 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableQuant: Layer Adaptive Post-Training Quantization for Speech Foundation Models
Apr 21, 2025In this paper, we propose StableQuant, a novel adaptive post-training quantization (PTQ) algorithm for widely used speech foundation models (SFMs). While PTQ has been successfully employed for compressing large language models (LLMs) due to its ability to bypass additional fine-tuning, directly applying these techniques to SFMs may not yield optimal results, as SFMs utilize distinct network architecture for feature extraction. StableQuant demonstrates optimal quantization performance regardless of the network architecture type, as it adaptively determines the quantization range for each layer by analyzing both the scale distributions and overall performance. We evaluate our algorithm on two SFMs, HuBERT and wav2vec2.0, for an automatic speech recognition (ASR) task, and achieve superior performance compared to traditional PTQ methods. StableQuant successfully reduces the sizes of SFM models to a quarter and doubles the inference speed while limiting the word error rate (WER) performance drop to less than 0.3% with 8-bit quantization.
A cross-talk robust multichannel VAD model for multiparty agent interactions trained using synthetic re-recordings
Feb 15, 2024In this work, we propose a novel cross-talk rejection framework for a multi-channel multi-talker setup for a live multiparty interactive show. Our far-field audio setup is required to be hands-free during live interaction and comprises four adjacent talkers with directional microphones in the same space. Such setups often introduce heavy cross-talk between channels, resulting in reduced automatic speech recognition (ASR) and natural language understanding (NLU) performance. To address this problem, we propose voice activity detection (VAD) model for all talkers using multichannel information, which is then used to filter audio for downstream tasks. We adopt a synthetic training data generation approach through playback and re-recording for such scenarios, simulating challenging speech overlap conditions. We train our models on this synthetic data and demonstrate that our approach outperforms single-channel VAD models and energy-based multi-channel VAD algorithm in various acoustic environments. In addition to VAD results, we also present multiparty ASR evaluation results to highlight the impact of using our VAD model for filtering audio in downstream tasks by significantly reducing the insertion error.
HD-DEMUCS: General Speech Restoration with Heterogeneous Decoders
Jun 02, 2023



