 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Learning Audio-Text Agreement for Open-vocabulary Keyword Spotting
Jun 30, 2022
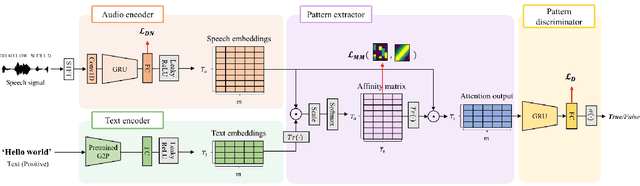
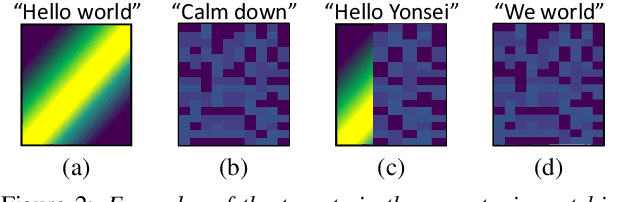

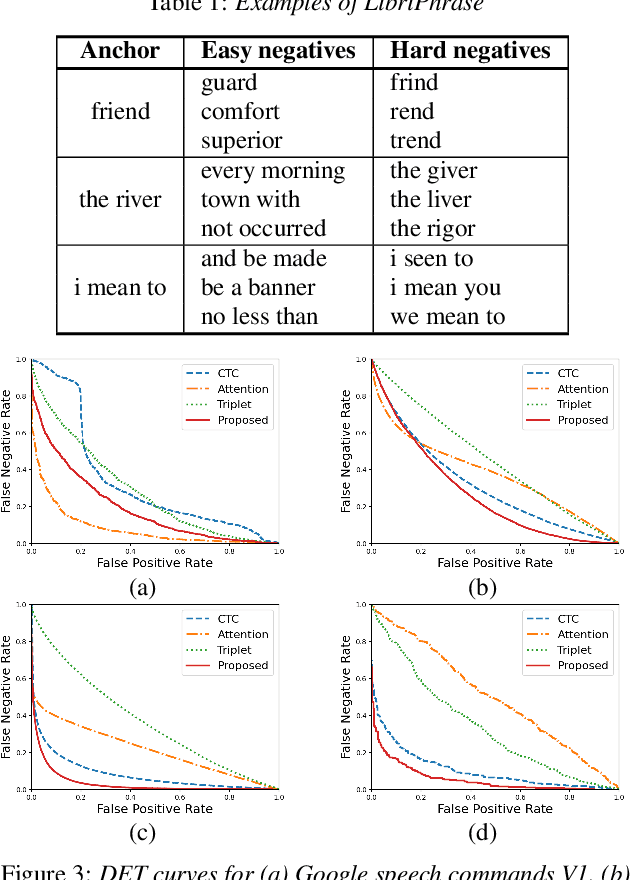
In this paper, we propose a novel end-to-end user-defined keyword spotting method that utilizes linguistically corresponding patterns between speech and text sequences. Unlike previous approaches requiring speech keyword enrollment, our method compares input queries with an enrolled text keyword sequence. To place the audio and text representations within a common latent space, we adopt an attention-based cross-modal matching approach that is trained in an end-to-end manner with monotonic matching loss and keyword classification loss. We also utilize a de-noising loss for the acoustic embedding network to improve robustness in noisy environments. Additionally, we introduce the LibriPhrase dataset, a new short-phrase dataset based on LibriSpeech for efficiently training keyword spotting models. Our proposed method achieves competitive results on various evaluation sets compared to other single-modal and cross-modal baselines.
