 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Unsupervised Domain Adaptation for Speech Recognition via Uncertainty Driven Self-Training
Nov 26, 2020
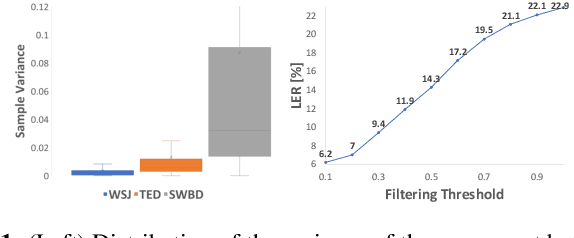
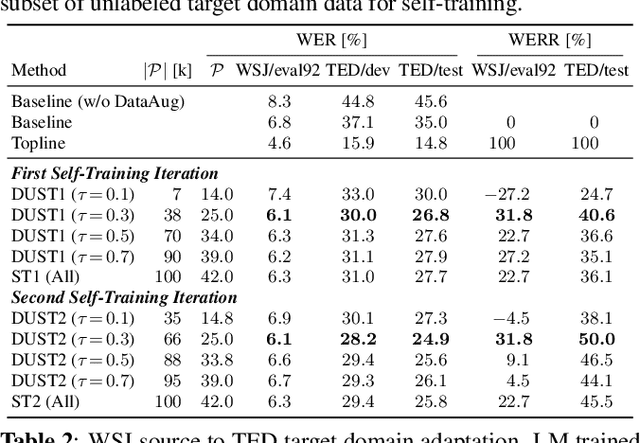
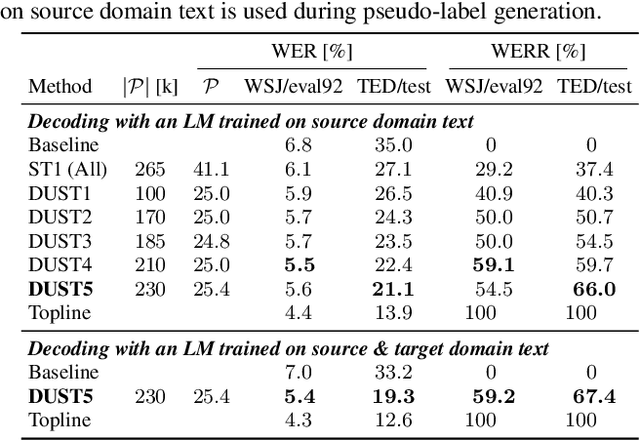
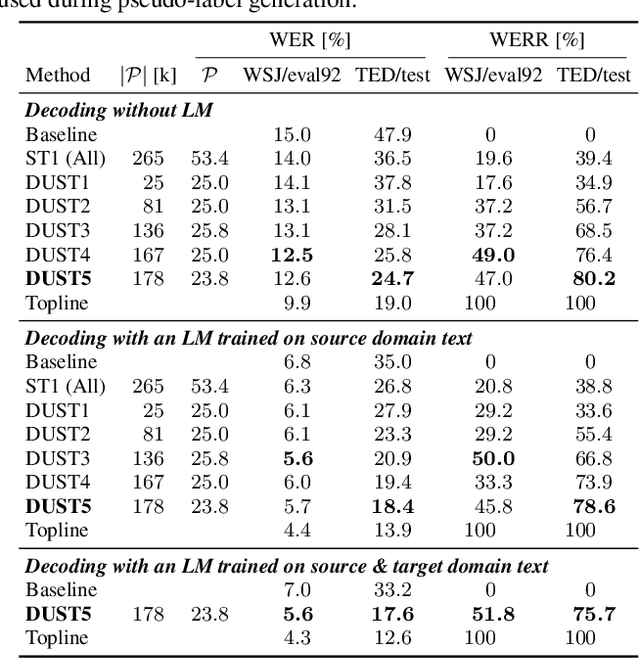
The performance of automatic speech recognition (ASR) systems typically degrades significantly when the training and test data domains are mismatched. In this paper, we show that self-training (ST) combined with an uncertainty-based pseudo-label filtering approach can be effectively used for domain adaptation. We propose DUST, a dropout-based uncertainty-driven self-training technique which uses agreement between multiple predictions of an ASR system obtained for different dropout settings to measure the model's uncertainty about its prediction. DUST excludes pseudo-labeled data with high uncertainties from the training, which leads to substantially improved ASR results compared to ST without filtering, and accelerates the training time due to a reduced training data set. Domain adaptation experiments using WSJ as a source domain and TED-LIUM 3 as well as SWITCHBOARD as the target domains show that up to 80% of the performance of a system trained on ground-truth data can be recovered.
