 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speech SIMCLR: Combining Contrastive and Reconstruction Objective for Self-supervised Speech Representation Learning
Oct 27, 2020
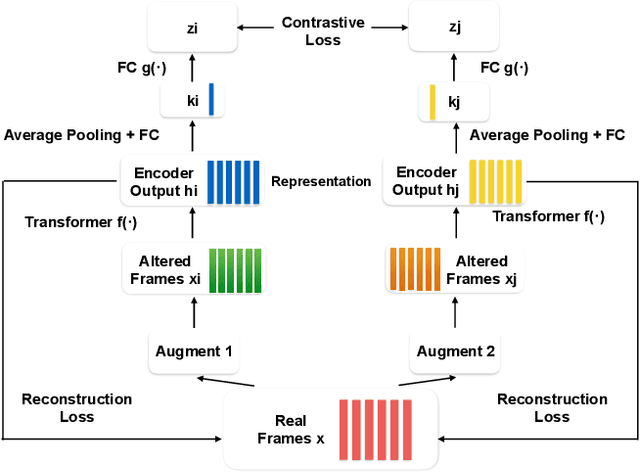

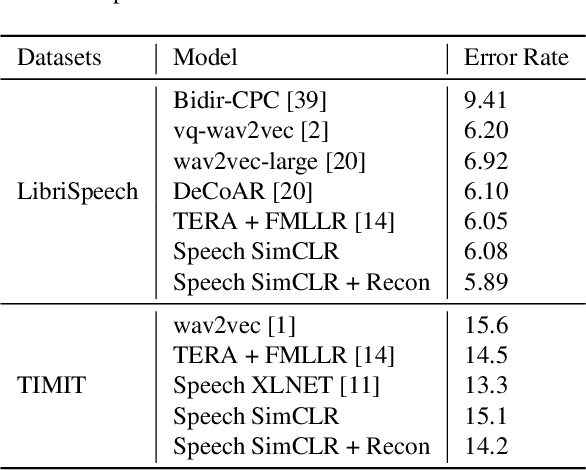

Self-supervised visual pretraining has shown significant progress recently. Among those methods, SimCLR greatly advanced the state of the art in self-supervised and semi-supervised learning on ImageNet. The input feature representations for speech and visual tasks are both continuous, so it is natural to consider applying similar objective on speech representation learning. In this paper, we propose Speech SimCLR, a new self-supervised objective for speech representation learning. During training, Speech SimCLR applies augmentation on raw speech and its spectrogram. Its objective is the combination of contrastive loss that maximizes agreement between differently augmented samples in the latent space and reconstruction loss of input representation. The proposed method achieved competitive results on speech emotion recognition and speech recognition. When used as feature extractor, our best model achieved 5.89% word error rate on LibriSpeech test-clean set using LibriSpeech 960 hours as pretraining data and LibriSpeech train-clean-100 set as fine-tuning data, which is the lowest error rate obtained in this setup to the best of our knowledge.
