 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Countering hate on social media: Large scale classification of hate and counter speech
Jun 05, 2020
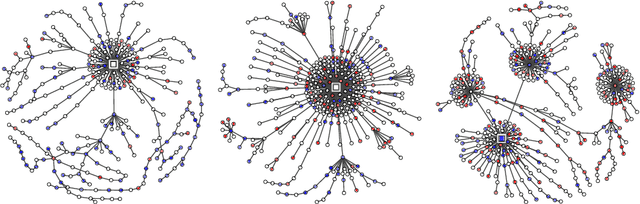
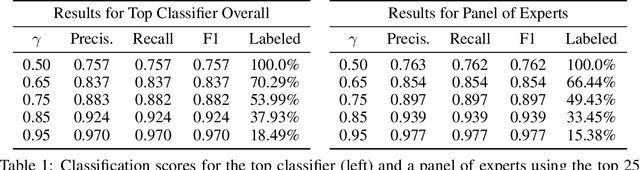
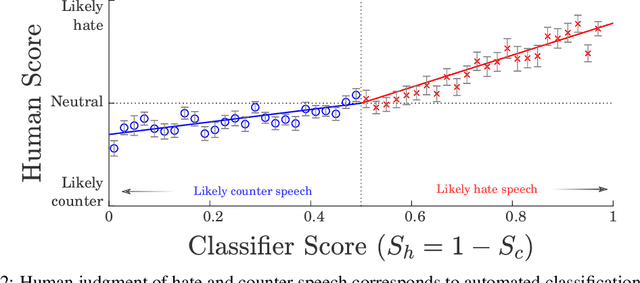
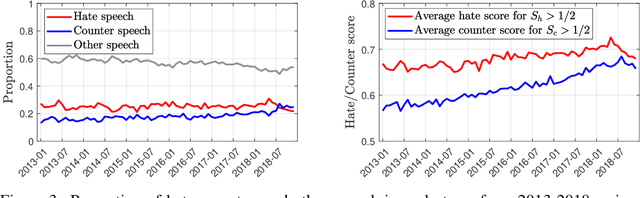
Hateful rhetoric is plaguing online discourse, fostering extreme societal movements and possibly giving rise to real-world violence. A potential solution to this growing global problem is citizen-generated counter speech where citizens actively engage in hate-filled conversations to attempt to restore civil non-polarized discourse. However, its actual effectiveness in curbing the spread of hatred is unknown and hard to quantify. One major obstacle to researching this question is a lack of large labeled data sets for training automated classifiers to identify counter speech. Here we made use of a unique situation in Germany where self-labeling groups engaged in organized online hate and counter speech. We used an ensemble learning algorithm which pairs a variety of paragraph embeddings with regularized logistic regression functions to classify both hate and counter speech in a corpus of millions of relevant tweets from these two groups. Our pipeline achieved macro F1 scores on out of sample balanced test sets ranging from 0.76 to 0.97---accuracy in line and even exceeding the state of the art. On thousands of tweets, we used crowdsourcing to verify that the judgments made by the classifier are in close alignment with human judgment. We then used the classifier to discover hate and counter speech in more than 135,000 fully-resolved Twitter conversations occurring from 2013 to 2018 and study their frequency and interaction. Altogether, our results highlight the potential of automated methods to evaluate the impact of coordinated counter speech in stabilizing conversations on social media.
