (or pre-training) still holds a lot of promise. One can improve performance on many vision tasks by just training a better base model. Finally, as expected, we present new state-of-the-art results for different vision tasks including image classification, object detection, semantic segmentation and human pose estimation. Our sincere hope is that this inspires vision community to not undervalue the data and develop collective efforts in building larger datasets.
Combining Keystroke Dynamics and Face Recognition for User Verification
Aug 02, 2017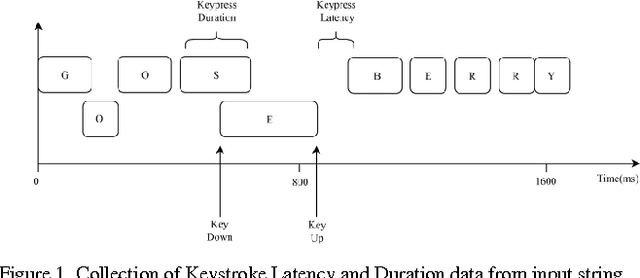

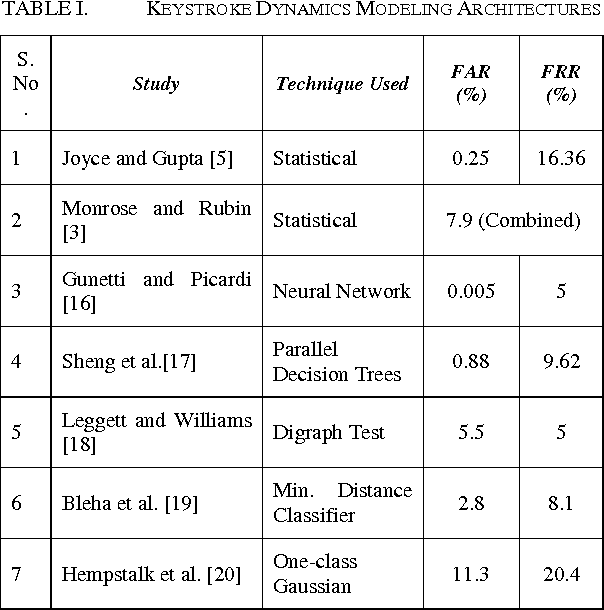
The massive explosion and ubiquity of computing devices and the outreach of the web have been the most defining events of the century so far. As more and more people gain access to the internet, traditional know-something and have-something authentication methods such as PINs and passwords are proving to be insufficient for prohibiting unauthorized access to increasingly personal data on the web. Therefore, the need of the hour is a user-verification system that is not only more reliable and secure, but also unobtrusive and minimalistic. Keystroke Dynamics is a novel Biometric Technique; it is not only unobtrusive, but also transparent and inexpensive. The fusion of keystroke dynamics and Face Recognition engenders the most desirable characteristics of a verification system. Our implementation uses Hidden Markov Models (HMM) for modelling the Keystroke Dynamics, with the help of two widely used Feature Vectors: Keypress Latency and Keypress Duration. On the other hand, Face Recognition makes use of the traditional Eigenfaces approach.The results show that the system has a high precision, with a False Acceptance Rate of 5.4% and a False Rejection Rate of 9.2%. Moreover, it is also future-proof, as the hardware requirements, i.e. camera and keyboard (physical or on-screen), have become an indispensable part of modern computing.
Temporal Dynamic Graph LSTM for Action-driven Video Object Detection
Aug 02, 2017

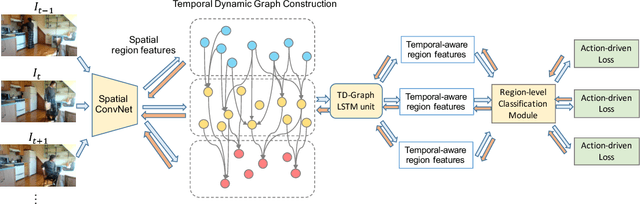
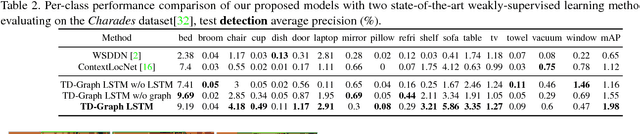
In this paper, we investigate a weakly-supervised object detection framework. Most existing frameworks focus on using static images to learn object detectors. However, these detectors often fail to generalize to videos because of the existing domain shift. Therefore, we investigate learning these detectors directly from boring videos of daily activities. Instead of using bounding boxes, we explore the use of action descriptions as supervision since they are relatively easy to gather. A common issue, however, is that objects of interest that are not involved in human actions are often absent in global action descriptions known as "missing label". To tackle this problem, we propose a novel temporal dynamic graph Long Short-Term Memory network (TD-Graph LSTM). TD-Graph LSTM enables global temporal reasoning by constructing a dynamic graph that is based on temporal correlations of object proposals and spans the entire video. The missing label issue for each individual frame can thus be significantly alleviated by transferring knowledge across correlated objects proposals in the whole video. Extensive evaluations on a large-scale daily-life action dataset (i.e., Charades) demonstrates the superiority of our proposed method. We also release object bounding-box annotations for more than 5,000 frames in Charades. We believe this annotated data can also benefit other research on video-based object recognition in the future.