 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Intra-Speaker Variability in Diarization with Style-Controllable Speech Augmentation
Sep 18, 2025Speaker diarization systems often struggle with high intrinsic intra-speaker variability, such as shifts in emotion, health, or content. This can cause segments from the same speaker to be misclassified as different individuals, for example, when one raises their voice or speaks faster during conversation. To address this, we propose a style-controllable speech generation model that augments speech across diverse styles while preserving the target speaker's identity. The proposed system starts with diarized segments from a conventional diarizer. For each diarized segment, it generates augmented speech samples enriched with phonetic and stylistic diversity. And then, speaker embeddings from both the original and generated audio are blended to enhance the system's robustness in grouping segments with high intrinsic intra-speaker variability. We validate our approach on a simulated emotional speech dataset and the truncated AMI dataset, demonstrating significant improvements, with error rate reductions of 49% and 35% on each dataset, respectively.
Learning Audio-Text Agreement for Open-vocabulary Keyword Spotting
Jul 01, 2022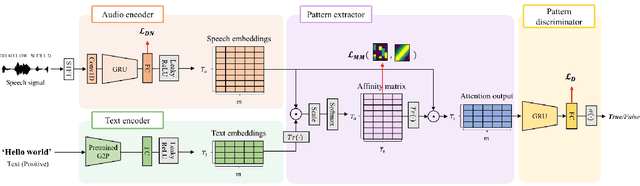
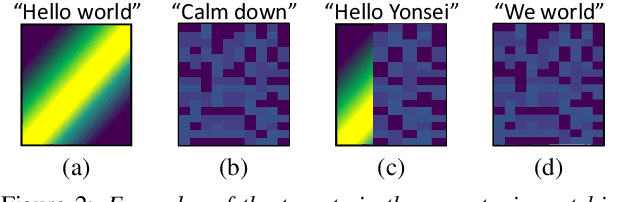

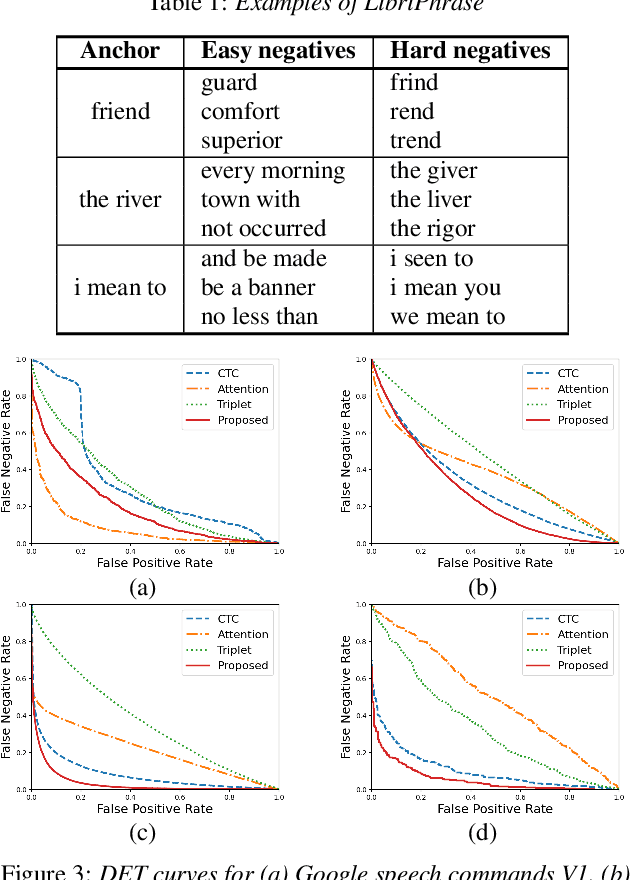
In this paper, we propose a novel end-to-end user-defined keyword spotting method that utilizes linguistically corresponding patterns between speech and text sequences. Unlike previous approaches requiring speech keyword enrollment, our method compares input queries with an enrolled text keyword sequence. To place the audio and text representations within a common latent space, we adopt an attention-based cross-modal matching approach that is trained in an end-to-end manner with monotonic matching loss and keyword classification loss. We also utilize a de-noising loss for the acoustic embedding network to improve robustness in noisy environments. Additionally, we introduce the LibriPhrase dataset, a new short-phrase dataset based on LibriSpeech for efficiently training keyword spotting models. Our proposed method achieves competitive results on various evaluation sets compared to other single-modal and cross-modal baselines.
Phase Continuity: Learning Derivatives of Phase Spectrum for Speech Enhancement
Feb 24, 2022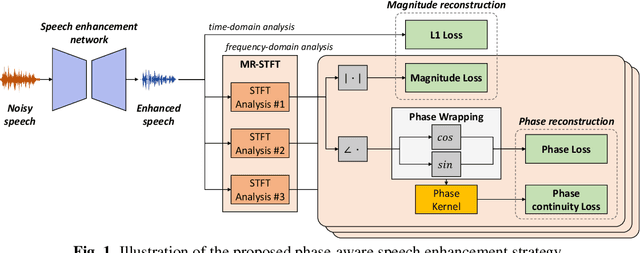
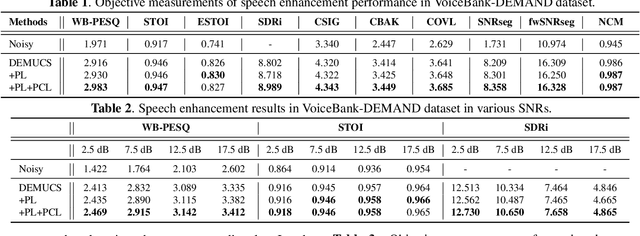
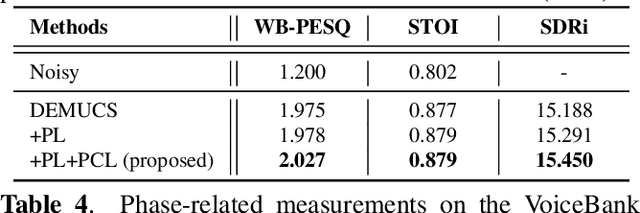
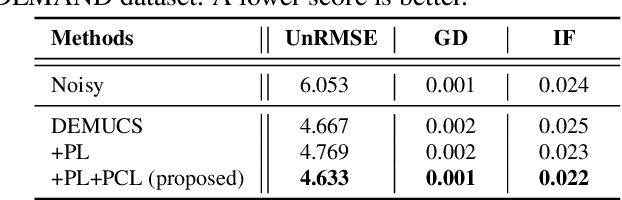
Modern neural speech enhancement models usually include various forms of phase information in their training loss terms, either explicitly or implicitly. However, these loss terms are typically designed to reduce the distortion of phase spectrum values at specific frequencies, which ensures they do not significantly affect the quality of the enhanced speech. In this paper, we propose an effective phase reconstruction strategy for neural speech enhancement that can operate in noisy environments. Specifically, we introduce a phase continuity loss that considers relative phase variations across the time and frequency axes. By including this phase continuity loss in a state-of-the-art neural speech enhancement system trained with reconstruction loss and a number of magnitude spectral losses, we show that our proposed method further improves the quality of enhanced speech signals over the baseline, especially when training is done jointly with a magnitude spectrum loss.