 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Semantic Type Dependencies for Clinical Named Entity Recognition
Mar 07, 2025



Previous work on clinical relation extraction from free-text sentences leveraged information about semantic types from clinical knowledge bases as a part of entity representations. In this paper, we exploit additional evidence by also making use of domain-specific semantic type dependencies. We encode the relation between a span of tokens matching a Unified Medical Language System (UMLS) concept and other tokens in the sentence. We implement our method and compare against different named entity recognition (NER) architectures (i.e., BiLSTM-CRF and BiLSTM-GCN-CRF) using different pre-trained clinical embeddings (i.e., BERT, BioBERT, UMLSBert). Our experimental results on clinical datasets show that in some cases NER effectiveness can be significantly improved by making use of domain-specific semantic type dependencies. Our work is also the first study generating a matrix encoding to make use of more than three dependencies in one pass for the NER task.
Guiding Neural Entity Alignment with Compatibility
Nov 29, 2022



Entity Alignment (EA) aims to find equivalent entities between two Knowledge Graphs (KGs). While numerous neural EA models have been devised, they are mainly learned using labelled data only. In this work, we argue that different entities within one KG should have compatible counterparts in the other KG due to the potential dependencies among the entities. Making compatible predictions thus should be one of the goals of training an EA model along with fitting the labelled data: this aspect however is neglected in current methods. To power neural EA models with compatibility, we devise a training framework by addressing three problems: (1) how to measure the compatibility of an EA model; (2) how to inject the property of being compatible into an EA model; (3) how to optimise parameters of the compatibility model. Extensive experiments on widely-used datasets demonstrate the advantages of integrating compatibility within EA models. In fact, state-of-the-art neural EA models trained within our framework using just 5\% of the labelled data can achieve comparable effectiveness with supervised training using 20\% of the labelled data.
Streaming Parrotron for on-device speech-to-speech conversion
Oct 25, 2022



We present a fully on-device and streaming Speech-To-Speech (STS) conversion model that normalizes a given input speech directly to synthesized output speech (a.k.a. Parrotron). Deploying such an end-to-end model locally on mobile devices pose significant challenges in terms of memory footprint and computation requirements. In this paper, we present a streaming-based approach to produce an acceptable delay, with minimal loss in speech conversion quality, when compared to a non-streaming server-based approach. Our approach consists of first streaming the encoder in real time while the speaker is speaking. Then, as soon as the speaker stops speaking, we run the spectrogram decoder in streaming mode along the side of a streaming vocoder to generate output speech in real time. To achieve an acceptable delay quality trade-off, we study a novel hybrid approach for look-ahead in the encoder which combines a look-ahead feature stacker with a look-ahead self-attention. We also compare the model with int4 quantization aware training and int8 post training quantization and show that our streaming approach is 2x faster than real time on the Pixel4 CPU.
High-quality Task Division for Large-scale Entity Alignment
Aug 22, 2022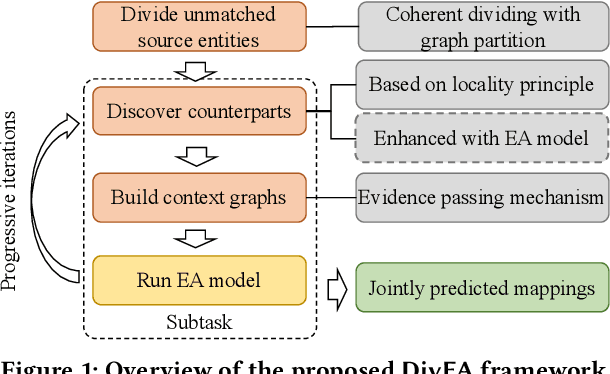