Correlating Subword Articulation with Lip Shapes for Embedding Aware Audio-Visual Speech Enhancement
Sep 21, 2020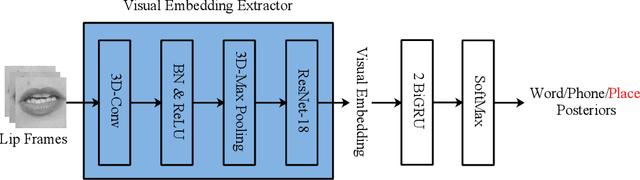
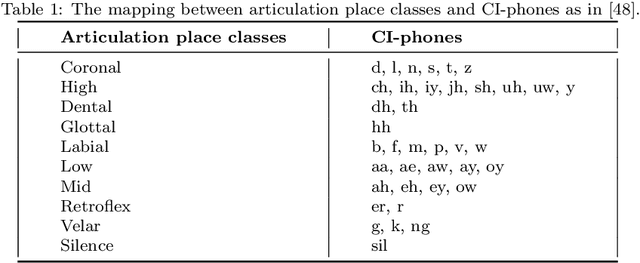

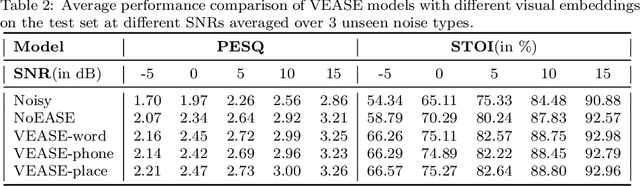
In this paper, we propose a visual embedding approach to improving embedding aware speech enhancement (EASE) by synchronizing visual lip frames at the phone and place of articulation levels. We first extract visual embedding from lip frames using a pre-trained phone or articulation place recognizer for visual-only EASE (VEASE). Next, we extract audio-visual embedding from noisy speech and lip videos in an information intersection manner, utilizing a complementarity of audio and visual features for multi-modal EASE (MEASE). Experiments on the TCD-TIMIT corpus corrupted by simulated additive noises show that our proposed subword based VEASE approach is more effective than conventional embedding at the word level. Moreover, visual embedding at the articulation place level, leveraging upon a high correlation between place of articulation and lip shapes, shows an even better performance than that at the phone level. Finally the proposed MEASE framework, incorporating both audio and visual embedding, yields significantly better speech quality and intelligibility than those obtained with the best visual-only and audio-only EASE systems.
U2++: Unified Two-pass Bidirectional End-to-end Model for Speech Recognition
Jul 07, 2021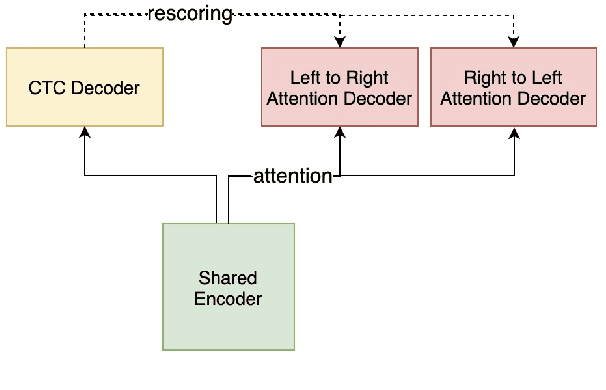
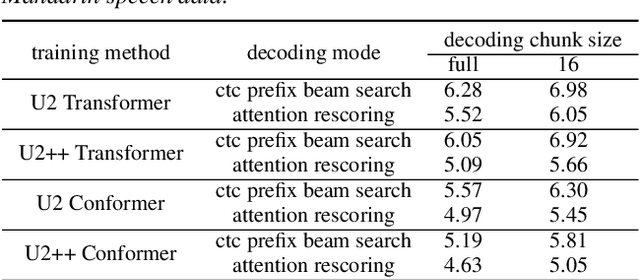
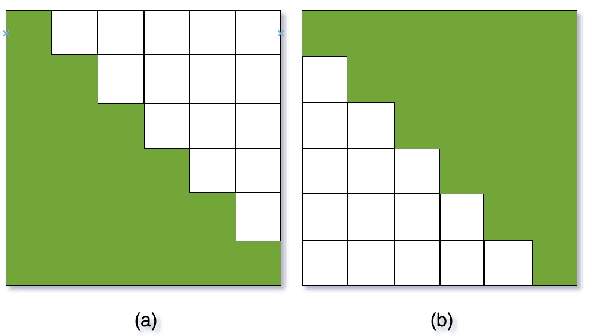
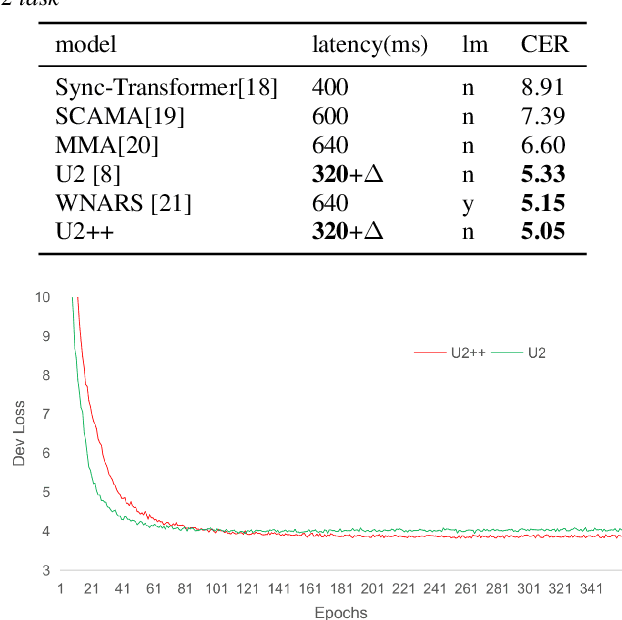
The unified streaming and non-streaming two-pass (U2) end-to-end model for speech recognition has shown great performance in terms of streaming capability, accuracy, real-time factor (RTF), and latency. In this paper, we present U2++, an enhanced version of U2 to further improve the accuracy. The core idea of U2++ is to use the forward and the backward information of the labeling sequences at the same time at training to learn richer information, and combine