Dual-decoder Transformer for Joint Automatic Speech Recognition and Multilingual Speech Translation
Nov 02, 2020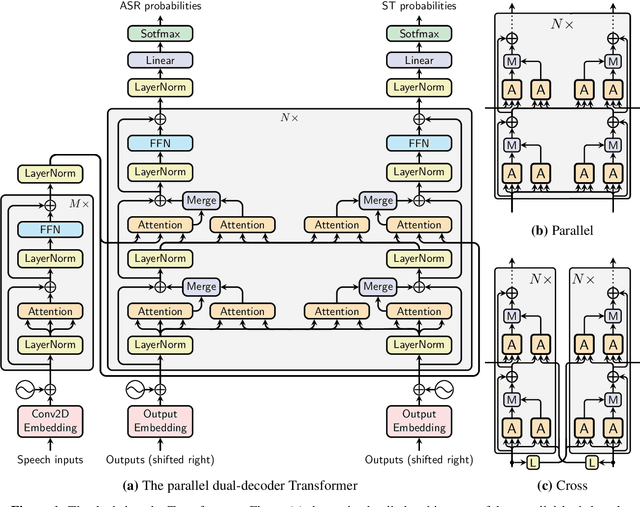
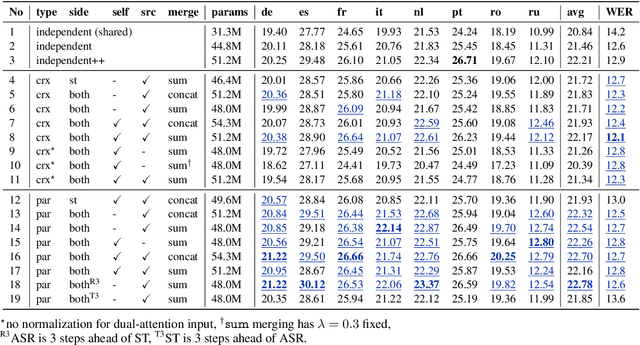
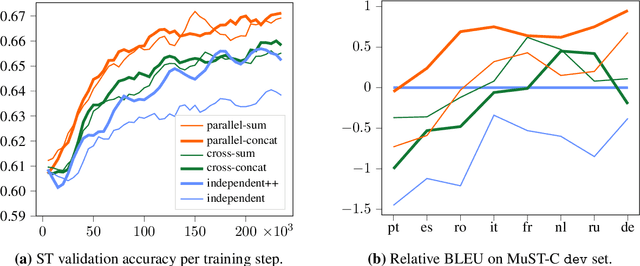
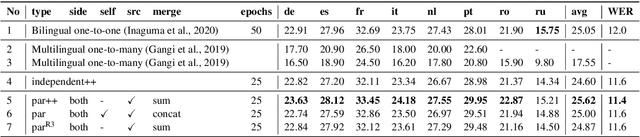
We introduce dual-decoder Transformer, a new model architecture that jointly performs automatic speech recognition (ASR) and multilingual speech translation (ST). Our models are based on the original Transformer architecture (Vaswani et al., 2017) but consist of two decoders, each responsible for one task (ASR or ST). Our major contribution lies in how these decoders interact with each other: one decoder can attend to different information sources from the other via a dual-attention mechanism. We propose two variants of these architectures corresponding to two different levels of dependencies between the decoders, called the parallel and cross dual-decoder Transformers, respectively. Extensive experiments on the MuST-C dataset show that our models outperform the previously-reported highest translation performance in the multilingual settings, and outperform as well bilingual one-to-one results. Furthermore, our parallel models demonstrate no trade-off between ASR and ST compared to the vanilla multi-task architecture. Our code and pre-trained models are available at https://github.com/formiel/speech-translation.
