 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAM: Prompting Audio-Language Models for Audio Quality Assessment
Feb 01, 2024



While audio quality is a key performance metric for various audio processing tasks, including generative modeling, its objective measurement remains a challenge. Audio-Language Models (ALMs) are pre-trained on audio-text pairs that may contain information about audio quality, the presence of artifacts, or noise. Given an audio input and a text prompt related to quality, an ALM can be used to calculate a similarity score between the two. Here, we exploit this capability and introduce PAM, a no-reference metric for assessing audio quality for different audio processing tasks. Contrary to other "reference-free" metrics, PAM does not require computing embeddings on a reference dataset nor training a task-specific model on a costly set of human listening scores. We extensively evaluate the reliability of PAM against established metrics and human listening scores on four tasks: text-to-audio (TTA), text-to-music generation (TTM), text-to-speech (TTS), and deep noise suppression (DNS). We perform multiple ablation studies with controlled distortions, in-the-wild setups, and prompt choices. Our evaluation shows that PAM correlates well with existing metrics and human listening scores. These results demonstrate the potential of ALMs for computing a general-purpose audio quality metric.
Bilingual Streaming ASR with Grapheme units and Auxiliary Monolingual Loss
Aug 11, 2023



We introduce a bilingual solution to support English as secondary locale for most primary locales in hybrid automatic speech recognition (ASR) settings. Our key developments constitute: (a) pronunciation lexicon with grapheme units instead of phone units, (b) a fully bilingual alignment model and subsequently bilingual streaming transformer model, (c) a parallel encoder structure with language identification (LID) loss, (d) parallel encoder with an auxiliary loss for monolingual projections. We conclude that in comparison to LID loss, our proposed auxiliary loss is superior in specializing the parallel encoders to respective monolingual locales, and that contributes to stronger bilingual learning. We evaluate our work on large-scale training and test tasks for bilingual Spanish (ES) and bilingual Italian (IT) applications. Our bilingual models demonstrate strong English code-mixing capability. In particular, the bilingual IT model improves the word error rate (WER) for a code-mix IT task from 46.5% to 13.8%, while also achieving a close parity (9.6%) with the monolingual IT model (9.5%) over IT tests.
CLAP: Learning Audio Concepts From Natural Language Supervision
Jun 09, 2022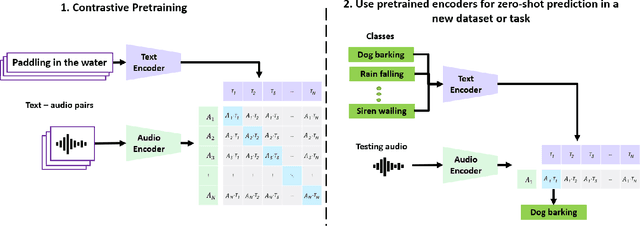
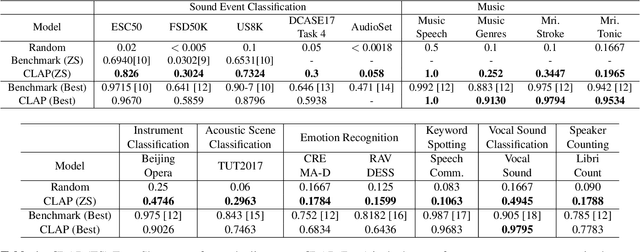
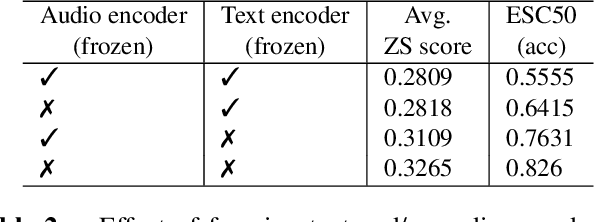
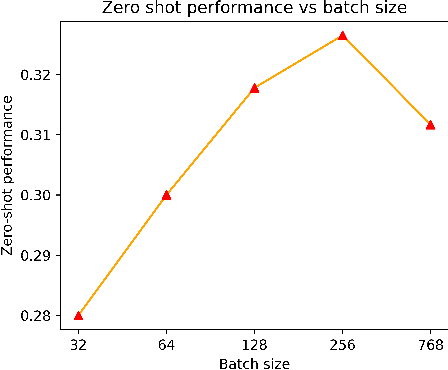
Mainstream Audio Analytics models are trained to learn under the paradigm of one class label to many recordings focusing on one task. Learning under such restricted supervision limits the flexibility of models because they require labeled audio for training and can only predict the predefined categories. Instead, we propose to learn audio concepts from natural language supervision. We call our approach Contrastive Language-Audio Pretraining (CLAP), which learns to connect language and audio by using two encoders and a contrastive learning to bring audio and text descriptions into a joint multimodal space. We trained CLAP with 128k audio and text pairs and evaluated it on 16 downstream tasks across 8 domains, such as Sound Event Classification, Music tasks, and Speech-related tasks. Although CLAP was trained with significantly less pairs than similar computer vision models, it establishes SoTA for Zero-Shot performance. Additionally, we evaluated CLAP in a supervised learning setup and achieve SoTA in 5 tasks. Hence, CLAP's Zero-Shot capability removes the need of training with class labels, enables flexible class prediction at inference time, and generalizes to multiple downstream tasks.