Direction of Arrival Estimation of Noisy Speech Using Convolutional Recurrent Neural Networks with Higher-Order Ambisonics Signals
Feb 19, 2021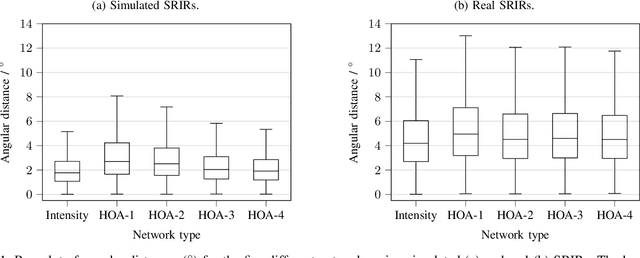
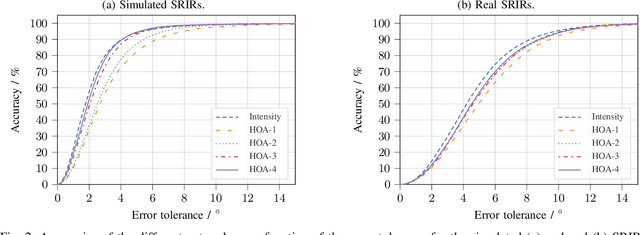
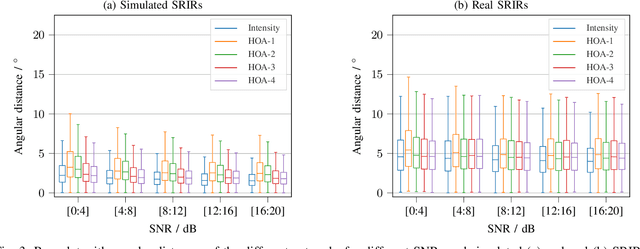
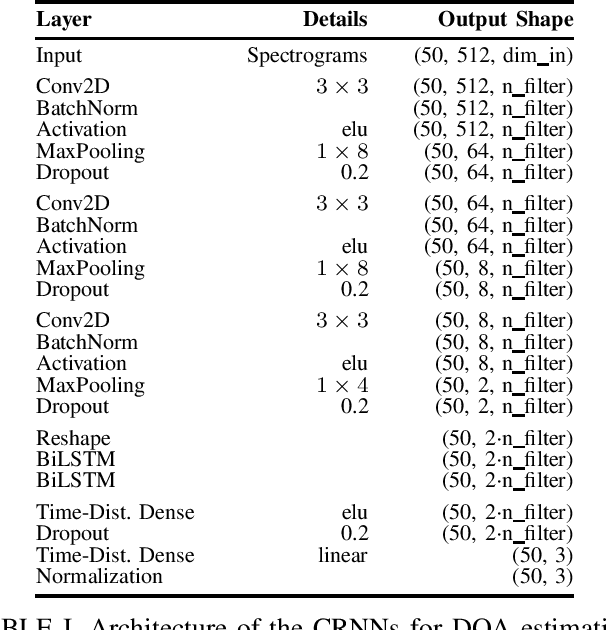
Training convolutional recurrent neural networks (CRNNs) on first-order Ambisonics signals is a well-known approach for estimating the direction of speech/sound arrival. In this work, we investigate whether increasing the order of Ambisonics signals up to the fourth order further improves the estimation performance of CRNNs. While our results on data based on simulated spatial room impulse responses (SRIRs) show that the use of higher Ambisonics orders does have the potential to provide better localization results, no further improvement was shown on data based on real SRIRs from order two onwards. Rather, it seems to be crucial to extract meaningful features from the raw data. First order features derived from the acoustic intensity vector were superior to pure higher-order magnitude and phase features in almost all scenarios.