* Accepted at COLING 2020 (Oral)
Reinforcement Learning for Emotional Text-to-Speech Synthesis with Improved Emotion Discriminability
Apr 03, 2021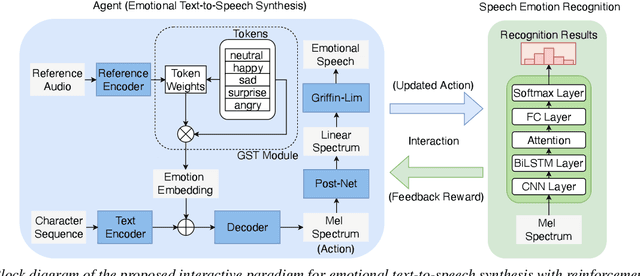

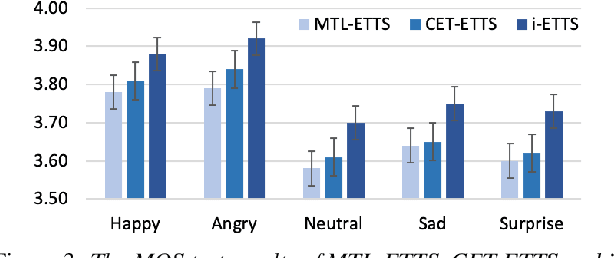
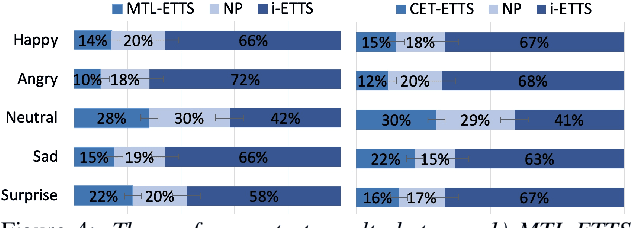
Emotional text-to-speech synthesis (ETTS) has seen much progress in recent years. However, the generated voice is often not perceptually identifiable by its intended emotion category. To address this problem, we propose a new interactive training paradigm for ETTS, denoted as i-ETTS, which seeks to directly improve the emotion discriminability by interacting with a speech emotion recognition (SER) model. Moreover, we formulate an iterative training strategy with reinforcement learning to ensure the quality of i-ETTS optimization. Experimental results demonstrate that the proposed i-ETTS outperforms the state-of-the-art baselines by rendering speech with more accurate emotion style. To our best knowledge, this is the first study of reinforcement learning in emotional text-to-speech synthesis.
AudioVisual Speech Synthesis: A brief literature review
Feb 18, 2021This brief literature review studies the problem of audiovisual speech synthesis, which is the problem of generating an animated talking head given a text as input. Due to the high complexity of this problem, we approach it as the composition of two problems. Specifically, that of Text-to-Speech (TTS) synthesis as well as the voice-driven talking head animation. For TTS, we present models that are used to map text to intermediate acoustic representations, e.g. mel-spectrograms, as well as models that generate voice signals conditioned on these intermediate representations, i.e vocoders. For the talking-head animation problem, we categorize approaches based on whether they produce human faces or anthropomorphic figures. An attempt is also made to discuss the importance of the choice of facial models in the second case. Throughout the review, we briefly describe the most important work in audiovisual speech synthesis, trying to highlight the advantages and disadvantages of the various approaches.
Learning with Limited Samples -- Meta-Learning and Applications to Communication Systems
Oct 03, 2022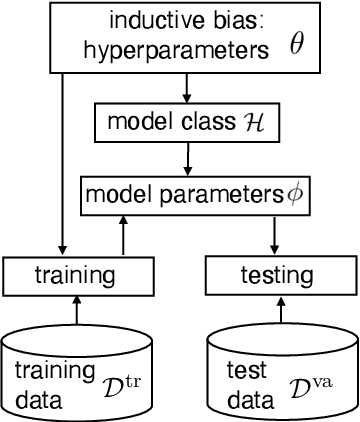
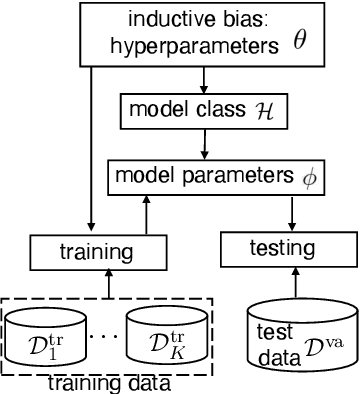
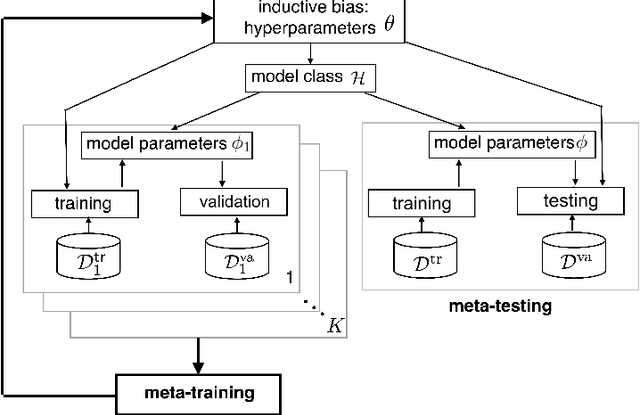
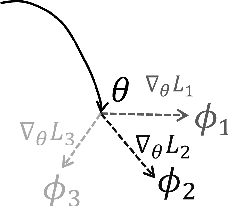