SoundChoice: Grapheme-to-Phoneme Models with Semantic Disambiguation
Jul 27, 2022
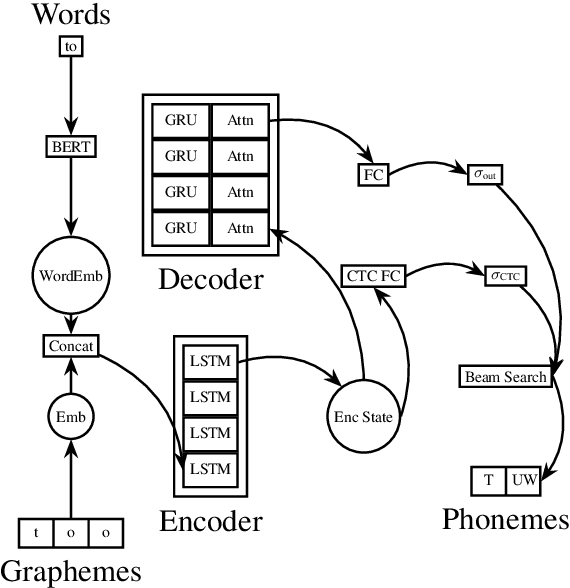

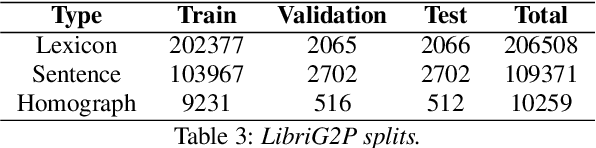
End-to-end speech synthesis models directly convert the input characters into an audio representation (e.g., spectrograms). Despite their impressive performance, such models have difficulty disambiguating the pronunciations of identically spelled words. To mitigate this issue, a separate Grapheme-to-Phoneme (G2P) model can be employed to convert the characters into phonemes before synthesizing the audio. This paper proposes SoundChoice, a novel G2P architecture that processes entire sentences rather than operating at the word level. The proposed architecture takes advantage of a weighted homograph loss (that improves disambiguation), exploits curriculum learning (that gradually switches from word-level to sentence-level G2P), and integrates word embeddings from BERT (for further performance improvement). Moreover, the model inherits the best practices in speech recognition, including multi-task learning with Connectionist Temporal Classification (CTC) and beam search with an embedded language model. As a result, SoundChoice achieves a Phoneme Error Rate (PER) of 2.65% on whole-sentence transcription using data from LibriSpeech and Wikipedia. Index Terms grapheme-to-phoneme, speech synthesis, text-tospeech, phonetics, pronunciation, disambiguation.
Expressive Text-to-Speech using Style Tag
Apr 01, 2021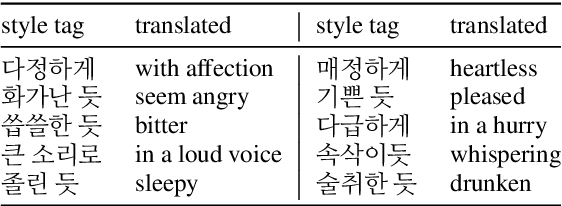
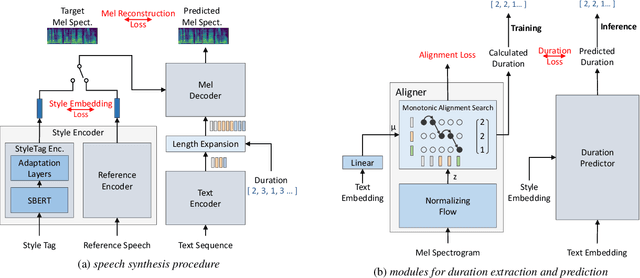
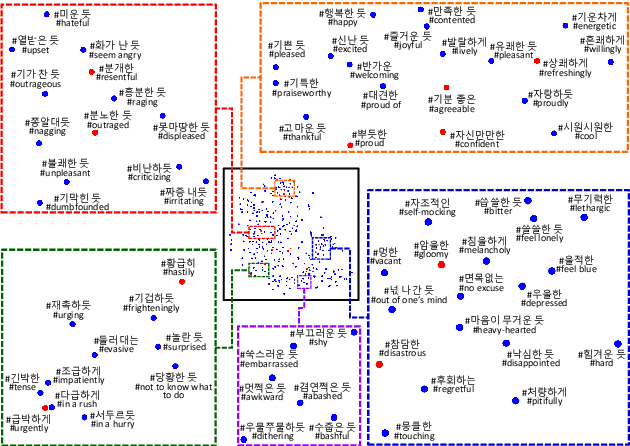
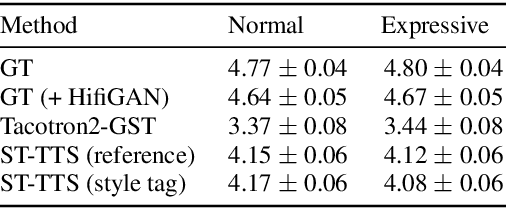
As recent text-to-speech (TTS) systems have been rapidly improved in speech quality and generation speed, many researchers now focus on a more challenging issue: expressive TTS. To control speaking styles, existing expressive TTS models use categorical style index or reference speech as style input. In this work, we propose StyleTagging-TTS (ST-TTS), a novel expressive TTS model that utilizes a style tag written in natural language. Using a style-tagged TTS dataset and a pre-trained language model, we modeled the relationship between linguistic embedding and speaking style domain, which enables our model to work even with style tags unseen during training. As style tag is written in natural language, it can control speaking style in a more intuitive, interpretable, and scalable way compared with style index or reference speech. In addition, in terms of model architecture, we propose an efficient non-autoregressive (NAR) TTS architecture with single-stage training. The experimental result shows that ST-TTS outperforms the existing expressive TTS model, Tacotron2-GST in speech quality and expressiveness.