North America Bixby Speaker Diarization System for the VoxCeleb Speaker Recognition Challenge 2021
Sep 28, 2021
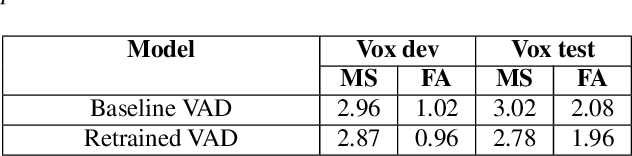
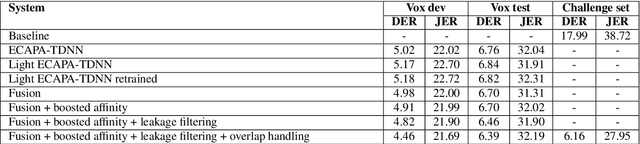
This paper describes the submission to the speaker diarization track of VoxCeleb Speaker Recognition Challenge 2021 done by North America Bixby Lab of Samsung Research America. Our speaker diarization system consists of four main components such as overlap speech detection and speech separation, robust speaker embedding extraction, spectral clustering with fused affinity matrix, and leakage filtering-based postprocessing. We evaluated our system on the VoxConverse dataset and the challenge evaluation set, which contain natural conversations of multiple talkers collected from YouTube. Our system obtained 4.46%, 6.39%, and 6.16% of the diarization error rate on the VoxConverse development, test, and the challenge evaluation set, respectively.
StarGANv2-VC: A Diverse, Unsupervised, Non-parallel Framework for Natural-Sounding Voice Conversion
Jul 21, 2021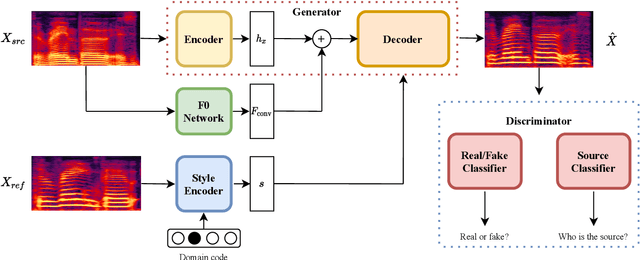
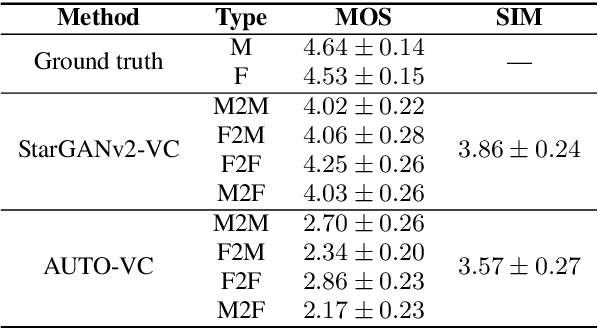
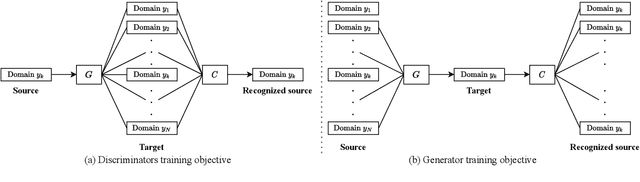
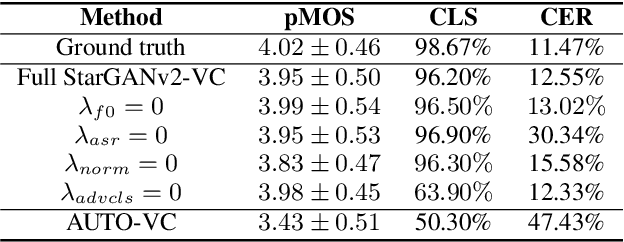
We present an unsupervised non-parallel many-to-many voice conversion (VC) method using a generative adversarial network (GAN) called StarGAN v2. Using a combination of adversarial source classifier loss and perceptual loss, our model significantly outperforms previous VC models. Although our model is trained only with 20 English speakers, it generalizes to a variety of voice conversion tasks, such as any-to-many, cross-lingual, and singing conversion. Using a style encoder, our framework can also convert plain reading speech into stylistic speech, such as emotional and falsetto speech. Subjective and objective evaluation experiments on a non-parallel many-to-many voice conversion task revealed that our model produces natural sounding voices, close to the sound quality of state-of-the-art text-to-speech (TTS) based voice conversion methods without the need for text labels. Moreover, our model is completely convolutional and with a faster-than-real-time vocoder such as Parallel WaveGAN can perform real-time voice conversion.