Deep learning has achieved remarkable success in many machine learning tasks such as image classification, speech recognition, and game playing. However, these breakthroughs are often difficult to translate into real-world engineering systems because deep learning models require a massive number of training samples, which are costly to obtain in practice. To address labeled data scarcity, few-shot meta-learning optimizes learning algorithms that can efficiently adapt to new tasks quickly. While meta-learning is gaining significant interest in the machine learning literature, its working principles and theoretic fundamentals are not as well understood in the engineering community. This review monograph provides an introduction to meta-learning by covering principles, algorithms, theory, and engineering applications. After introducing meta-learning in comparison with conventional and joint learning, we describe the main meta-learning algorithms, as well as a general bilevel optimization framework for the definition of meta-learning techniques. Then, we summarize known results on the generalization capabilities of meta-learning from a statistical learning viewpoint. Applications to communication systems, including decoding and power allocation, are discussed next, followed by an introduction to aspects related to the integration of meta-learning with emerging computing technologies, namely neuromorphic and quantum computing. The monograph is concluded with an overview of open research challenges.
A Database for Research on Detection and Enhancement of Speech Transmitted over HF links
Jun 16, 2021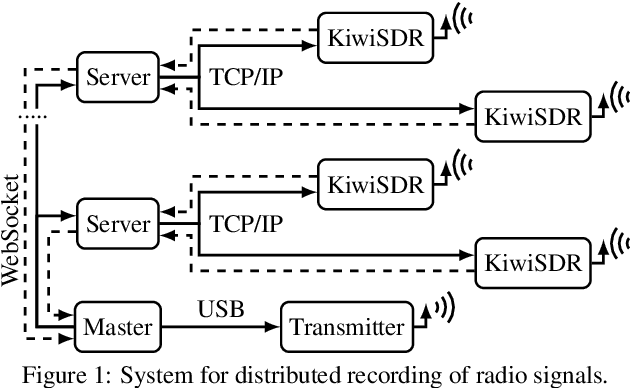
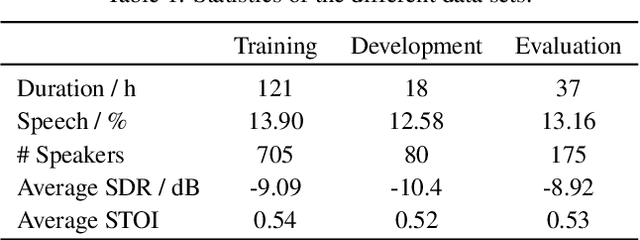

In this paper we present an open database for the development of detection and enhancement algorithms of speech transmitted over HF radio channels. It consists of audio samples recorded by various receivers at different locations across Europe, all monitoring the same single-sideband modulated transmission from a base station in Paderborn, Germany. Transmitted and received speech signals are precisely time aligned to offer parallel data for supervised training of deep learning based detection and enhancement algorithms. For the task of speech activity detection two exemplary baseline systems are presented, one based on statistical methods employing a multi-stage Wiener filter with minimum statistics noise floor estimation, and the other relying on a deep learning approach.