This paper introduces an end-to-end neural speech restoration model, HD-DEMUCS, demonstrating efficacy across multiple distortion environments. Unlike conventional approaches that employ cascading frameworks to remove undesirable noise first and then restore missing signal components, our model performs these tasks in parallel using two heterogeneous decoder networks. Based on the U-Net style encoder-decoder framework, we attach an additional decoder so that each decoder network performs noise suppression or restoration separately. We carefully design each decoder architecture to operate appropriately depending on its objectives. Additionally, we improve performance by leveraging a learnable weighting factor, aggregating the two decoder output waveforms. Experimental results with objective metrics across various environments clearly demonstrate the effectiveness of our approach over a single decoder or multi-stage systems for general speech restoration task.
Learning Audio-Text Agreement for Open-vocabulary Keyword Spotting
Jul 01, 2022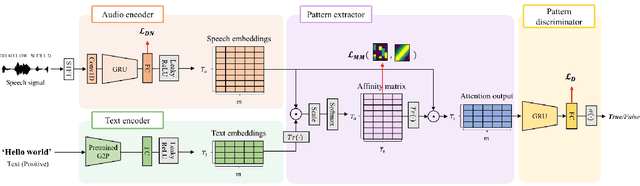
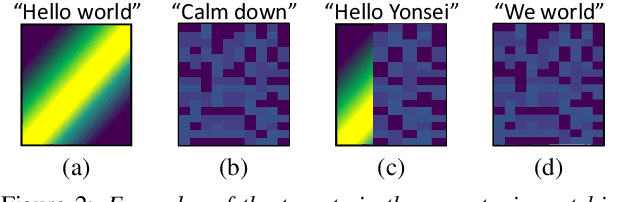

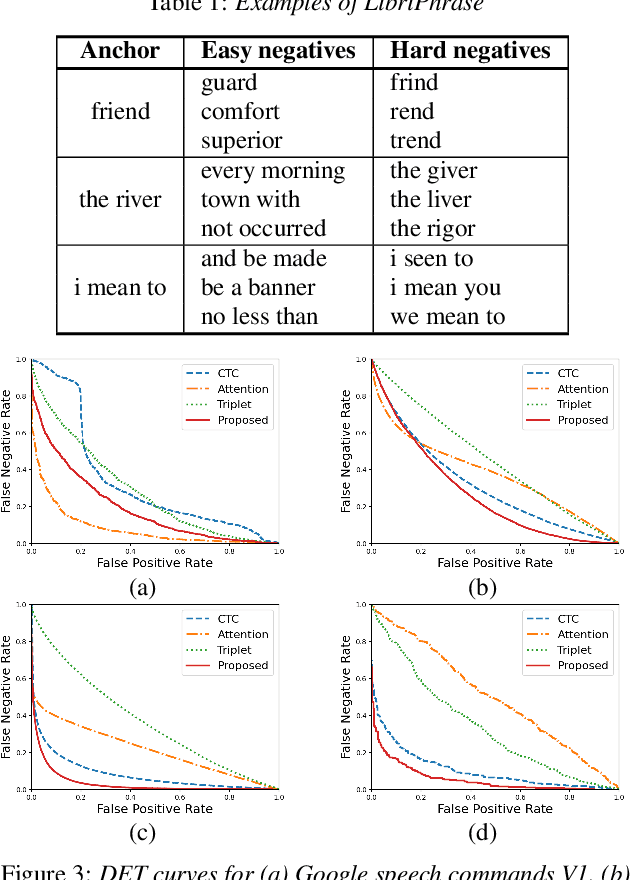
In this paper, we propose a novel end-to-end user-defined keyword spotting method that utilizes linguistically corresponding patterns between speech and text sequences. Unlike previous approaches requiring speech keyword enrollment, our method compares input queries with an enrolled text keyword sequence. To place the audio and text representations within a common latent space, we adopt an attention-based cross-modal matching approach that is trained in an end-to-end manner with monotonic matching loss and keyword classification loss. We also utilize a de-noising loss for the acoustic embedding network to improve robustness in noisy environments. Additionally, we introduce the LibriPhrase dataset, a new short-phrase dataset based on LibriSpeech for efficiently training keyword spotting models. Our proposed method achieves competitive results on various evaluation sets compared to other single-modal and cross-modal baselines.
Phase Continuity: Learning Derivatives of Phase Spectrum for Speech Enhancement
Feb 24, 2022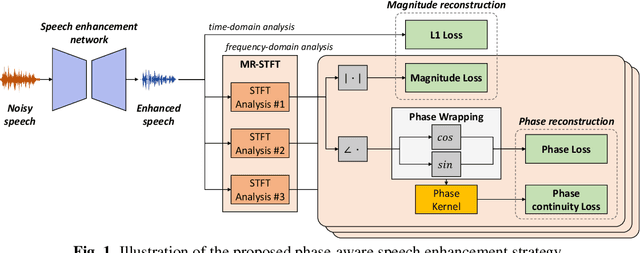
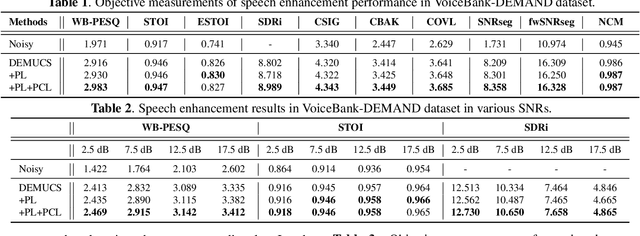
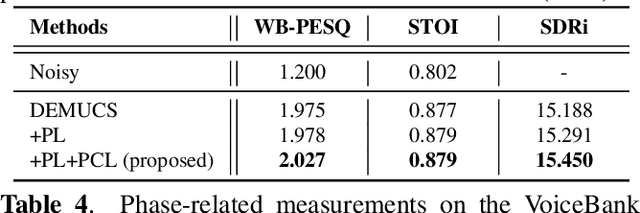
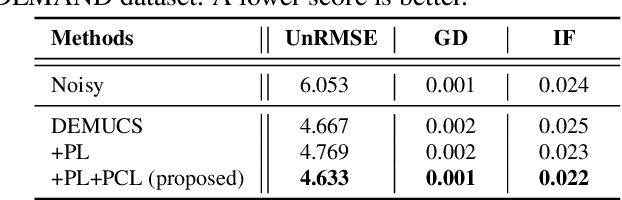
Modern neural speech enhancement models usually include various forms of phase information in their training loss terms, either explicitly or implicitly. However, these loss terms are typically designed to reduce the distortion of phase spectrum values at specific frequencies, which ensures they do not significantly affect the quality of the enhanced speech. In this paper, we propose an effective phase reconstruction strategy for neural speech enhancement that can operate in noisy environments. Specifically, we introduce a phase continuity loss that considers relative phase variations across the time and frequency axes. By including this phase continuity loss in a state-of-the-art neural speech enhancement system trained with reconstruction loss and a number of magnitude spectral losses, we show that our proposed method further improves the quality of enhanced speech signals over the baseline, especially when training is done jointly with a magnitude spectrum loss.