the forward and backward prediction at decoding to give more accurate recognition results. We also proposed a new data augmentation method called SpecSub to help the U2++ model to be more accurate and robust. Our experiments show that, compared with U2, U2++ shows faster convergence at training, better robustness to the decoding method, as well as consistent 5\% - 8\% word error rate reduction gain over U2. On the experiment of AISHELL-1, we achieve a 4.63\% character error rate (CER) with a non-streaming setup and 5.05\% with a streaming setup with 320ms latency by U2++. To the best of our knowledge, 5.05\% is the best-published streaming result on the AISHELL-1 test set.
Chefs' Random Tables: Non-Trigonometric Random Features
May 30, 2022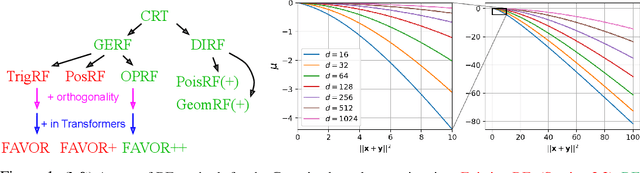
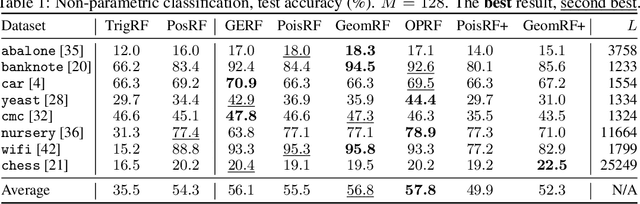
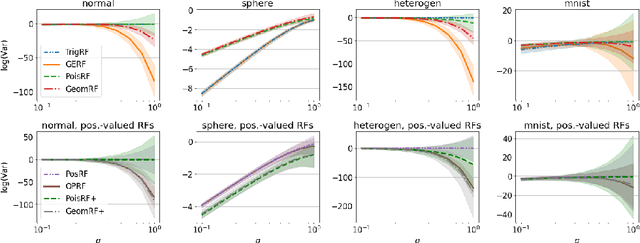
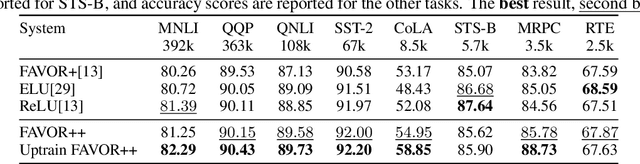
We introduce chefs' random tables (CRTs), a new class of non-trigonometric random features (RFs) to approximate Gaussian and softmax kernels. CRTs are an alternative to standard random kitchen sink (RKS) methods, which inherently rely on the trigonometric maps. We present variants of CRTs where RFs are positive, a key requirement for applications in recent low-rank Transformers. Further variance reduction is possible by leveraging statistics which are simple to compute. One instantiation of CRTs, the optimal positive random features (OPRFs), is to our knowledge the first RF method for unbiased softmax kernel estimation with positive and bounded RFs, resulting in exponentially small tails and much lower variance than its counterparts. As we show, orthogonal random features applied in OPRFs provide additional variance reduction for any dimensionality $d$ (not only asymptotically for sufficiently large $d$, as for RKS). We test CRTs on many tasks ranging from non-parametric classification to training Transformers for text, speech and image data, obtaining new state-of-the-art results for low-rank text Transformers, while providing linear space and time complexity.
