 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
PAM: Prompting Audio-Language Models for Audio Quality Assessment
Feb 01, 2024
While audio quality is a key performance metric for various audio processing tasks, including generative modeling, its objective measurement remains a challenge. Audio-Language Models (ALMs) are pre-trained on audio-text pairs that may contain information about audio quality, the presence of artifacts, or noise. Given an audio input and a text prompt related to quality, an ALM can be used to calculate a similarity score between the two. Here, we exploit this capability and introduce PAM, a no-reference metric for assessing audio quality for different audio processing tasks. Contrary to other "reference-free" metrics, PAM does not require computing embeddings on a reference dataset nor training a task-specific model on a costly set of human listening scores. We extensively evaluate the reliability of PAM against established metrics and human listening scores on four tasks: text-to-audio (TTA), text-to-music generation (TTM), text-to-speech (TTS), and deep noise suppression (DNS). We perform multiple ablation studies with controlled distortions, in-the-wild setups, and prompt choices. Our evaluation shows that PAM correlates well with existing metrics and human listening scores. These results demonstrate the potential of ALMs for computing a general-purpose audio quality metric.
Turn-taking and Backchannel Prediction with Acoustic and Large Language Model Fusion
Jan 26, 2024We propose an approach for continuous prediction of turn-taking and backchanneling locations in spoken dialogue by fusing a neural acoustic model with a large language model (LLM). Experiments on the Switchboard human-human conversation dataset demonstrate that our approach consistently outperforms the baseline models with single modality. We also develop a novel multi-task instruction fine-tuning strategy to further benefit from LLM-encoded knowledge for understanding the tasks and conversational contexts, leading to additional improvements. Our approach demonstrates the potential of combined LLMs and acoustic models for a more natural and conversational interaction between humans and speech-enabled AI agents.
Masked Audio Modeling with CLAP and Multi-Objective Learning
Jan 29, 2024Most existing masked audio modeling (MAM) methods learn audio representations by masking and reconstructing local spectrogram patches. However, the reconstruction loss mainly accounts for the signal-level quality of the reconstructed spectrogram and is still limited in extracting high-level audio semantics. In this paper, we propose to enhance the semantic modeling of MAM by distilling cross-modality knowledge from contrastive language-audio pretraining (CLAP) representations for both masked and unmasked regions (MAM-CLAP) and leveraging a multi-objective learning strategy with a supervised classification branch (SupMAM), thereby providing more semantic knowledge for MAM and enabling it to effectively learn global features from labels. Experiments show that our methods significantly improve the performance on multiple downstream tasks. Furthermore, by combining our MAM-CLAP with SupMAM, we can achieve new state-of-the-art results on various audio and speech classification tasks, exceeding previous self-supervised learning and supervised pretraining methods.
BAE-Net: A Low complexity and high fidelity Bandwidth-Adaptive neural network for speech super-resolution
Dec 21, 2023Speech bandwidth extension (BWE) has demonstrated promising performance in enhancing the perceptual speech quality in real communication systems. Most existing BWE researches primarily focus on fixed upsampling ratios, disregarding the fact that the effective bandwidth of captured audio may fluctuate frequently due to various capturing devices and transmission conditions. In this paper, we propose a novel streaming adaptive bandwidth extension solution dubbed BAE-Net, which is suitable to handle the low-resolution speech with unknown and varying effective bandwidth. To address the challenges of recovering both the high-frequency magnitude and phase speech content blindly, we devise a dual-stream architecture that incorporates the magnitude inpainting and phase refinement. For potential applications on edge devices, this paper also introduces BAE-NET-lite, which is a lightweight, streaming and efficient framework. Quantitative results demonstrate the superiority of BAE-Net in terms of both performance and computational efficiency when compared with existing state-of-the-art BWE methods.