Generating Human Readable Transcript for Automatic Speech Recognition with Pre-trained Language Model
Feb 22, 2021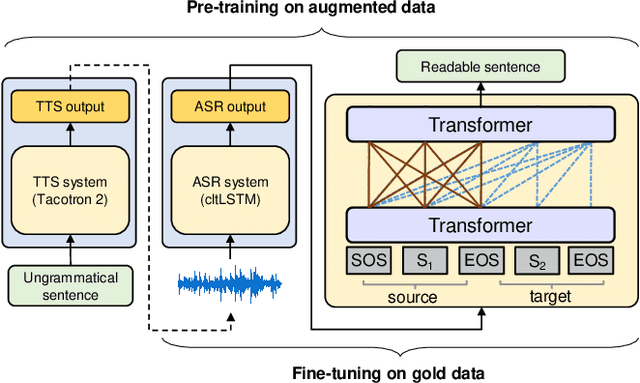
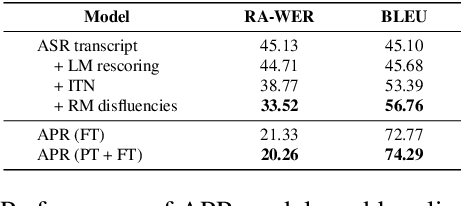

Modern Automatic Speech Recognition (ASR) systems can achieve high performance in terms of recognition accuracy. However, a perfectly accurate transcript still can be challenging to read due to disfluency, filter words, and other errata common in spoken communication. Many downstream tasks and human readers rely on the output of the ASR system; therefore, errors introduced by the speaker and ASR system alike will be propagated to the next task in the pipeline. In this work, we propose an ASR post-processing model that aims to transform the incorrect and noisy ASR output into a readable text for humans and downstream tasks. We leverage the Metadata Extraction (MDE) corpus to construct a task-specific dataset for our study. Since the dataset is small, we propose a novel data augmentation method and use a two-stage training strategy to fine-tune the RoBERTa pre-trained model. On the constructed test set, our model outperforms a production two-step pipeline-based post-processing method by a large margin of 13.26 on readability-aware WER (RA-WER) and 17.53 on BLEU metrics. Human evaluation also demonstrates that our method can generate more human-readable transcripts than the baseline method.
A Further Study of Unsupervised Pre-training for Transformer Based Speech Recognition
May 20, 2020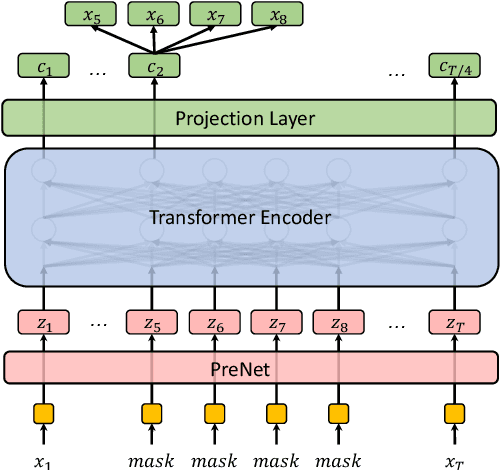

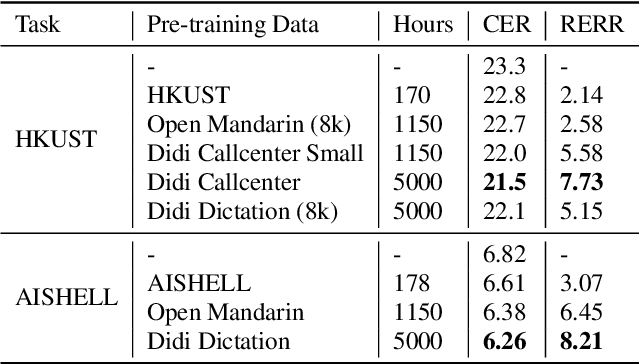
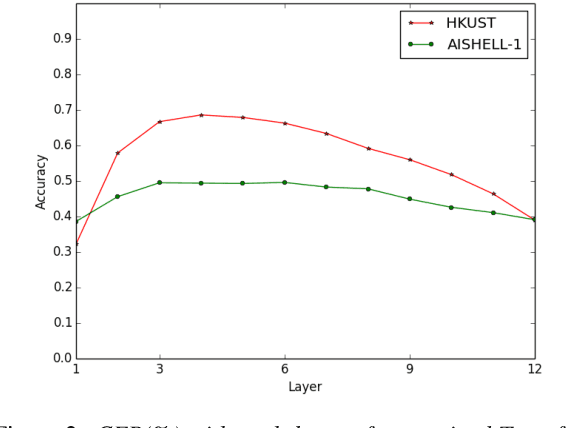
Building a good speech recognition system usually requires large amounts of transcribed data, which is expensive to collect. To tackle this problem, many unsupervised pre-training methods have been proposed. Among these methods, Masked Predictive Coding achieved significant improvements on various speech recognition datasets with BERT-like Masked Reconstruction loss and Transformer backbone. However, many aspects of MPC have not been fully investigated. In this paper, we conduct a further study on MPC and focus on three important aspects: the effect of pre-training data speaking style, its extension on streaming model, and how to better transfer learned knowledge from pre-training stage to downstream tasks. Experiments reveled that pre-training data with matching speaking style is more useful on downstream recognition tasks. A unified training objective with APC and MPC provided 8.46% relative error reduction on streaming model trained on HKUST. Also, the combination of target data adaption and layer-wise discriminative training helped the knowledge transfer of MPC, which achieved 3.99% relative error reduction on AISHELL over a strong baseline.