Real time spectrogram inversion on mobile phone
Mar 10, 2022
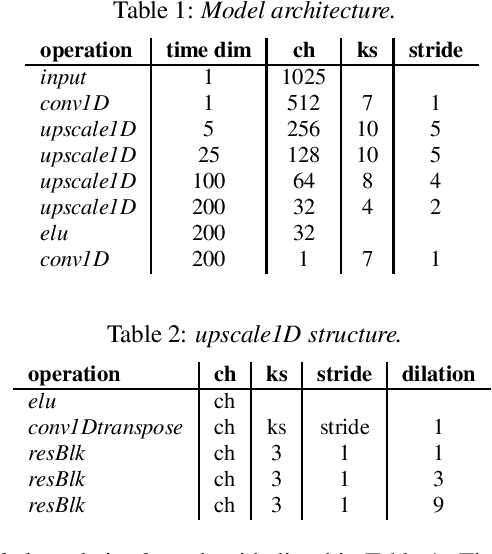
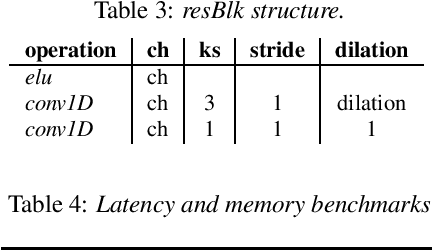

With the growth of computing power on mobile phones and privacy concerns over user's data, on-device real time speech processing has become an important research topic. In this paper, we focus on methods for real time spectrogram inversion, where an algorithm receives a portion of the input signal (e.g., one frame) and processes it incrementally, i.e., operating in streaming mode. We present a real time Griffin Lim(GL) algorithm using a sliding window approach in STFT domain. The proposed algorithm is 2.4x faster than real time on the ARM CPU of a Pixel4. In addition we explore a neural vocoder operating in streaming mode and demonstrate the impact of looking ahead on perceptual quality. As little as one hop size (12.5ms) of lookahead is able to significantly improve perceptual quality in comparison to a causal model. We compare GL with the neural vocoder and show different trade-offs in terms of perceptual quality, on-device latency, algorithmic delay, memory footprint and noise sensitivity. For fair quality assessment of the GL approach, we use input log magnitude spectrogram without mel transformation. We evaluate presented real time spectrogram inversion approaches on clean, noisy and atypical speech.
WaveCRN: An Efficient Convolutional Recurrent Neural Network for End-to-end Speech Enhancement
Apr 12, 2020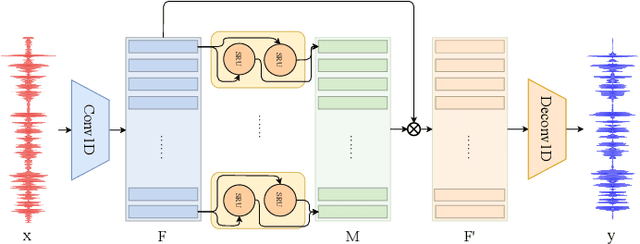
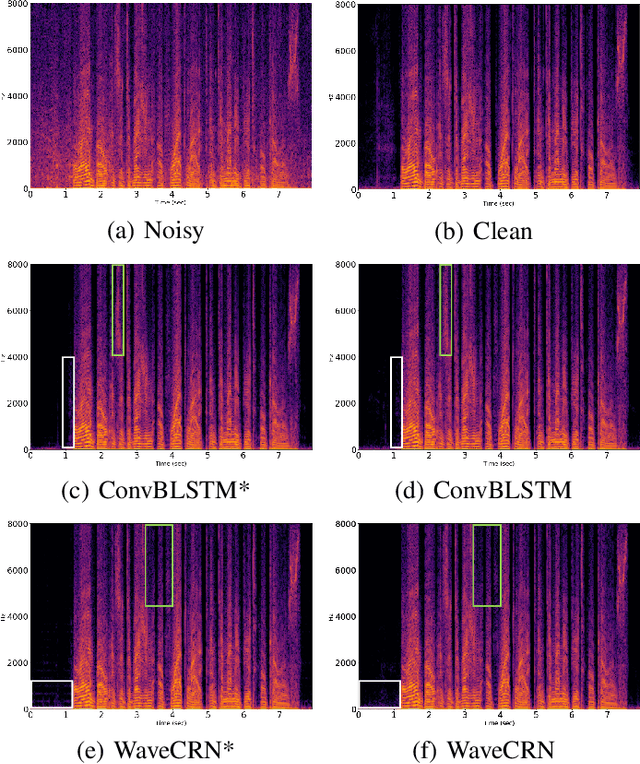
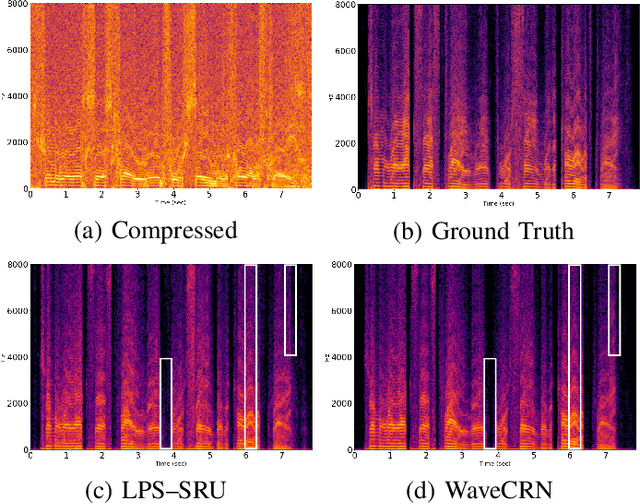