Mimic: Speaking Style Disentanglement for Speech-Driven 3D Facial Animation
Dec 18, 2023Speech-driven 3D facial animation aims to synthesize vivid facial animations that accurately synchronize with speech and match the unique speaking style. However, existing works primarily focus on achieving precise lip synchronization while neglecting to model the subject-specific speaking style, often resulting in unrealistic facial animations. To the best of our knowledge, this work makes the first attempt to explore the coupled information between the speaking style and the semantic content in facial motions. Specifically, we introduce an innovative speaking style disentanglement method, which enables arbitrary-subject speaking style encoding and leads to a more realistic synthesis of speech-driven facial animations. Subsequently, we propose a novel framework called \textbf{Mimic} to learn disentangled representations of the speaking style and content from facial motions by building two latent spaces for style and content, respectively. Moreover, to facilitate disentangled representation learning, we introduce four well-designed constraints: an auxiliary style classifier, an auxiliary inverse classifier, a content contrastive loss, and a pair of latent cycle losses, which can effectively contribute to the construction of the identity-related style space and semantic-related content space. Extensive qualitative and quantitative experiments conducted on three publicly available datasets demonstrate that our approach outperforms state-of-the-art methods and is capable of capturing diverse speaking styles for speech-driven 3D facial animation. The source code and supplementary video are publicly available at: https://zeqing-wang.github.io/Mimic/
Overlap-aware End-to-End Supervised Hierarchical Graph Clustering for Speaker Diarization
Jan 23, 2024Speaker diarization, the task of segmenting an audio recording based on speaker identity, constitutes an important speech pre-processing step for several downstream applications. The conventional approach to diarization involves multiple steps of embedding extraction and clustering, which are often optimized in an isolated fashion. While end-to-end diarization systems attempt to learn a single model for the task, they are often cumbersome to train and require large supervised datasets. In this paper, we propose an end-to-end supervised hierarchical clustering algorithm based on graph neural networks (GNN), called End-to-end Supervised HierARchical Clustering (E-SHARC). The E-SHARC approach uses front-end mel-filterbank features as input and jointly learns an embedding extractor and the GNN clustering module, performing representation learning, metric learning, and clustering with end-to-end optimization. Further, with additional inputs from an external overlap detector, the E-SHARC approach is capable of predicting the speakers in the overlapping speech regions. The experimental evaluation on several benchmark datasets like AMI, VoxConverse and DISPLACE, illustrates that the proposed E-SHARC framework improves significantly over the state-of-art diarization systems.
Attention-Guided Adaptation for Code-Switching Speech Recognition
Dec 14, 2023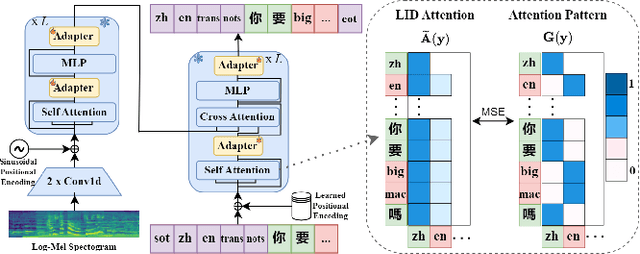
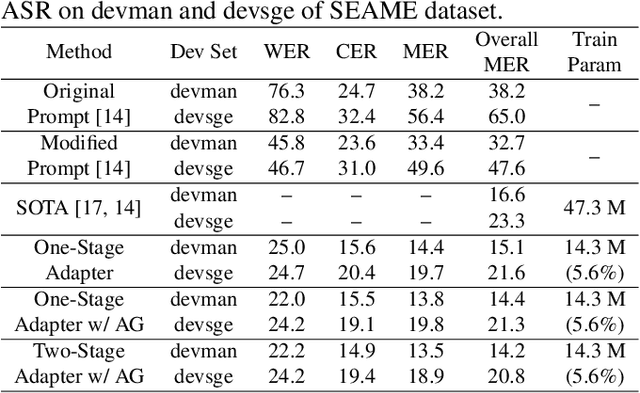
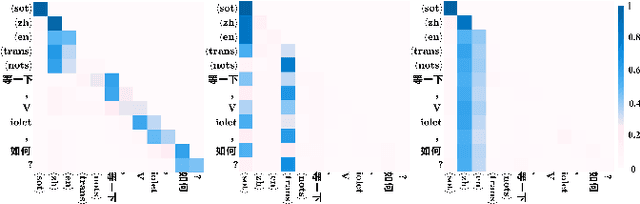
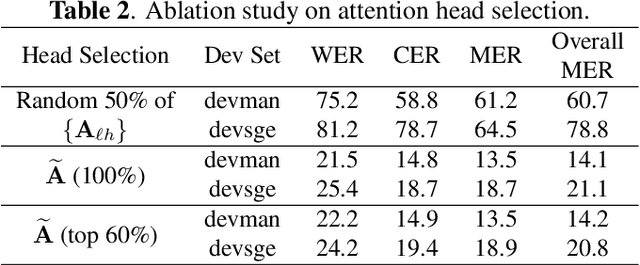
The prevalence of the powerful multilingual models, such as Whisper, has significantly advanced the researches on speech recognition. However, these models often struggle with handling the code-switching setting, which is essential in multilingual speech recognition. Recent studies have attempted to address this setting by separating the modules for different languages to ensure distinct latent representations for languages. Some other methods considered the switching mechanism based on language identification. In this study, a new attention-guided adaptation is proposed to conduct parameter-efficient learning for bilingual ASR. This method selects those attention heads in a model which closely express language identities and then guided those heads to be correctly attended with their corresponding languages. The experiments on the Mandarin-English code-switching speech corpus show that the proposed approach achieves a 14.2% mixed error rate, surpassing state-of-the-art method, where only 5.6% additional parameters over Whisper are trained.
