 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLip-reading with Hierarchical Pyramidal Convolution and Self-Attention
Dec 28, 2020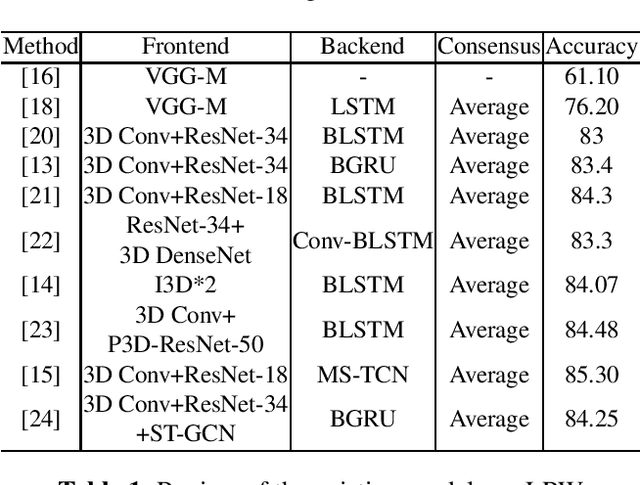
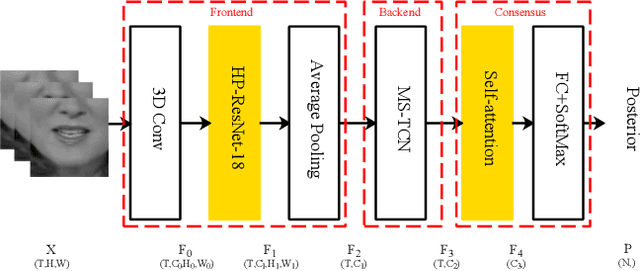
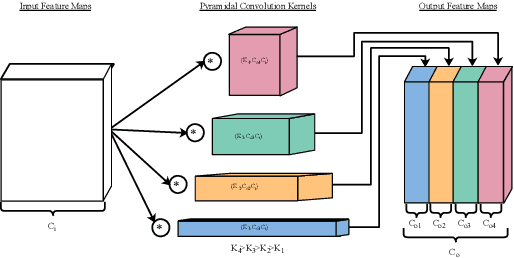
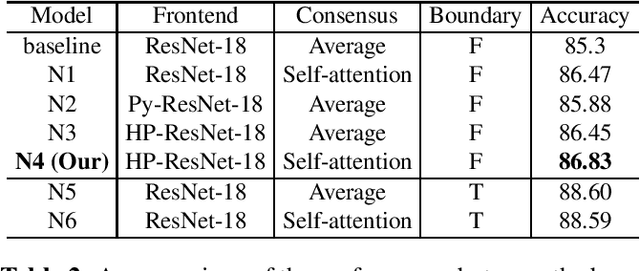
In this paper, we propose a novel deep learning architecture to improving word-level lip-reading. On the one hand, we first introduce the multi-scale processing into the spatial feature extraction for lip-reading. Specially, we proposed hierarchical pyramidal convolution (HPConv) to replace the standard convolution in original module, leading to improvements over the model's ability to discover fine-grained lip movements. On the other hand, we merge information in all time steps of the sequence by utilizing self-attention, to make the model pay more attention to the relevant frames. These two advantages are combined together to further enhance the model's classification power. Experiments on the Lip Reading in the Wild (LRW) dataset show that our proposed model has achieved 86.83% accuracy, yielding 1.53% absolute improvement over the current state-of-the-art. We also conducted extensive experiments to better understand the behavior of the proposed model.
Correlating Subword Articulation with Lip Shapes for Embedding Aware Audio-Visual Speech Enhancement
Sep 21, 2020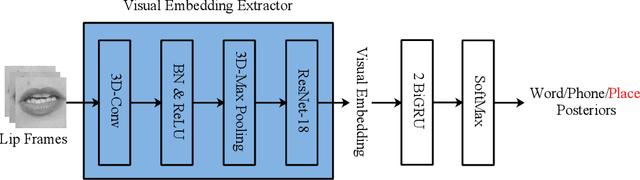
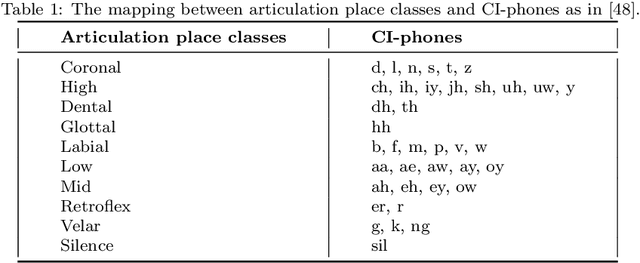

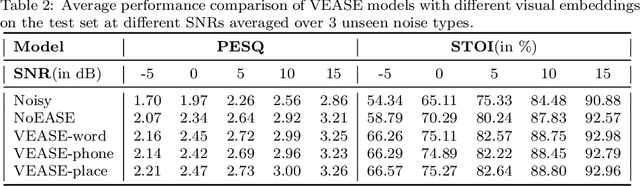
In this paper, we propose a visual embedding approach to improving embedding aware speech enhancement (EASE) by synchronizing visual lip frames at the phone and place of articulation levels. We first extract visual embedding from lip frames using a pre-trained phone or articulation place recognizer for visual-only EASE (VEASE). Next, we extract audio-visual embedding from noisy speech and lip videos in an information intersection manner, utilizing a complementarity of audio and visual features for multi-modal EASE (MEASE). Experiments on the TCD-TIMIT corpus corrupted by simulated additive noises show that our proposed subword based VEASE approach is more effective than conventional embedding at the word level. Moreover, visual embedding at the articulation place level, leveraging upon a high correlation between place of articulation and lip shapes, shows an even better performance than that at the phone level. Finally the proposed MEASE framework, incorporating both audio and visual embedding, yields significantly better speech quality and intelligibility than those obtained with the best visual-only and audio-only EASE systems.