 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEDUSA: A Multimodal Deep Fusion Multi-Stage Training Framework for Speech Emotion Recognition in Naturalistic Conditions
Jun 11, 2025SER is a challenging task due to the subjective nature of human emotions and their uneven representation under naturalistic conditions. We propose MEDUSA, a multimodal framework with a four-stage training pipeline, which effectively handles class imbalance and emotion ambiguity. The first two stages train an ensemble of classifiers that utilize DeepSER, a novel extension of a deep cross-modal transformer fusion mechanism from pretrained self-supervised acoustic and linguistic representations. Manifold MixUp is employed for further regularization. The last two stages optimize a trainable meta-classifier that combines the ensemble predictions. Our training approach incorporates human annotation scores as soft targets, coupled with balanced data sampling and multitask learning. MEDUSA ranked 1st in Task 1: Categorical Emotion Recognition in the Interspeech 2025: Speech Emotion Recognition in Naturalistic Conditions Challenge.
Krikri: Advancing Open Large Language Models for Greek
May 19, 2025



We introduce Llama-Krikri-8B, a cutting-edge Large Language Model tailored for the Greek language, built on Meta's Llama 3.1-8B. Llama-Krikri-8B has been extensively trained on high-quality Greek data to ensure superior adaptation to linguistic nuances. With 8 billion parameters, it offers advanced capabilities while maintaining efficient computational performance. Llama-Krikri-8B supports both Modern Greek and English, and is also equipped to handle polytonic text and Ancient Greek. The chat version of Llama-Krikri-8B features a multi-stage post-training pipeline, utilizing both human and synthetic instruction and preference data, by applying techniques such as MAGPIE. In addition, for evaluation, we propose three novel public benchmarks for Greek. Our evaluation on existing as well as the proposed benchmarks shows notable improvements over comparable Greek and multilingual LLMs in both natural language understanding and generation as well as code generation.
A Transformer-Based Framework for Greek Sign Language Production using Extended Skeletal Motion Representations
Mar 04, 2025Sign Languages are the primary form of communication for Deaf communities across the world. To break the communication barriers between the Deaf and Hard-of-Hearing and the hearing communities, it is imperative to build systems capable of translating the spoken language into sign language and vice versa. Building on insights from previous research, we propose a deep learning model for Sign Language Production (SLP), which to our knowledge is the first attempt on Greek SLP. We tackle this task by utilizing a transformer-based architecture that enables the translation from text input to human pose keypoints, and the opposite. We evaluate the effectiveness of the proposed pipeline on the Greek SL dataset Elementary23, through a series of comparative analyses and ablation studies. Our pipeline's components, which include data-driven gloss generation, training through video to text translation and a scheduling algorithm for teacher forcing - auto-regressive decoding seem to actively enhance the quality of produced SL videos.
Meltemi: The first open Large Language Model for Greek
Jul 30, 2024



We describe the development and capabilities of Meltemi 7B, the first open Large Language Model for the Greek language. Meltemi 7B has 7 billion parameters and is trained on a 40 billion token Greek corpus. For the development of Meltemi 7B, we adapt Mistral, by continuous pretraining on the Greek Corpus. Meltemi 7B contains up-to-date information up to September 2023. Furthermore, we have translated and curated a Greek instruction corpus, which has been used for the instruction-tuning of a chat model, named Meltemi 7B Instruct. Special care has been given to the alignment and the removal of toxic content for the Meltemi 7B Instruct. The developed models are evaluated on a broad set of collected evaluation corpora, and examples of prompts and responses are presented. Both Meltemi 7B and Meltemi 7B Instruct are available at https://huggingface.co/ilsp under the Apache 2.0 license.
The Greek podcast corpus: Competitive speech models for low-resourced languages with weakly supervised data
Jun 21, 2024



The development of speech technologies for languages with limited digital representation poses significant challenges, primarily due to the scarcity of available data. This issue is exacerbated in the era of large, data-intensive models. Recent research has underscored the potential of leveraging weak supervision to augment the pool of available data. In this study, we compile an 800-hour corpus of Modern Greek from podcasts and employ Whisper large-v3 to generate silver transcriptions. This corpus is utilized to fine-tune our models, aiming to assess the efficacy of this approach in enhancing ASR performance. Our analysis spans 16 distinct podcast domains, alongside evaluations on established datasets for Modern Greek. The findings indicate consistent WER improvements, correlating with increases in both data volume and model size. Our study confirms that assembling large, weakly supervised corpora serves as a cost-effective strategy for advancing speech technologies in under-resourced languages.
Weakly-supervised forced alignment of disfluent speech using phoneme-level modeling
May 30, 2023