Performance Assessment of ChatGPT vs Bard in Detecting Alzheimer's Dementia
Jan 30, 2024Large language models (LLMs) find increasing applications in many fields. Here, three LLM chatbots (ChatGPT-3.5, ChatGPT-4 and Bard) are assessed - in their current form, as publicly available - for their ability to recognize Alzheimer's Dementia (AD) and Cognitively Normal (CN) individuals using textual input derived from spontaneous speech recordings. Zero-shot learning approach is used at two levels of independent queries, with the second query (chain-of-thought prompting) eliciting more detailed than the first. Each LLM chatbot's performance is evaluated on the prediction generated in terms of accuracy, sensitivity, specificity, precision and F1 score. LLM chatbots generated three-class outcome ("AD", "CN", or "Unsure"). When positively identifying AD, Bard produced highest true-positives (89% recall) and highest F1 score (71%), but tended to misidentify CN as AD, with high confidence (low "Unsure" rates); for positively identifying CN, GPT-4 resulted in the highest true-negatives at 56% and highest F1 score (62%), adopting a diplomatic stance (moderate "Unsure" rates). Overall, three LLM chatbots identify AD vs CN surpassing chance-levels but do not currently satisfy clinical application.
Embedding-based search in JetBrains IDEs
Jan 26, 2024Most modern Integrated Development Environments (IDEs) and code editors have a feature to search across available functionality and items in an open project. In JetBrains IDEs, this feature is called Search Everywhere: it allows users to search for files, actions, classes, symbols, settings, and anything from VCS history from a single entry point. However, it works with the candidates obtained by algorithms that don't account for semantics, e.g., synonyms, complex word permutations, part of the speech modifications, and typos. In this work, we describe the machine learning approach we implemented to improve the discoverability of search items. We also share the obstacles encountered during this process and how we overcame them.
A RAG-based Question Answering System Proposal for Understanding Islam: MufassirQAS LLM
Jan 31, 2024There exist challenges in learning and understanding religions as the presence of complexity and depth of religious doctrines and teachings. Chatbots as question-answering systems can help in solving these challenges. LLM chatbots use NLP techniques to establish connections between topics and accurately respond to complex questions. These capabilities make it perfect to be used in enlightenment on religion as a question answering chatbot. However, LLMs also have a tendency to generate false information, known as hallucination. The responses of the chatbots can include content that insults personal religious beliefs, interfaith conflicts, and controversial or sensitive topics. It needs to avoid such cases without promoting hate speech or offending certain groups of people or their beliefs. This study uses a vector database-based Retrieval Augmented Generation (RAG) approach to enhance the accuracy and transparency of LLMs. Our question-answering system is called as "MufassirQAS". We created a vector database with several open-access books that include Turkish context. These are Turkish translations, and interpretations on Islam. We worked on creating system prompts with care, ensuring they provide instructions that prevent harmful, offensive, or disrespectful responses. We also tested the MufassirQAS and ChatGPT with sensitive questions. We got better performance with our system. Study and enhancements are still in progress. Results and future works are given.