 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Speech Activity Detection in the Presence of Singing Voice
Dec 10, 2025



Speech Activity Detection (SAD) systems often misclassify singing as speech, leading to degraded performance in applications such as dialogue enhancement and automatic speech recognition. We introduce Singing-Robust Speech Activity Detection ( SR-SAD ), a neural network designed to robustly detect speech in the presence of singing. Our key contributions are: i) a training strategy using controlled ratios of speech and singing samples to improve discrimination, ii) a computationally efficient model that maintains robust performance while reducing inference runtime, and iii) a new evaluation metric tailored to assess SAD robustness in mixed speech-singing scenarios. Experiments on a challenging dataset spanning multiple musical genres show that SR-SAD maintains high speech detection accuracy (AUC = 0.919) while rejecting singing. By explicitly learning to distinguish between speech and singing, SR-SAD enables more reliable SAD in mixed speech-singing scenarios.
* This paper has been published in: 2025 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA)
Neural Directional Filtering Using a Compact Microphone Array
Nov 18, 2025Beamforming with desired directivity patterns using compact microphone arrays is essential in many audio applications. Directivity patterns achievable using traditional beamformers depend on the number of microphones and the array aperture. Generally, their effectiveness degrades for compact arrays. To overcome these limitations, we propose a neural directional filtering (NDF) approach that leverages deep neural networks to enable sound capture with a predefined directivity pattern. The NDF computes a single-channel complex mask from the microphone array signals, which is then applied to a reference microphone to produce an output that approximates a virtual directional microphone with the desired directivity pattern. We introduce training strategies and propose data-dependent metrics to evaluate the directivity pattern and directivity factor. We show that the proposed method: i) achieves a frequency-invariant directivity pattern even above the spatial aliasing frequency, ii) can approximate diverse and higher-order patterns, iii) can steer the pattern in different directions, and iv) generalizes to unseen conditions. Lastly, experimental comparisons demonstrate superior performance over conventional beamforming and parametric approaches.
Navigating PESQ: Up-to-Date Versions and Open Implementations
May 26, 2025



Perceptual Evaluation of Speech Quality (PESQ) is an objective quality measure that remains widely used despite its withdrawal by the International Telecommunication Union (ITU). PESQ has evolved over two decades, with multiple versions and publicly available implementations emerging during this time. The numerous versions and their updates can be overwhelming, especially for new PESQ users. This work provides practical guidance on the different versions and implementations of PESQ. We show that differences can be significant, especially between PESQ versions. We stress the importance of specifying the exact version and implementation that is used to compute PESQ, and possibly to detail how multi-channel signals are handled. These practices would facilitate the interpretation of results and allow comparisons of PESQ scores between different studies. We also provide a repository that implements the latest corrections to PESQ, i.e., Corrigendum 2, which is not implemented by any other openly available distribution: https://github.com/audiolabs/PESQ.
On the Relation Between Speech Quality and Quantized Latent Representations of Neural Codecs
Mar 05, 2025Neural audio signal codecs have attracted significant attention in recent years. In essence, the impressive low bitrate achieved by such encoders is enabled by learning an abstract representation that captures the properties of encoded signals, e.g., speech. In this work, we investigate the relation between the latent representation of the input signal learned by a neural codec and the quality of speech signals. To do so, we introduce Latent-representation-to-Quantization error Ratio (LQR) measures, which quantify the distance from the idealized neural codec's speech signal model for a given speech signal. We compare the proposed metrics to intrusive measures as well as data-driven supervised methods using two subjective speech quality datasets. This analysis shows that the proposed LQR correlates strongly (up to 0.9 Pearson's correlation) with the subjective quality of speech. Despite being a non-intrusive metric, this yields a competitive performance with, or even better than, other pre-trained and intrusive measures. These results show that LQR is a promising basis for more sophisticated speech quality measures.
ConcateNet: Dialogue Separation Using Local And Global Feature Concatenation
Aug 16, 2024

Dialogue separation involves isolating a dialogue signal from a mixture, such as a movie or a TV program. This can be a necessary step to enable dialogue enhancement for broadcast-related applications. In this paper, ConcateNet for dialogue separation is proposed, which is based on a novel approach for processing local and global features aimed at better generalization for out-of-domain signals. ConcateNet is trained using a noise reduction-focused, publicly available dataset and evaluated using three datasets: two noise reduction-focused datasets (in-domain), which show competitive performance for ConcateNet, and a broadcast-focused dataset (out-of-domain), which verifies the better generalization performance for the proposed architecture compared to considered state-of-the-art noise-reduction methods.
Speech Loudness in Broadcasting and Streaming
May 27, 2024