The study of speech disorders can benefit greatly from time-aligned data. However, audio-text mismatches in disfluent speech cause rapid performance degradation for modern speech aligners, hindering the use of automatic approaches. In this work, we propose a simple and effective modification of alignment graph construction of CTC-based models using Weighted Finite State Transducers. The proposed weakly-supervised approach alleviates the need for verbatim transcription of speech disfluencies for forced alignment. During the graph construction, we allow the modeling of common speech disfluencies, i.e. repetitions and omissions. Further, we show that by assessing the degree of audio-text mismatch through the use of Oracle Error Rate, our method can be effectively used in the wild. Our evaluation on a corrupted version of the TIMIT test set and the UCLASS dataset shows significant improvements, particularly for recall, achieving a 23-25% relative improvement over our baselines.
Efficient Audio Captioning Transformer with Patchout and Text Guidance
Apr 06, 2023Automated audio captioning is multi-modal translation task that aim to generate textual descriptions for a given audio clip. In this paper we propose a full Transformer architecture that utilizes Patchout as proposed in [1], significantly reducing the computational complexity and avoiding overfitting. The caption generation is partly conditioned on textual AudioSet tags extracted by a pre-trained classification model which is fine-tuned to maximize the semantic similarity between AudioSet labels and ground truth captions. To mitigate the data scarcity problem of Automated Audio Captioning we introduce transfer learning from an upstream audio-related task and an enlarged in-domain dataset. Moreover, we propose a method to apply Mixup augmentation for AAC. Ablation studies are carried out to investigate how Patchout and text guidance contribute to the final performance. The results show that the proposed techniques improve the performance of our system and while reducing the computational complexity. Our proposed method received the Judges Award at the Task6A of DCASE Challenge 2022.
Designing and Evaluating Speech Emotion Recognition Systems: A reality check case study with IEMOCAP
Apr 03, 2023


There is an imminent need for guidelines and standard test sets to allow direct and fair comparisons of speech emotion recognition (SER). While resources, such as the Interactive Emotional Dyadic Motion Capture (IEMOCAP) database, have emerged as widely-adopted reference corpora for researchers to develop and test models for SER, published work reveals a wide range of assumptions and variety in its use that challenge reproducibility and generalization. Based on a critical review of the latest advances in SER using IEMOCAP as the use case, our work aims at two contributions: First, using an analysis of the recent literature, including assumptions made and metrics used therein, we provide a set of SER evaluation guidelines. Second, using recent publications with open-sourced implementations, we focus on reproducibility assessment in SER.
Sample-Efficient Unsupervised Domain Adaptation of Speech Recognition Systems A case study for Modern Greek
Dec 31, 2022



Modern speech recognition systems exhibits rapid performance degradation under domain shift. This issue is especially prevalent in data-scarce settings, such as low-resource languages, where diversity of training data is limited. In this work we propose M2DS2, a simple and sample-efficient finetuning strategy for large pretrained speech models, based on mixed source and target domain self-supervision. We find that including source domain self-supervision stabilizes training and avoids mode collapse of the latent representations. For evaluation, we collect HParl, a $120$ hour speech corpus for Greek, consisting of plenary sessions in the Greek Parliament. We merge HParl with two popular Greek corpora to create GREC-MD, a test-bed for multi-domain evaluation of Greek ASR systems. In our experiments we find that, while other Unsupervised Domain Adaptation baselines fail in this resource-constrained environment, M2DS2 yields significant improvements for cross-domain adaptation, even when a only a few hours of in-domain audio are available. When we relax the problem in a weakly supervised setting, we find that independent adaptation for audio using M2DS2 and language using simple LM augmentation techniques is particularly effective, yielding word error rates comparable to the fully supervised baselines.
Visual Speech-Aware Perceptual 3D Facial Expression Reconstruction from Videos
Jul 22, 2022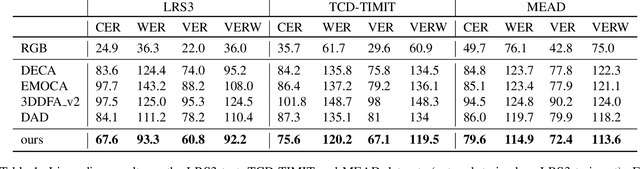
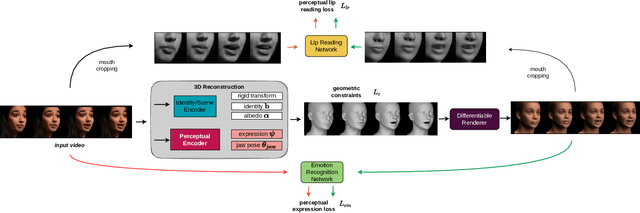


The recent state of the art on monocular 3D face reconstruction from image data has made some impressive advancements, thanks to the advent of Deep Learning. However, it has mostly focused on input coming from a single RGB image, overlooking the following important factors: a) Nowadays, the vast majority of facial image data of interest do not originate from single images but rather from videos, which contain rich dynamic information. b) Furthermore, these videos typically capture individuals in some form of verbal communication (public talks, teleconferences, audiovisual human-computer interactions, interviews, monologues/dialogues in movies, etc). When existing 3D face reconstruction methods are applied in such videos, the artifacts in the reconstruction of the shape and motion of the mouth area are often severe, since they do not match well with the speech audio. To overcome the aforementioned limitations, we present the first method for visual speech-aware perceptual reconstruction of 3D mouth expressions. We do this by proposing a "lipread" loss, which guides the fitting process so that the elicited perception from the 3D reconstructed talking head resembles that of the original video footage. We demonstrate that, interestingly, the lipread loss is better suited for 3D reconstruction of mouth movements compared to traditional landmark losses, and even direct 3D supervision. Furthermore, the devised method does not rely on any text transcriptions or corresponding audio, rendering it ideal for training in unlabeled datasets. We verify the efficiency of our method through exhaustive objective evaluations on three large-scale datasets, as well as subjective evaluation with two web-based user studies.