Interpreting glottal flow dynamics for detecting COVID-19 from voice
Oct 29, 2020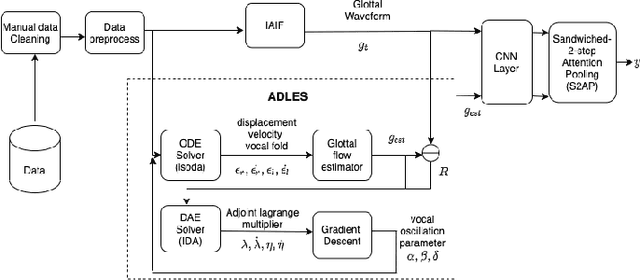
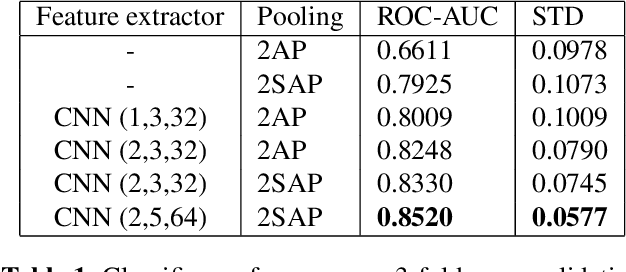
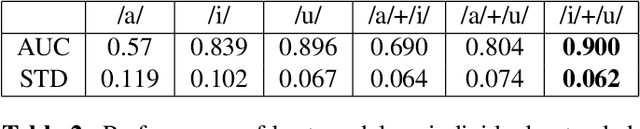
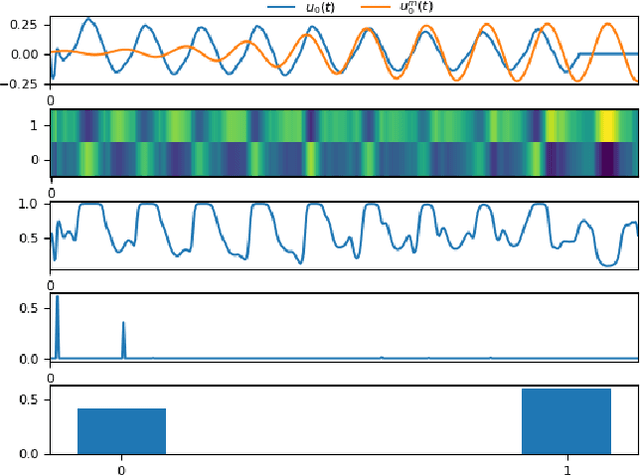
In the pathogenesis of COVID-19, impairment of respiratory functions is often one of the key symptoms. Studies show that in these cases, voice production is also adversely affected -- vocal fold oscillations are asynchronous, asymmetrical and more restricted during phonation. This paper proposes a method that analyzes the differential dynamics of the glottal flow waveform (GFW) during voice production to identify features in them that are most significant for the detection of COVID-19 from voice. Since it is hard to measure this directly in COVID-19 patients, we infer it from recorded speech signals and compare it to the GFW computed from physical model of phonation. For normal voices, the difference between the two should be minimal, since physical models are constructed to explain phonation under assumptions of normalcy. Greater differences implicate anomalies in the bio-physical factors that contribute to the correctness of the physical model, revealing their significance indirectly. Our proposed method uses a CNN-based 2-step attention model that locates anomalies in time-feature space in the difference of the two GFWs, allowing us to infer their potential as discriminative features for classification. The viability of this method is demonstrated using a clinically curated dataset of COVID-19 positive and negative subjects.