Magnitude or Phase? A Two Stage Algorithm for Dereverberation
Oct 31, 2022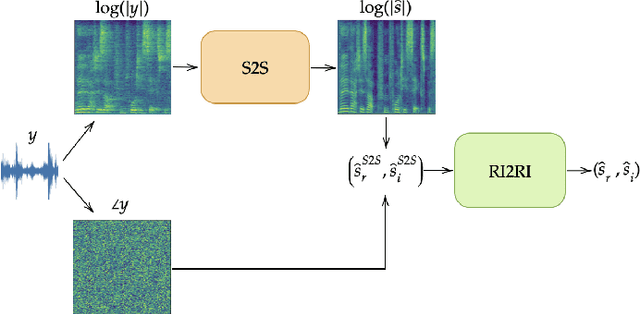
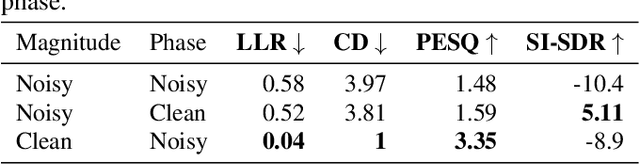
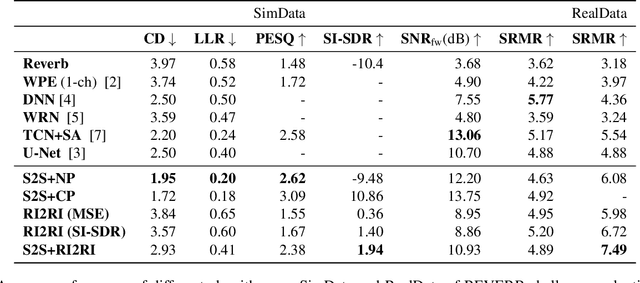
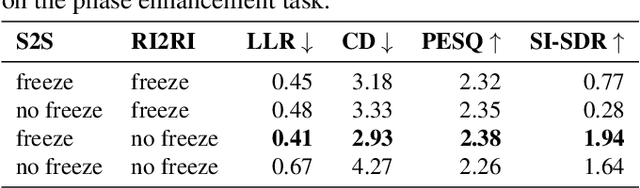
In this work we present a new single-microphone speech dereverberation algorithm. First, a performance analysis is presented to interpret that algorithms focused on improving solely magnitude or phase are not good enough. Furthermore, we demonstrate that few objective measurements have high correlation with the clean magnitude while others with the clean phase. Consequently ,we propose a new architecture which consists of two sub-models, each of which is responsible for a different task. The first model estimates the clean magnitude given the noisy input. The enhanced magnitude together with the noisy-input phase are then used as inputs to the second model to estimate the real and imaginary portions of the dereverberated signal. A training scheme including pre-training and fine-tuning is presented in the paper. We evaluate our proposed approach using data from the REVERB challenge and compare our results to other methods. We demonstrate consistent improvements in all measures, which can be attributed to the improved estimates of both the magnitude and the phase.