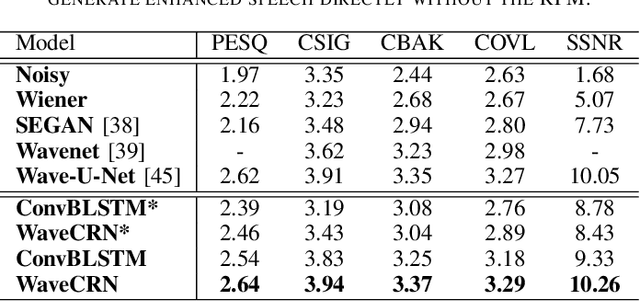
Due to the simple design pipeline, end-to-end (E2E) neural models for speech enhancement (SE) have attracted great interest. In order to improve the performance of the E2E model, the locality and temporal sequential properties of speech should be efficiently taken into account when modelling. However, in most current E2E models for SE, these properties are either not fully considered or are too complex to be realized. In this paper, we propose an efficient E2E SE model, termed WaveCRN. In WaveCRN, the speech locality feature is captured by a convolutional neural network (CNN), while the temporal sequential property of the locality feature is modeled by stacked simple recurrent units (SRU). Unlike a conventional temporal sequential model that uses a long short-term memory (LSTM) network, which is difficult to parallelize, SRU can be efficiently parallelized in calculation with even fewer model parameters. In addition, in order to more effectively suppress the noise components in the input noisy speech, we derive a novel restricted feature masking (RFM) approach that performs enhancement on the feature maps in the hidden layers; this is different from the approach that applies the estimated ratio mask on the noisy spectral features, which is commonly used in speech separation methods. Experimental results on speech denoising and compressed speech restoration tasks confirm that with the lightweight architecture of SRU and the feature-mapping-based RFM, WaveCRN performs comparably with other state-of-the-art approaches with notably reduced model complexity and inference time.