Detection of COVID-19 through the analysis of vocal fold oscillations
Oct 21, 2020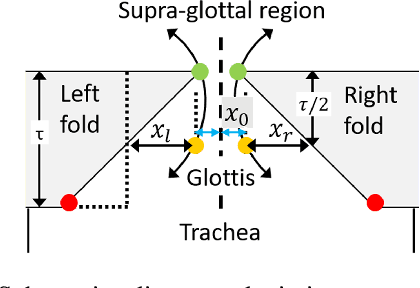
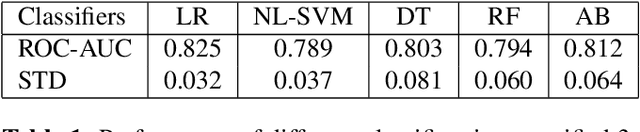

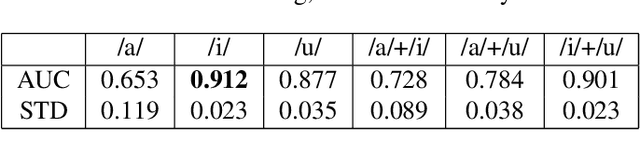
Phonation, or the vibration of the vocal folds, is the primary source of vocalization in the production of voiced sounds by humans. It is a complex bio-mechanical process that is highly sensitive to changes in the speaker's respiratory parameters. Since most symptomatic cases of COVID-19 present with moderate to severe impairment of respiratory functions, we hypothesize that signatures of COVID-19 may be observable by examining the vibrations of the vocal folds. Our goal is to validate this hypothesis, and to quantitatively characterize the changes observed to enable the detection of COVID-19 from voice. For this, we use a dynamical system model for the oscillation of the vocal folds, and solve it using our recently developed ADLES algorithm to yield vocal fold oscillation patterns directly from recorded speech. Experimental results on a clinically curated dataset of COVID-19 positive and negative subjects reveal characteristic patterns of vocal fold oscillations that are correlated with COVID-19. We show that these are prominent and discriminative enough that even simple classifiers such as logistic regression yields high detection accuracies using just the recordings of isolated extended vowels.
Disjoint Mapping Network for Cross-modal Matching of Voices and Faces
Jul 16, 2018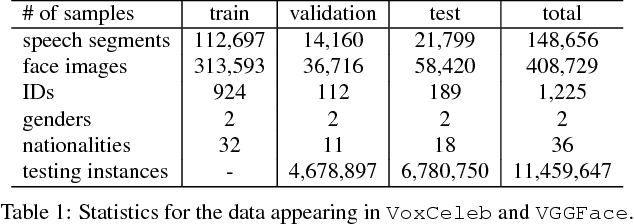
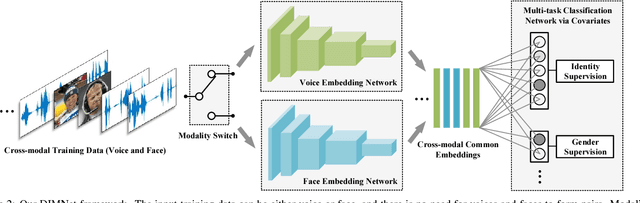
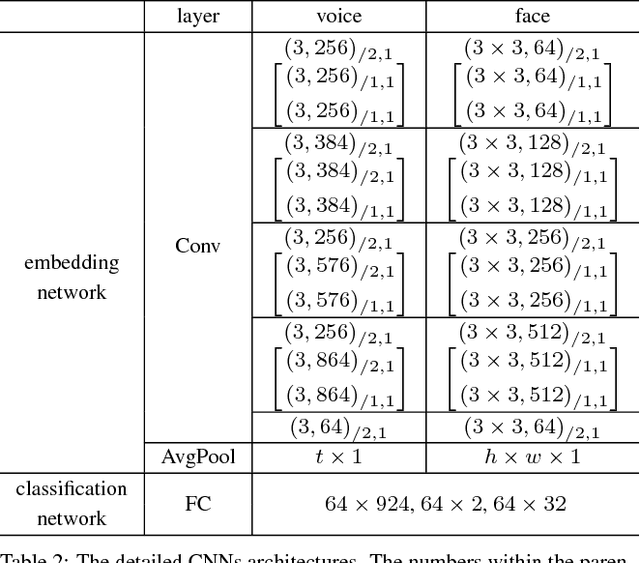
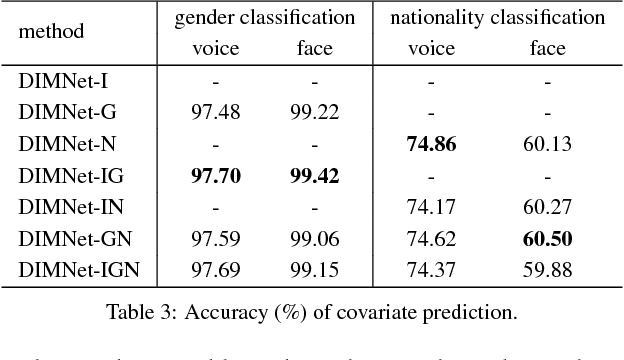