Fast and parallel decoding for transducer
Oct 31, 2022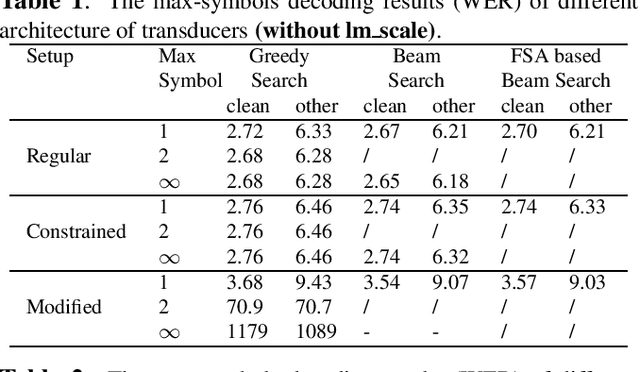
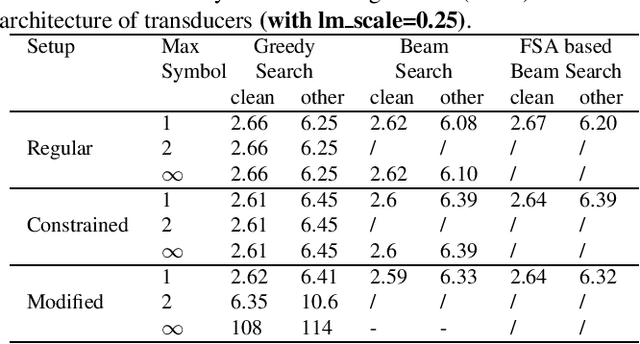
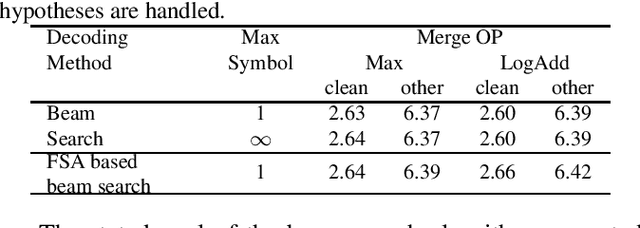
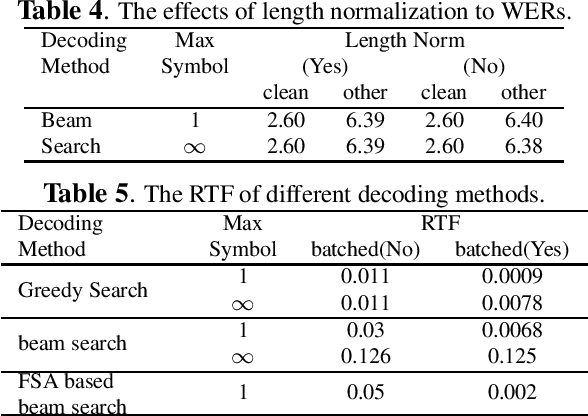
The transducer architecture is becoming increasingly popular in the field of speech recognition, because it is naturally streaming as well as high in accuracy. One of the drawbacks of transducer is that it is difficult to decode in a fast and parallel way due to an unconstrained number of symbols that can be emitted per time step. In this work, we introduce a constrained version of transducer loss to learn strictly monotonic alignments between the sequences; we also improve the standard greedy search and beam search algorithms by limiting the number of symbols that can be emitted per time step in transducer decoding, making it more efficient to decode in parallel with batches. Furthermore, we propose an finite state automaton-based (FSA) parallel beam search algorithm that can run with graphs on GPU efficiently. The experiment results show that we achieve slight word error rate (WER) improvement as well as significant speedup in decoding. Our work is open-sourced and publicly available\footnote{https://github.com/k2-fsa/icefall}.
