 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Mongolian Speech Synthesis Based on Automatic Prosody Annotation
Nov 17, 2022While deep learning-based text-to-speech (TTS) models such as VITS have shown excellent results, they typically require a sizable set of high-quality <text, audio> pairs to train, which is expensive to collect. So far, most languages in the world still lack the training data needed to develop TTS systems. This paper proposes two improvement methods for the two problems faced by low-resource Mongolian speech synthesis: a) In view of the lack of high-quality <text, audio> pairs of data, it is difficult to model the mapping problem from linguistic features to acoustic features. Improvements are made using pre-trained VITS model and transfer learning methods. b) In view of the problem of less labeled information, this paper proposes to use an automatic prosodic annotation method to label the prosodic information of text and corresponding speech, thereby improving the naturalness and intelligibility of low-resource Mongolian language. Through empirical research, the N-MOS of the method proposed in this paper is 4.195, and the I-MOS is 4.228.
AdaVocoder: Adaptive Vocoder for Custom Voice
Mar 18, 2022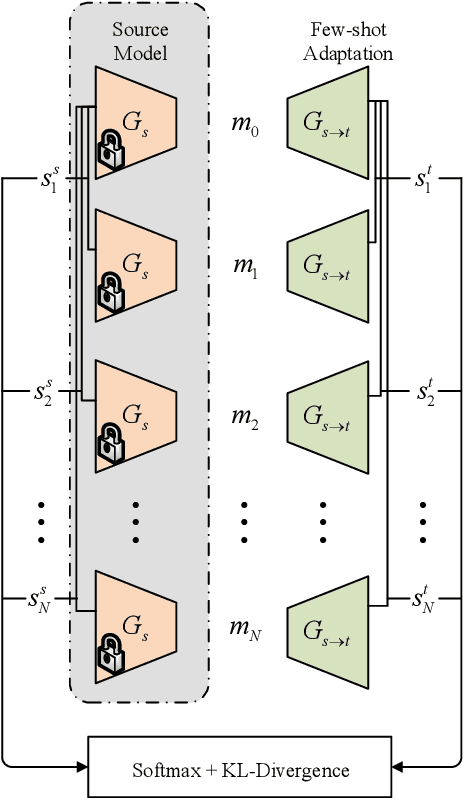

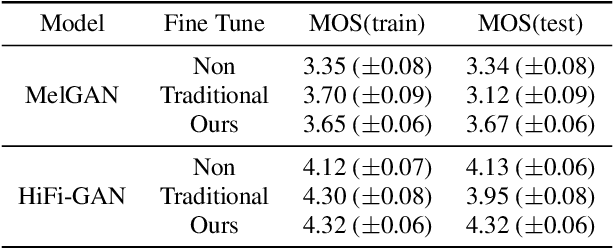

Custom voice is to construct a personal speech synthesis system by adapting the source speech synthesis model to the target model through the target few recordings. The solution to constructing a custom voice is to combine an adaptive acoustic model with a robust vocoder. However, training a robust vocoder usually requires a multi-speaker dataset, which should include various age groups and various timbres, so that the trained vocoder can be used for unseen speakers. Collecting such a multi-speaker dataset is difficult, and the dataset distribution always has a mismatch with the distribution of the target speaker dataset. This paper proposes an adaptive vocoder for custom voice from another novel perspective to solve the above problems. The adaptive vocoder mainly uses a cross-domain consistency loss to solve the overfitting problem encountered by the GAN-based neural vocoder in the transfer learning of few-shot scenes. We construct two adaptive vocoders, AdaMelGAN and AdaHiFi-GAN. First, We pre-train the source vocoder model on AISHELL3 and CSMSC datasets, respectively. Then, fine-tune it on the internal dataset VXI-children with few adaptation data. The empirical results show that a high-quality custom voice system can be built by combining a adaptive acoustic model with a adaptive vocoder.