We propose a novel framework, called Disjoint Mapping Network (DIMNet), for cross-modal biometric matching, in particular of voices and faces. Different from the existing methods, DIMNet does not explicitly learn the joint relationship between the modalities. Instead, DIMNet learns a shared representation for different modalities by mapping them individually to their common covariates. These shared representations can then be used to find the correspondences between the modalities. We show empirically that DIMNet is able to achieve better performance than other current methods, with the additional benefits of being conceptually simpler and less data-intensive.
Optimal Strategies for Matching and Retrieval Problems by Comparing Covariates
Jul 16, 2018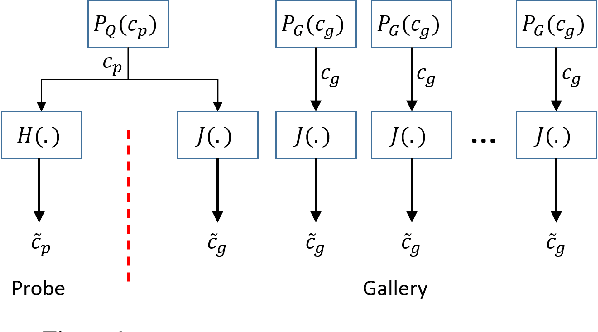
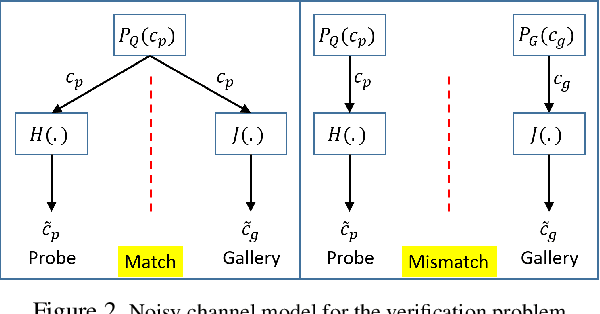
In many retrieval problems, where we must retrieve one or more entries from a gallery in response to a probe, it is common practice to learn to do by directly comparing the probe and gallery entries to one another. In many situations the gallery and probe have common covariates -- external variables that are common to both. In principle it is possible to perform the retrieval based merely on these covariates. The process, however, becomes gated by our ability to recognize the covariates for the probe and gallery entries correctly. In this paper we analyze optimal strategies for retrieval based only on matching covariates, when the recognition of the covariates is itself inaccurate. We investigate multiple problems: recovering one item from a gallery of $N$ entries, matching pairs of instances, and retrieval from large collections. We verify our analytical formulae through experiments to verify their correctness in practical settings.