Improving Speech Translation by Understanding and Learning from the Auxiliary Text Translation Task
Jul 12, 2021
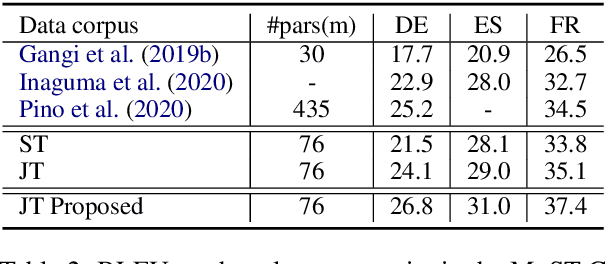
Pretraining and multitask learning are widely used to improve the speech to text translation performance. In this study, we are interested in training a speech to text translation model along with an auxiliary text to text translation task. We conduct a detailed analysis to understand the impact of the auxiliary task on the primary task within the multitask learning framework. Our analysis confirms that multitask learning tends to generate similar decoder representations from different modalities and preserve more information from the pretrained text translation modules. We observe minimal negative transfer effect between the two tasks and sharing more parameters is helpful to transfer knowledge from the text task to the speech task. The analysis also reveals that the modality representation difference at the top decoder layers is still not negligible, and those layers are critical for the translation quality. Inspired by these findings, we propose three methods to improve translation quality. First, a parameter sharing and initialization strategy is proposed to enhance information sharing between the tasks. Second, a novel attention-based regularization is proposed for the encoders and pulls the representations from different modalities closer. Third, an online knowledge distillation is proposed to enhance the knowledge transfer from the text to the speech task. Our experiments show that the proposed approach improves translation performance by more than 2 BLEU over a strong baseline and achieves state-of-the-art results on the \textsc{MuST-C} English-German, English-French and English-Spanish language pairs.
Combining Frame-Synchronous and Label-Synchronous Systems for Speech Recognition
Jul 01, 2021
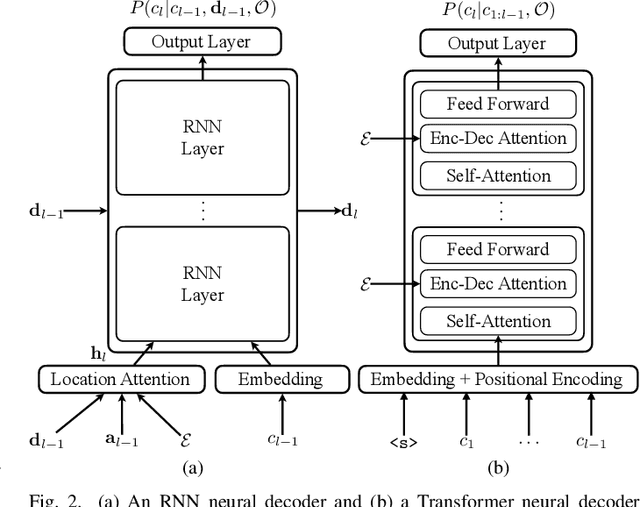
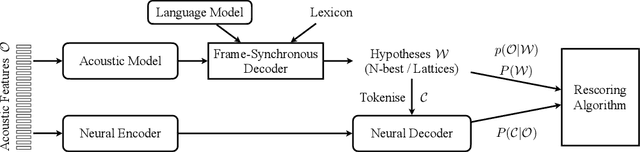
Commonly used automatic speech recognition (ASR) systems can be classified into frame-synchronous and label-synchronous categories, based on whether the speech is decoded on a per-frame or per-label basis. Frame-synchronous systems, such as traditional hidden Markov model systems, can easily incorporate existing knowledge and can support streaming ASR applications. Label-synchronous systems, based on attention-based encoder-decoder models, can jointly learn the acoustic and language information with a single model, which can be regarded as audio-grounded language models. In this paper, we propose rescoring the N-best hypotheses or lattices produced by a first-pass frame-synchronous system with a label-synchronous system in a second-pass. By exploiting the complementary modelling of the different approaches, the combined two-pass systems achieve competitive performance without using any extra speech or text data on two standard ASR tasks. For the 80-hour AMI IHM dataset, the combined system has a 13.7% word error rate (WER) on the evaluation set, which is up to a 29% relative WER reduction over the individual systems. For the 300-hour Switchboard dataset, the WERs of the combined system are 5.7% and 12.1% on Switchboard and CallHome subsets of Hub5'00, and 13.2% and 7.6% on Switchboard Cellular and Fisher subsets of RT03, up to a 33% relative reduction in WER over the individual systems.
