 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacetron: Multi-speaker Face-to-Speech Model based on Cross-modal Latent Representations
Paper and Code
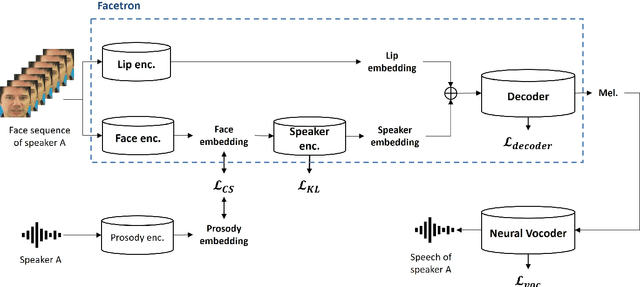
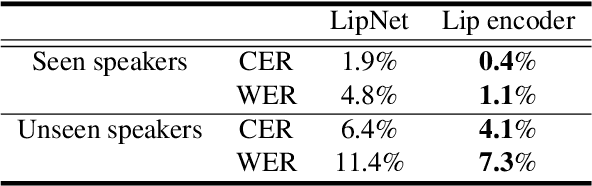
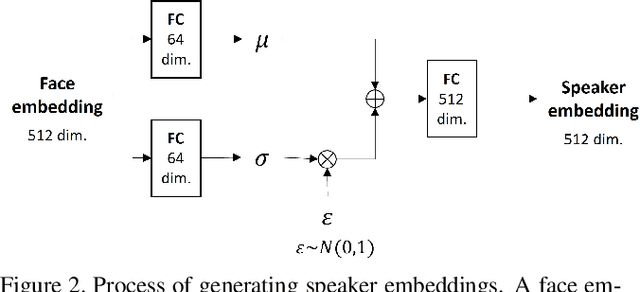
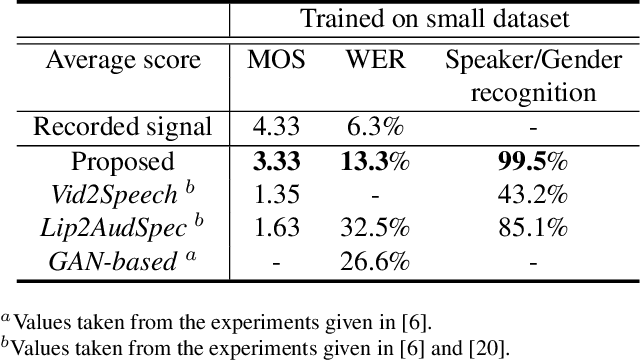
In this paper, we propose an effective method to synthesize speaker-specific speech waveforms by conditioning on videos of an individual's face. Using a generative adversarial network (GAN) with linguistic and speaker characteristic features as auxiliary conditions, our method directly converts face images into speech waveforms under an end-to-end training framework. The linguistic features are extracted from lip movements using a lip-reading model, and the speaker characteristic features are predicted from face images using cross-modal learning with a pre-trained acoustic model. Since these two features are uncorrelated and controlled independently, we can flexibly synthesize speech waveforms whose speaker characteristics vary depending on the input face images. Therefore, our method can be regarded as a multi-speaker face-to-speech waveform model. We show the superiority of our proposed model over conventional methods in terms of both objective and subjective evaluation results. Specifically, we evaluate the performances of the linguistic feature and the speaker characteristic generation modules by measuring the accuracy of automatic speech recognition and automatic speaker/gender recognition tasks, respectively. We also evaluate the naturalness of the synthesized speech waveforms using a mean opinion score (MOS) test.