Towards speech-to-text translation without speech recognition
Feb 13, 2017
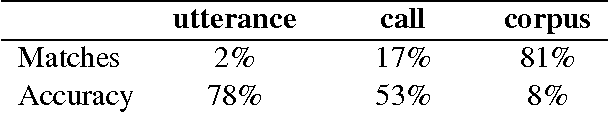

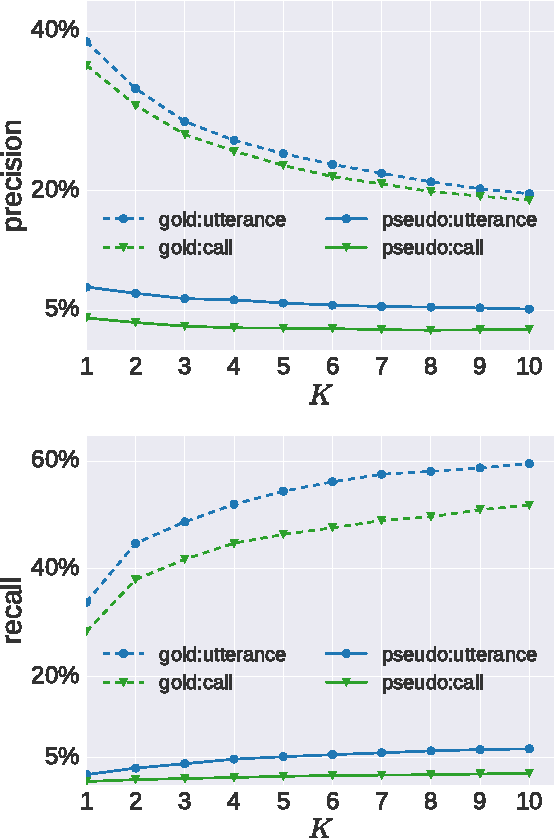
We explore the problem of translating speech to text in low-resource scenarios where neither automatic speech recognition (ASR) nor machine translation (MT) are available, but we have training data in the form of audio paired with text translations. We present the first system for this problem applied to a realistic multi-speaker dataset, the CALLHOME Spanish-English speech translation corpus. Our approach uses unsupervised term discovery (UTD) to cluster repeated patterns in the audio, creating a pseudotext, which we pair with translations to create a parallel text and train a simple bag-of-words MT model. We identify the challenges faced by the system, finding that the difficulty of cross-speaker UTD results in low recall, but that our system is still able to correctly translate some content words in test data.