Adversarial and Safely Scaled Question Generation
Oct 17, 2022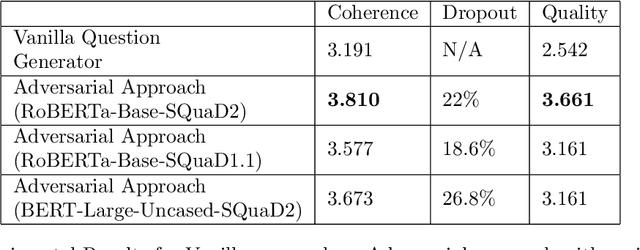
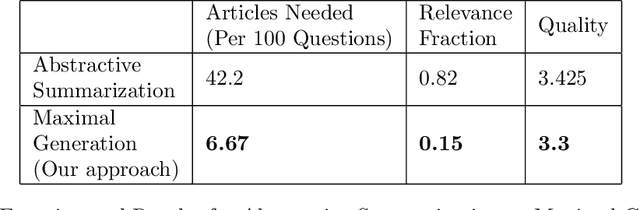
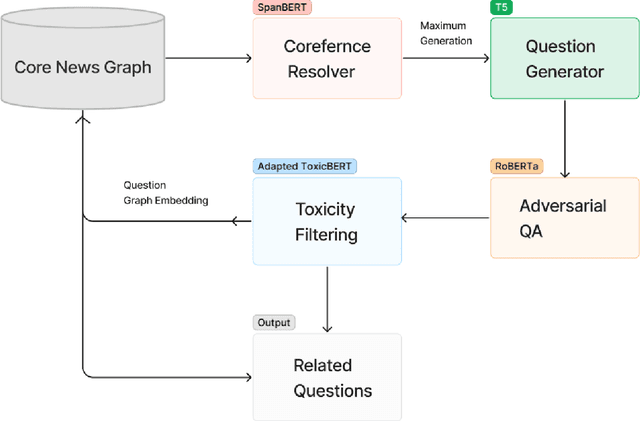
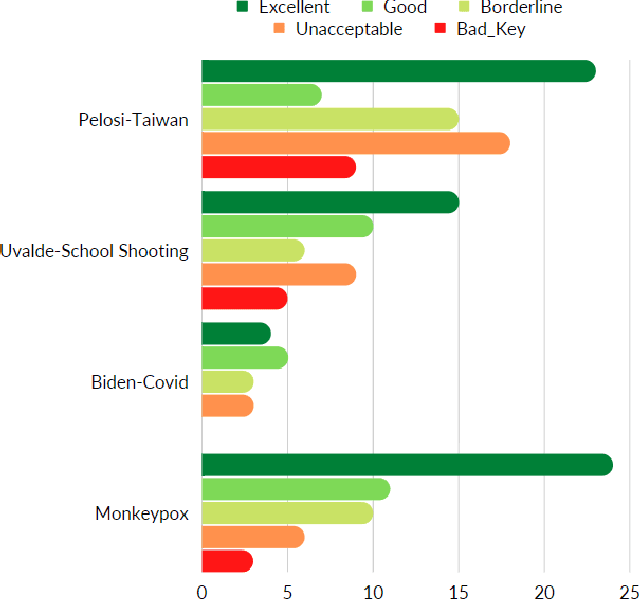
Question generation has recently gained a lot of research interest, especially with the advent of large language models. In and of itself, question generation can be considered 'AI-hard', as there is a lack of unanimously agreed sense of what makes a question 'good' or 'bad'. In this paper, we tackle two fundamental problems in parallel: on one hand, we try to solve the scaling problem, where question-generation and answering applications have to be applied to a massive amount of text without ground truth labeling. The usual approach to solve this problem is to either downsample or summarize. However, there are critical risks of misinformation with these approaches. On the other hand, and related to the misinformation problem, we try to solve the 'safety' problem, as many public institutions rely on a much higher level of accuracy for the content they provide. We introduce an adversarial approach to tackle the question generation safety problem with scale. Specifically, we designed a question-answering system that specifically prunes out unanswerable questions that may be generated, and further increases the quality of the answers that are generated. We build a production-ready, easily-plugged pipeline that can be used on any given body of text, that is scalable and immune from generating any hate speech, profanity, or misinformation. Based on the results, we are able to generate more than six times the number of quality questions generated by the abstractive approach, with a perceived quality being 44% higher, according to a survey of 168 participants.