The introduction and regulation of loudness in broadcasting and streaming brought clear benefits to the audience, e.g., a level of uniformity across programs and channels. Yet, speech loudness is frequently reported as being too low in certain passages, which can hinder the full understanding and enjoyment of movies and TV programs. This paper proposes expanding the set of loudness-based measures typically used in the industry. We focus on speech loudness, and we show that, when clean speech is not available, Deep Neural Networks (DNNs) can be used to isolate the speech signal and so to accurately estimate speech loudness, providing a more precise estimate compared to speech-gated loudness. Moreover, we define critical passages, i.e., passages in which speech is likely to be hard to understand. Critical passages are defined based on the local Speech Loudness Deviation (SLD) and the local Speech-to-Background Loudness Difference (SBLD), as SLD and SBLD significantly contribute to intelligibility and listening effort. In contrast to other more comprehensive measures of intelligibility and listening effort, SLD and SBLD can be straightforwardly measured, are intuitive, and, most importantly, can be easily controlled by adjusting the speech level in the mix or by enabling personalization at the user's end. Finally, examples are provided that show how the detection of critical passages can support the evaluation and control of the speech signal during and after content production.
ODAQ: Open Dataset of Audio Quality
Dec 30, 2023



Research into the prediction and analysis of perceived audio quality is hampered by the scarcity of openly available datasets of audio signals accompanied by corresponding subjective quality scores. To address this problem, we present the Open Dataset of Audio Quality (ODAQ), a new dataset containing the results of a MUSHRA listening test conducted with expert listeners from 2 international laboratories. ODAQ contains 240 audio samples and corresponding quality scores. Each audio sample is rated by 26 listeners. The audio samples are stereo audio signals sampled at 44.1 or 48 kHz and are processed by a total of 6 method classes, each operating at different quality levels. The processing method classes are designed to generate quality degradations possibly encountered during audio coding and source separation, and the quality levels for each method class span the entire quality range. The diversity of the processing methods, the large span of quality levels, the high sampling frequency, and the pool of international listeners make ODAQ particularly suited for further research into subjective and objective audio quality. The dataset is released with permissive licenses, and the software used to conduct the listening test is also made publicly available.
Exploiting spatial information with the informed complex-valued spatial autoencoder for target speaker extraction
Oct 27, 2022



In conventional multichannel audio signal enhancement, spatial and spectral filtering are often performed sequentially. In contrast, it has been shown that for neural spatial filtering a joint approach of spectro-spatial filtering is more beneficial. In this contribution, we investigate the influence of the training target on the spatial selectivity of such a time-varying spectro-spatial filter. We extend the recently proposed complex-valued spatial autoencoder (COSPA) for target speaker extraction by leveraging its interpretable structure and purposefully informing the network of the target speaker's position. Consequently, this approach uses a multichannel complex-valued neural network architecture that is capable of processing spatial and spectral information rendering informed COSPA (iCOSPA) an effective neural spatial filtering method. We train iCOSPA for several training targets that enforce different amounts of spatial processing and analyze the network's spatial filtering capacity. We find that the proposed architecture is indeed capable of learning different spatial selectivity patterns to attain the different training targets.
Complex-valued Spatial Autoencoders for Multichannel Speech Enhancement
Aug 06, 2021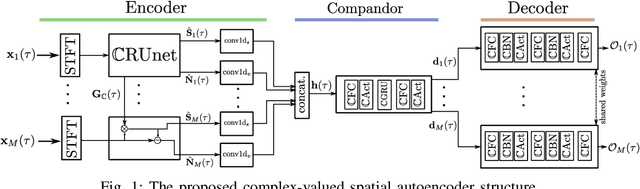
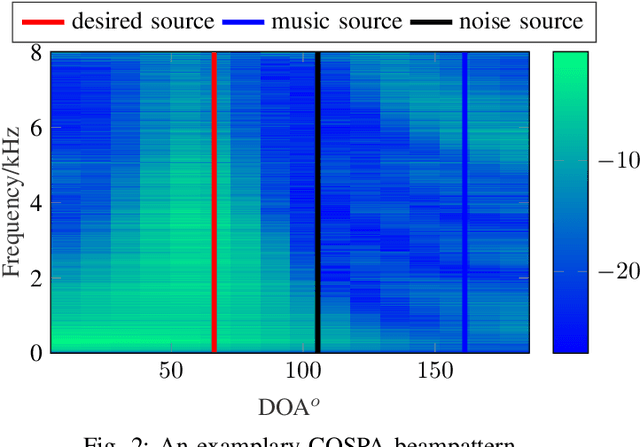
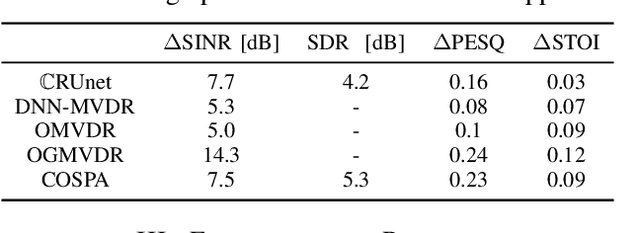
In this contribution, we present a novel online approach to multichannel speech enhancement. The proposed method estimates the enhanced signal through a filter-and-sum framework. More specifically, complex-valued masks are estimated by a deep complex-valued neural network, termed the complex-valued spatial autoencoder. The proposed network is capable of exploiting as well as manipulating both the phase and the amplitude of the microphone signals. As shown by the experimental results, the proposed approach is able to exploit both spatial and spectral characteristics of the desired source signal resulting in a physically plausible spatial selectivity and superior speech quality compared to other baseline methods.