From Nano to Macro: Overview of the IEEE Bio Image and Signal Processing Technical Committee
Oct 31, 2022

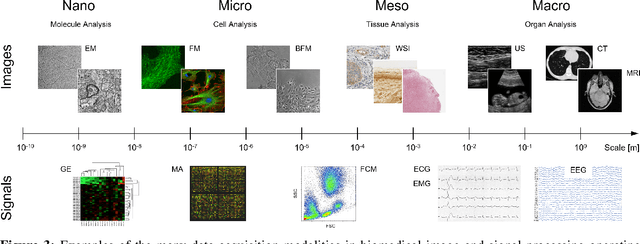
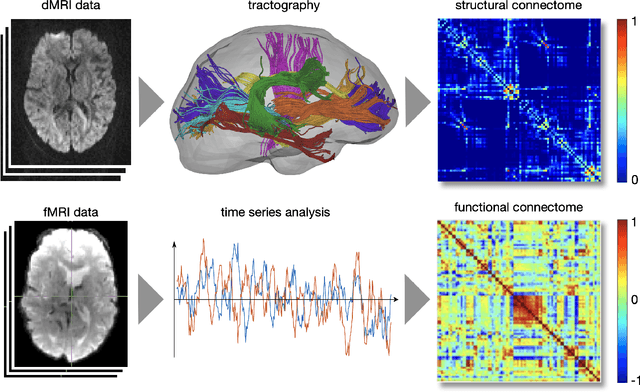
The Bio Image and Signal Processing (BISP) Technical Committee (TC) of the IEEE Signal Processing Society (SPS) promotes activities within the broad technical field of biomedical image and signal processing. Areas of interest include medical and biological imaging, digital pathology, molecular imaging, microscopy, and associated computational imaging, image analysis, and image-guided treatment, alongside physiological signal processing, computational biology, and bioinformatics. BISP has 40 members and covers a wide range of EDICS, including CIS-MI: Medical Imaging, BIO-MIA: Medical Image Analysis, BIO-BI: Biological Imaging, BIO: Biomedical Signal Processing, BIO-BCI: Brain/Human-Computer Interfaces, and BIO-INFR: Bioinformatics. BISP plays a central role in the organization of the IEEE International Symposium on Biomedical Imaging (ISBI) and contributes to the technical sessions at the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), and the IEEE International Conference on Image Processing (ICIP). In this paper, we provide a brief history of the TC, review the technological and methodological contributions its community delivered, and highlight promising new directions we anticipate.
Human-in-the-loop Speaker Adaptation for DNN-based Multi-speaker TTS
Jun 21, 2022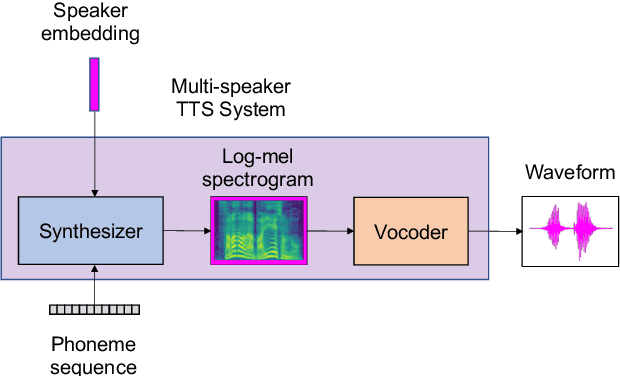
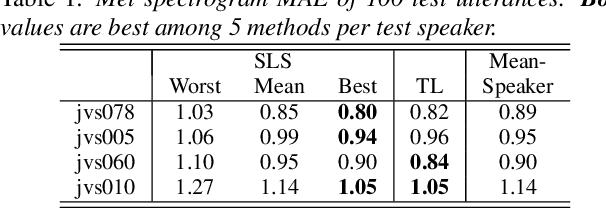
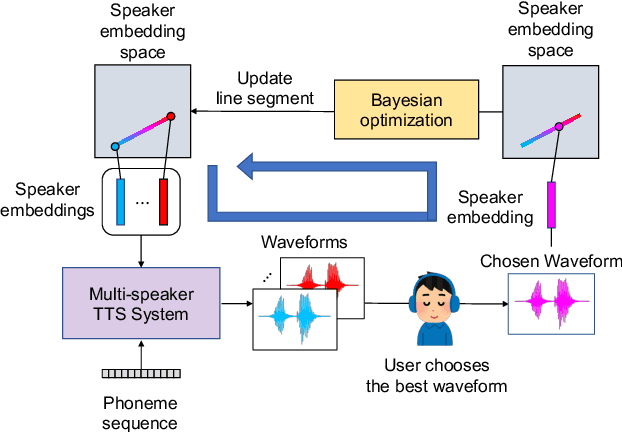
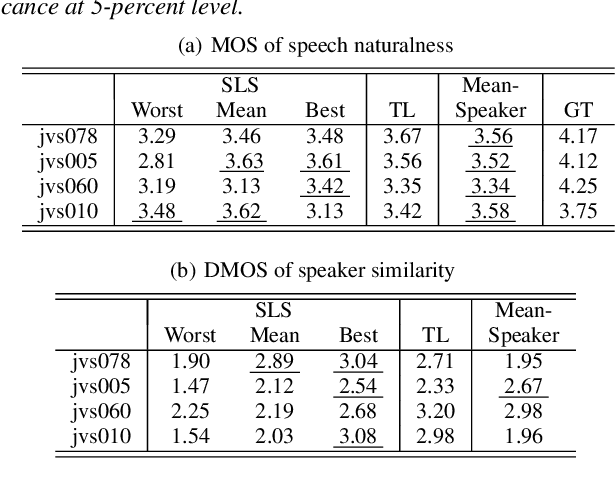