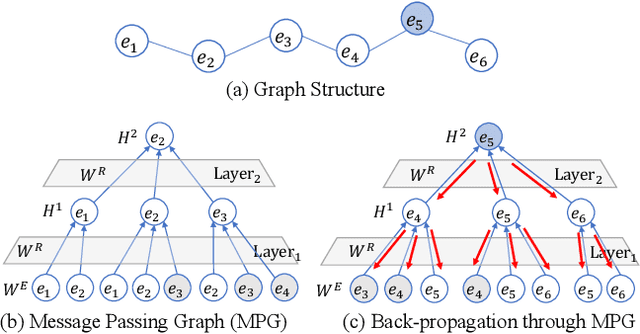

Entity Alignment (EA) aims to match equivalent entities that refer to the same real-world objects and is a key step for Knowledge Graph (KG) fusion. Most neural EA models cannot be applied to large-scale real-life KGs due to their excessive consumption of GPU memory and time. One promising solution is to divide a large EA task into several subtasks such that each subtask only needs to match two small subgraphs of the original KGs. However, it is challenging to divide the EA task without losing effectiveness. Existing methods display low coverage of potential mappings, insufficient evidence in context graphs, and largely differing subtask sizes. In this work, we design the DivEA framework for large-scale EA with high-quality task division. To include in the EA subtasks a high proportion of the potential mappings originally present in the large EA task, we devise a counterpart discovery method that exploits the locality principle of the EA task and the power of trained EA models. Unique to our counterpart discovery method is the explicit modelling of the chance of a potential mapping. We also introduce an evidence passing mechanism to quantify the informativeness of context entities and find the most informative context graphs with flexible control of the subtask size. Extensive experiments show that DivEA achieves higher EA performance than alternative state-of-the-art solutions.
A Scalable Model Specialization Framework for Training and Inference using Submodels and its Application to Speech Model Personalization
Mar 23, 2022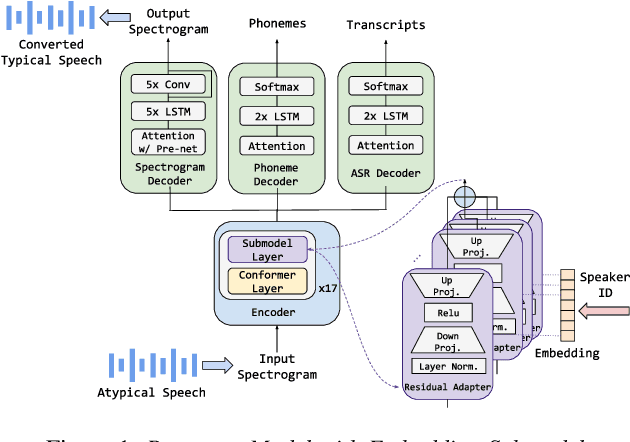
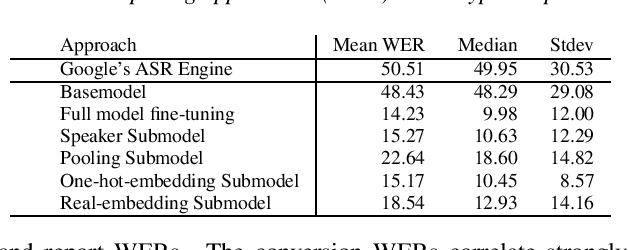
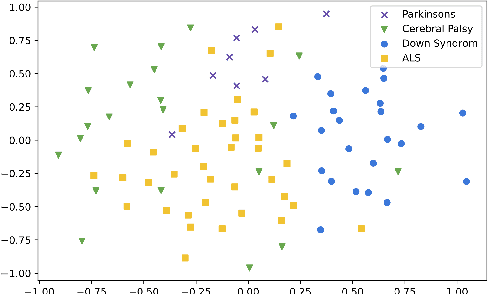
Model fine-tuning and adaptation have become a common approach for model specialization for downstream tasks or domains. Fine-tuning the entire model or a subset of the parameters using light-weight adaptation has shown considerable success across different specialization tasks. Fine-tuning a model for a large number of domains typically requires starting a new training job for every domain posing scaling limitations. Once these models are trained, deploying them also poses significant scalability challenges for inference for real-time applications. In this paper, building upon prior light-weight adaptation techniques, we propose a modular framework that enables us to substantially improve scalability for model training and inference. We introduce Submodels that can be quickly and dynamically loaded for on-the-fly inference. We also propose multiple approaches for training those Submodels in parallel using an embedding space in the same training job. We test our framework on an extreme use-case which is speech model personalization for atypical speech, requiring a Submodel for each user. We obtain 128x Submodel throughput with a fixed computation budget without a loss of accuracy. We also show that learning a speaker-embedding space can scale further and reduce the amount of personalization training data required per speaker.
Real time spectrogram inversion on mobile phone
Mar 10, 2022
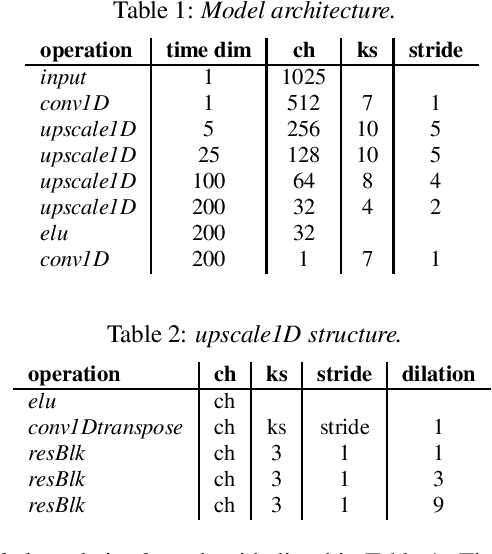
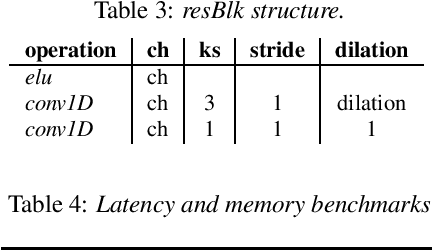

With the growth of computing power on mobile phones and privacy concerns over user's data, on-device real time speech processing has become an important research topic. In this paper, we focus on methods for real time spectrogram inversion, where an algorithm receives a portion of the input signal (e.g., one frame) and processes it incrementally, i.e., operating in streaming mode. We present a real time Griffin Lim(GL) algorithm using a sliding window approach in STFT domain. The proposed algorithm is 2.4x faster than real time on the ARM CPU of a Pixel4. In addition we explore a neural vocoder operating in streaming mode and demonstrate the impact of looking ahead on perceptual quality. As little as one hop size (12.5ms) of lookahead is able to significantly improve perceptual quality in comparison to a causal model. We compare GL with the neural vocoder and show different trade-offs in terms of perceptual quality, on-device latency, algorithmic delay, memory footprint and noise sensitivity. For fair quality assessment of the GL approach, we use input log magnitude spectrogram without mel transformation. We evaluate presented real time spectrogram inversion approaches on clean, noisy and atypical speech.