ADIMA: Abuse Detection In Multilingual Audio
Feb 16, 2022
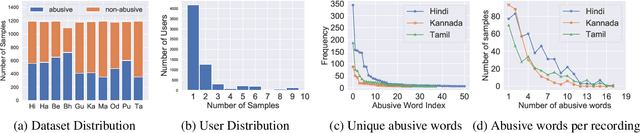
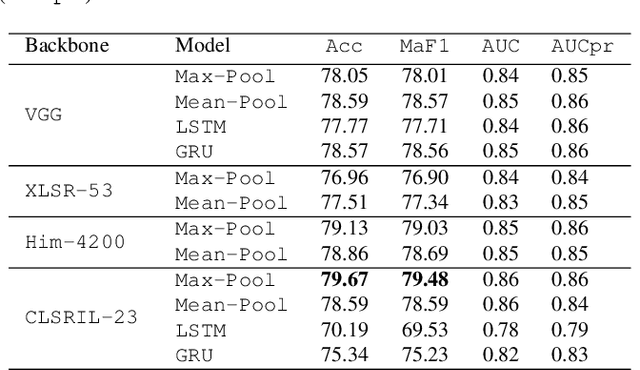
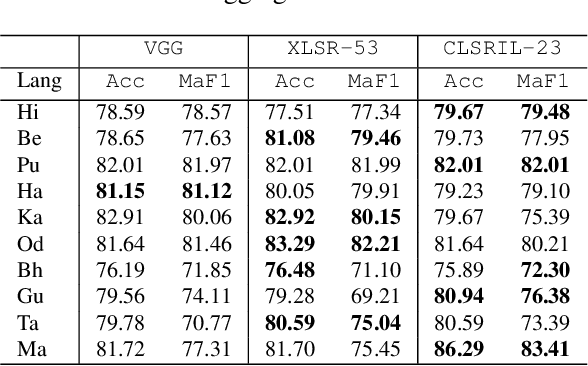
Abusive content detection in spoken text can be addressed by performing Automatic Speech Recognition (ASR) and leveraging advancements in natural language processing. However, ASR models introduce latency and often perform sub-optimally for profane words as they are underrepresented in training corpora and not spoken clearly or completely. Exploration of this problem entirely in the audio domain has largely been limited by the lack of audio datasets. Building on these challenges, we propose ADIMA, a novel, linguistically diverse, ethically sourced, expert annotated and well-balanced multilingual profanity detection audio dataset comprising of 11,775 audio samples in 10 Indic languages spanning 65 hours and spoken by 6,446 unique users. Through quantitative experiments across monolingual and cross-lingual zero-shot settings, we take the first step in democratizing audio based content moderation in Indic languages and set forth our dataset to pave future work.
BBS-KWS:The Mandarin Keyword Spotting System Won the Video Keyword Wakeup Challenge
Dec 03, 2021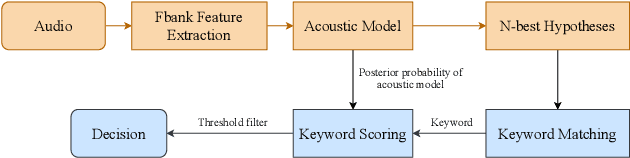
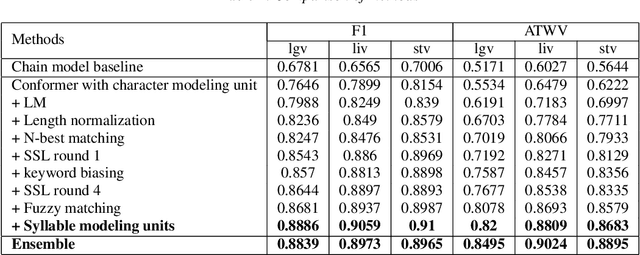
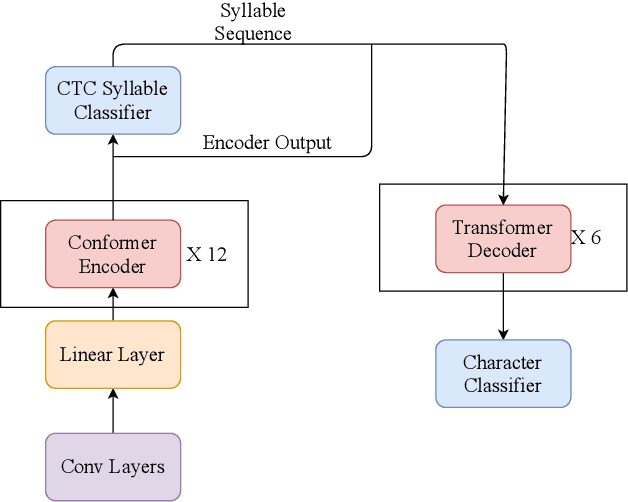
This paper introduces the system submitted by the Yidun NISP team to the video keyword wakeup challenge. We propose a mandarin keyword spotting system (KWS) with several novel and effective improvements, including a big backbone (B) model, a keyword biasing (B) mechanism and the introduction of syllable modeling units (S). By considering this, we term the total system BBS-KWS as an abbreviation. The BBS-KWS system consists of an end-to-end automatic speech recognition (ASR) module and a KWS module. The ASR module converts speech features to text representations, which applies a big backbone network to the acoustic model and takes syllable modeling units into consideration as well. In addition, the keyword biasing mechanism is used to improve the recall rate of keywords in the ASR inference stage. The KWS module applies multiple criteria to determine the absence or presence of the keywords, such as multi-stage matching, fuzzy matching, and connectionist temporal classification (CTC) prefix score. To further improve our system, we conduct semi-supervised learning on the CN-Celeb dataset for better generalization. In the VKW task, the BBS-KWS system achieves significant gains over the baseline and won the first place in two tracks.