This paper proposes a human-in-the-loop speaker-adaptation method for multi-speaker text-to-speech. With a conventional speaker-adaptation method, a target speaker's embedding vector is extracted from his/her reference speech using a speaker encoder trained on a speaker-discriminative task. However, this method cannot obtain an embedding vector for the target speaker when the reference speech is unavailable. Our method is based on a human-in-the-loop optimization framework, which incorporates a user to explore the speaker-embedding space to find the target speaker's embedding. The proposed method uses a sequential line search algorithm that repeatedly asks a user to select a point on a line segment in the embedding space. To efficiently choose the best speech sample from multiple stimuli, we also developed a system in which a user can switch between multiple speakers' voices for each phoneme while looping an utterance. Experimental results indicate that the proposed method can achieve comparable performance to the conventional one in objective and subjective evaluations even if reference speech is not used as the input of a speaker encoder directly.
Facetron: Multi-speaker Face-to-Speech Model based on Cross-modal Latent Representations
Jul 26, 2021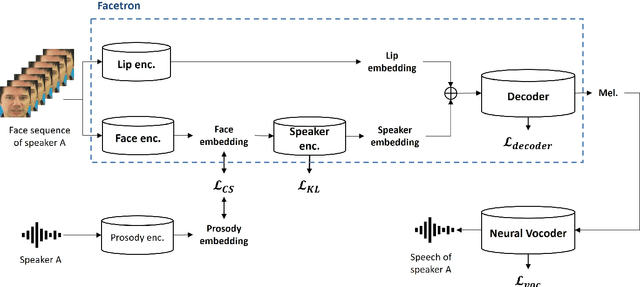
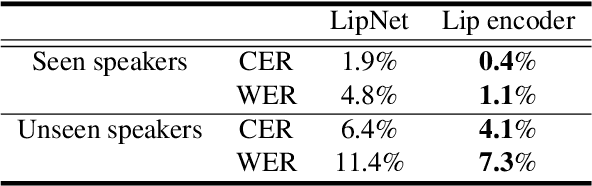
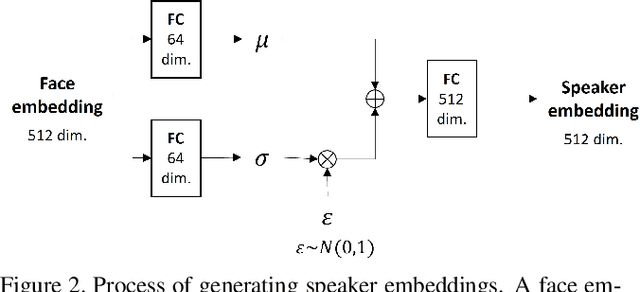
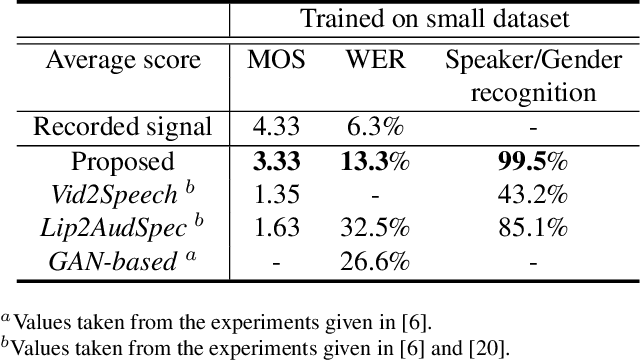
In this paper, we propose an effective method to synthesize speaker-specific speech waveforms by conditioning on videos of an individual's face. Using a generative adversarial network (GAN) with linguistic and speaker characteristic features as auxiliary conditions, our method directly converts face images into speech waveforms under an end-to-end training framework. The linguistic features are extracted from lip movements using a lip-reading model, and the speaker characteristic