Continuous Pseudo-Labeling from the Start
Oct 17, 2022
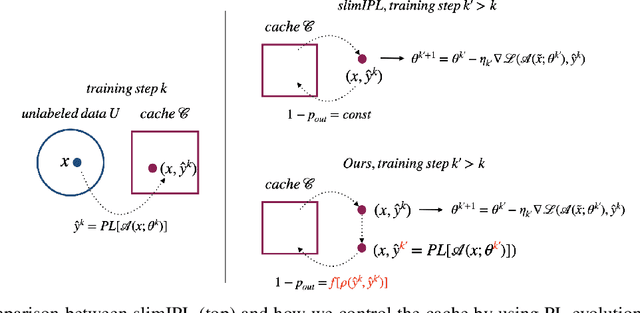
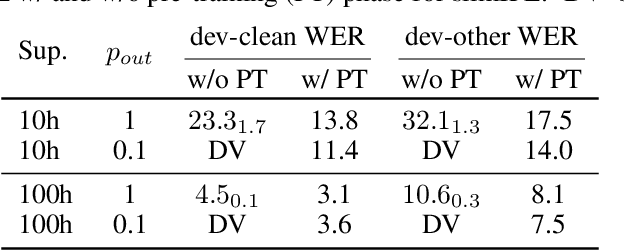
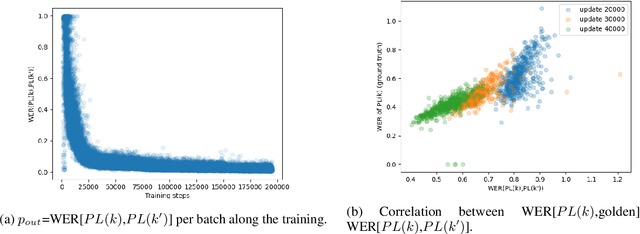
Self-training (ST), or pseudo-labeling has sparked significant interest in the automatic speech recognition (ASR) community recently because of its success in harnessing unlabeled data. Unlike prior semi-supervised learning approaches that relied on iteratively regenerating pseudo-labels (PLs) from a trained model and using them to train a new model, recent state-of-the-art methods perform `continuous training' where PLs are generated using a very recent version of the model being trained. Nevertheless, these approaches still rely on bootstrapping the ST using an initial supervised learning phase where the model is trained on labeled data alone. We believe this has the potential for over-fitting to the labeled dataset in low resource settings and that ST from the start of training should reduce over-fitting. In this paper we show how we can do this by dynamically controlling the evolution of PLs during the training process in ASR. To the best of our knowledge, this is the first study that shows the feasibility of generating PLs from the very start of the training. We are able to achieve this using two techniques that avoid instabilities which lead to degenerate models that do not generalize. Firstly, we control the evolution of PLs through a curriculum that uses the online changes in PLs to control the membership of the cache of PLs and improve generalization. Secondly, we find that by sampling transcriptions from the predictive distribution, rather than only using the best transcription, we can stabilize training further. With these techniques, our ST models match prior works without an external language model.