Improving EEG based Continuous Speech Recognition
Dec 24, 2019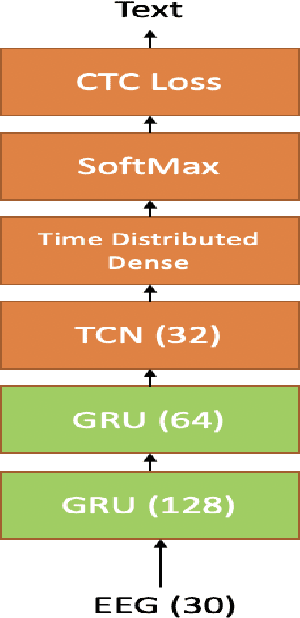
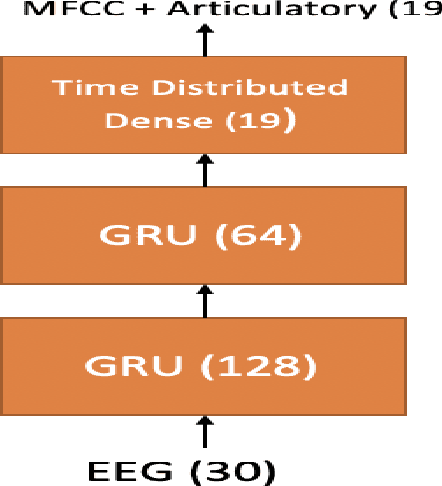
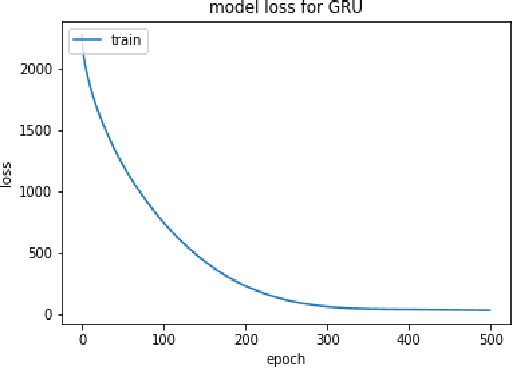
In this paper we introduce various techniques to improve the performance of electroencephalography (EEG) features based continuous speech recognition (CSR) systems. A connectionist temporal classification (CTC) based automatic speech recognition (ASR) system was implemented for performing recognition. We introduce techniques to initialize the weights of the recurrent layers in the encoder of the CTC model with more meaningful weights rather than with random weights and we make use of an external language model to improve the beam search during decoding time. We finally study the problem of predicting articulatory features from EEG features in this paper.
AdaVocoder: Adaptive Vocoder for Custom Voice
Mar 18, 2022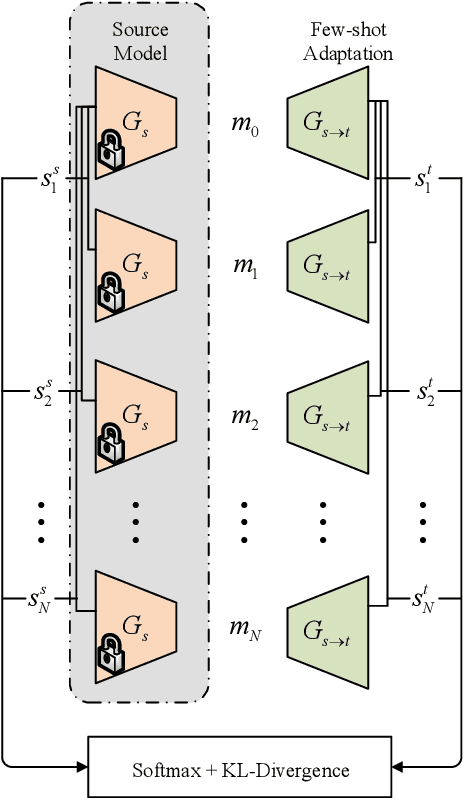

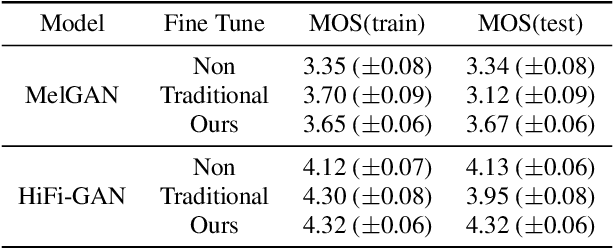

Custom voice is to construct a personal speech synthesis system by adapting the source speech synthesis model to the target model through the target few recordings. The solution to constructing a custom voice is to combine an adaptive acoustic model with a robust vocoder. However, training a robust vocoder usually requires a multi-speaker dataset, which should include various age groups and various timbres, so that the trained vocoder can be used for unseen speakers. Collecting such a multi-speaker dataset is difficult, and the dataset distribution always has a mismatch with the distribution of the target speaker dataset. This paper proposes an adaptive vocoder for custom voice from another novel perspective to solve the above problems. The adaptive vocoder mainly uses a cross-domain consistency loss to solve the overfitting problem encountered by the GAN-based neural vocoder in the transfer learning of few-shot scenes. We construct two adaptive vocoders, AdaMelGAN and AdaHiFi-GAN. First, We pre-train the source vocoder model on AISHELL3 and CSMSC datasets, respectively. Then, fine-tune it on the internal dataset VXI-children with few adaptation data. The empirical results show that a high-quality custom voice system can be built by combining a adaptive acoustic model with a adaptive vocoder.