features are predicted from face images using cross-modal learning with a pre-trained acoustic model. Since these two features are uncorrelated and controlled independently, we can flexibly synthesize speech waveforms whose speaker characteristics vary depending on the input face images. Therefore, our method can be regarded as a multi-speaker face-to-speech waveform model. We show the superiority of our proposed model over conventional methods in terms of both objective and subjective evaluation results. Specifically, we evaluate the performances of the linguistic feature and the speaker characteristic generation modules by measuring the accuracy of automatic speech recognition and automatic speaker/gender recognition tasks, respectively. We also evaluate the naturalness of the synthesized speech waveforms using a mean opinion score (MOS) test.
Complex-valued Spatial Autoencoders for Multichannel Speech Enhancement
Aug 06, 2021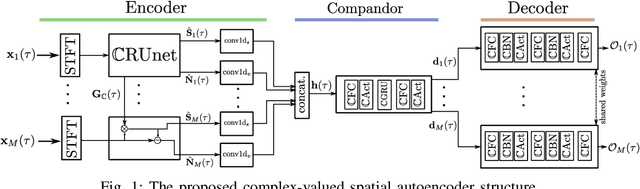
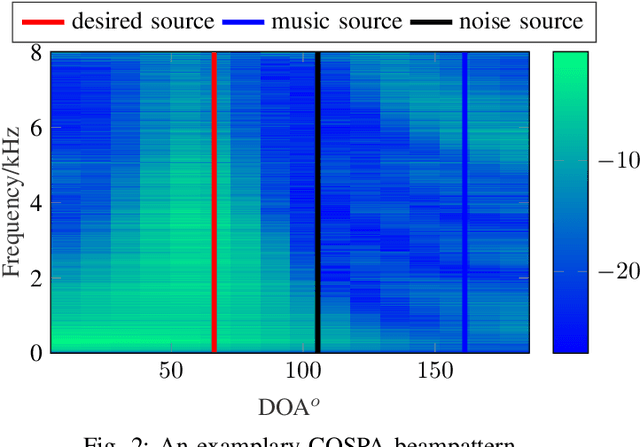
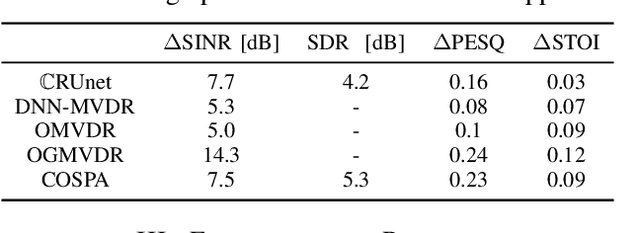
In this contribution, we present a novel online approach to multichannel speech enhancement. The proposed method estimates the enhanced signal through a filter-and-sum framework. More specifically, complex-valued masks are estimated by a deep complex-valued neural network, termed the complex-valued spatial autoencoder. The proposed network is capable of exploiting as well as manipulating both the phase and the amplitude of the microphone signals. As shown by the experimental results, the proposed approach is able to exploit both spatial and spectral characteristics of the desired source signal resulting in a physically plausible spatial selectivity and superior speech quality compared to other baseline methods.