ESPnet: End-to-End Speech Processing Toolkit
Mar 30, 2018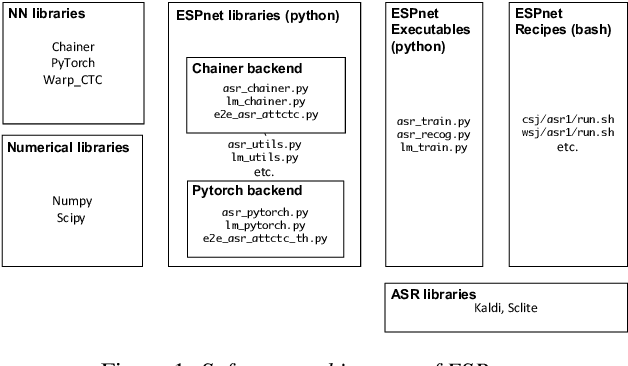
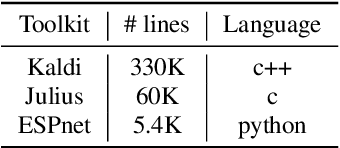
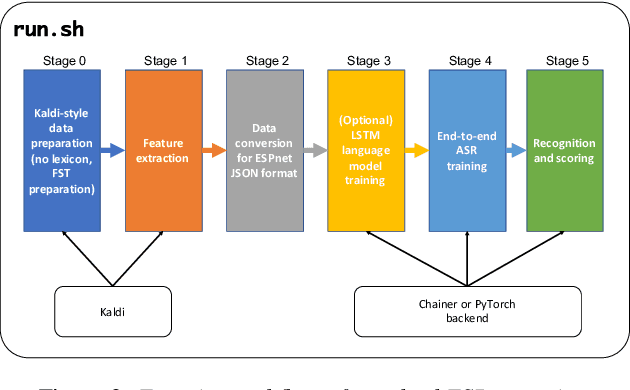
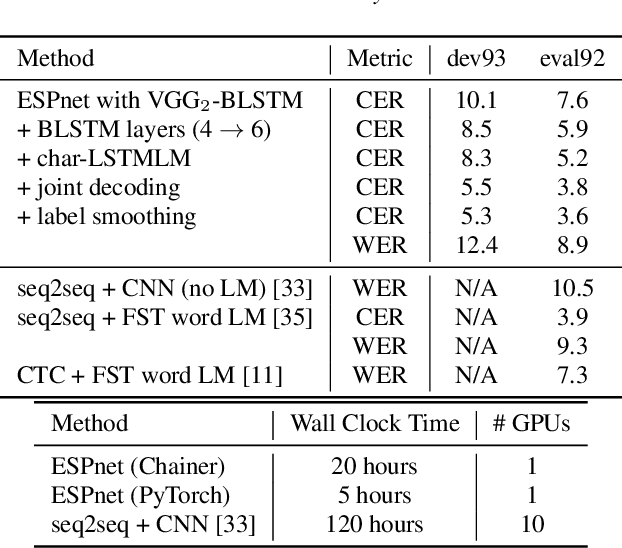
This paper introduces a new open source platform for end-to-end speech processing named ESPnet. ESPnet mainly focuses on end-to-end automatic speech recognition (ASR), and adopts widely-used dynamic neural network toolkits, Chainer and PyTorch, as a main deep learning engine. ESPnet also follows the Kaldi ASR toolkit style for data processing, feature extraction/format, and recipes to provide a complete setup for speech recognition and other speech processing experiments. This paper explains a major architecture of this software platform, several important functionalities, which differentiate ESPnet from other open source ASR toolkits, and experimental results with major ASR benchmarks.