Towards Learning a Universal Non-Semantic Representation of Speech
Feb 25, 2020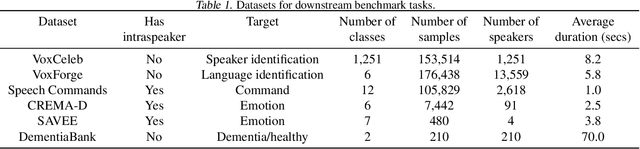
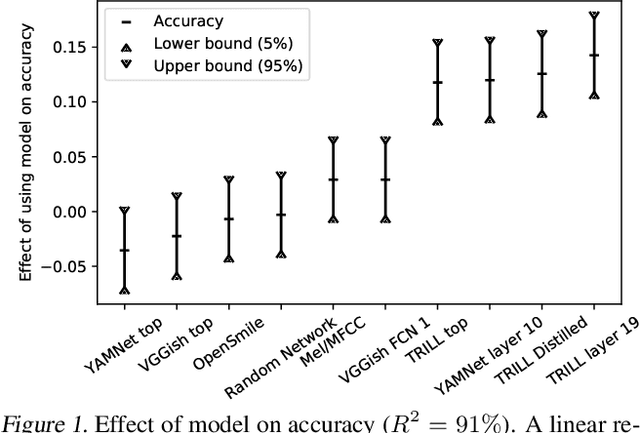
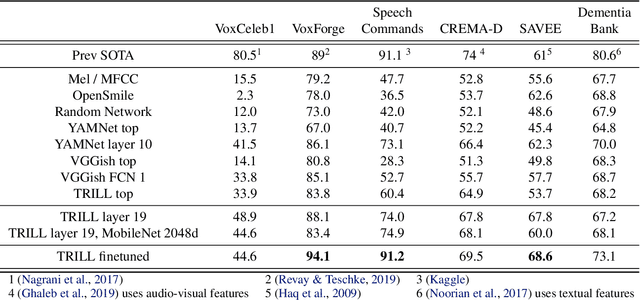
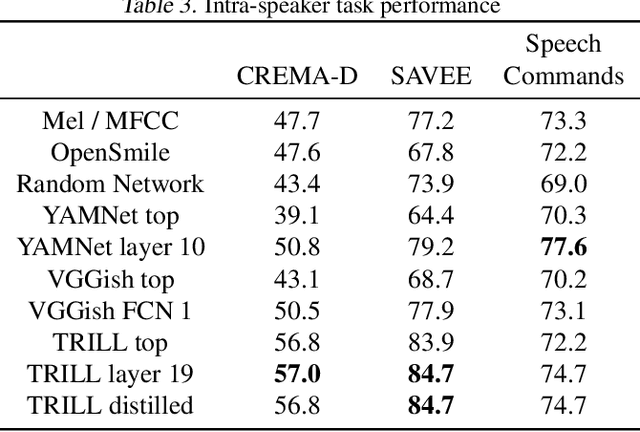
The ultimate goal of transfer learning is to reduce labeled data requirements by exploiting a pre-existing embedding model trained for different datasets or tasks. While significant progress has been made in the visual and language domains, the speech community has yet to identify a strategy with wide-reaching applicability across tasks. This paper describes a representation of speech based on an unsupervised triplet-loss objective, which exceeds state-of-the-art performance on a number of transfer learning tasks drawn from the non-semantic speech domain. The embedding is trained on a publicly available dataset, and it is tested on a variety of low-resource downstream tasks, including personalization tasks and medical domain. The model will be publicly released.