Hierarchical Diffusion Models for Singing Voice Neural Vocoder
Oct 18, 2022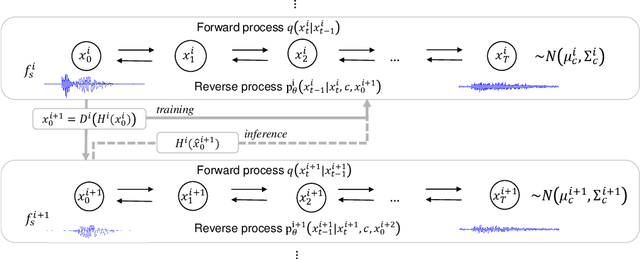
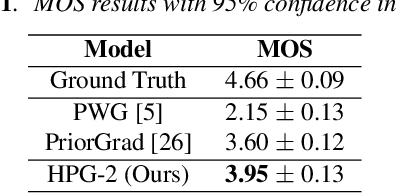
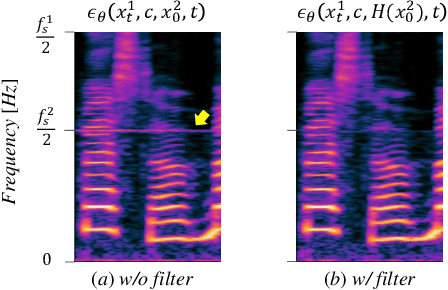
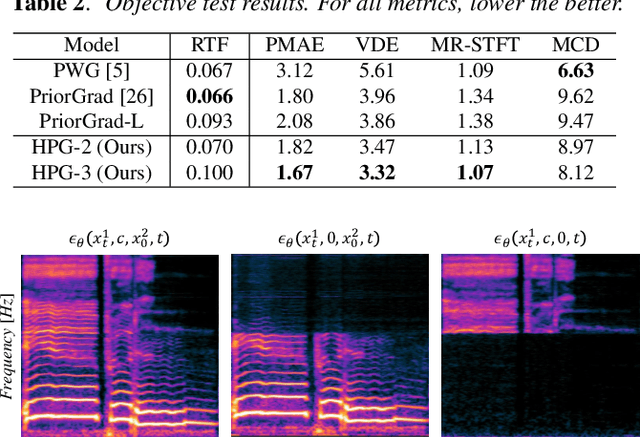
Recent progress in deep generative models has improved the quality of neural vocoders in speech domain. However, generating a high-quality singing voice remains challenging due to a wider variety of musical expressions in pitch, loudness, and pronunciations. In this work, we propose a hierarchical diffusion model for singing voice neural vocoders. The proposed method consists of multiple diffusion models operating in different sampling rates; the model at the lowest sampling rate focuses on generating accurate low-frequency components such as pitch, and other models progressively generate the waveform at higher sampling rates on the basis of the data at the lower sampling rate and acoustic features. Experimental results show that the proposed method produces high-quality singing voices for multiple singers, outperforming state-of-the-art neural vocoders with a similar range of computational costs.