 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Voice-Driven Mortality Prediction in Hospitalized Heart Failure Patients: A Machine Learning Approach Enhanced with Diagnostic Biomarkers
Feb 21, 2024
Addressing heart failure (HF) as a prevalent global health concern poses difficulties in implementing innovative approaches for enhanced patient care. Predicting mortality rates in HF patients, in particular, is difficult yet critical, necessitating individualized care, proactive management, and enabling educated decision-making to enhance outcomes. Recently, the significance of voice biomarkers coupled with Machine Learning (ML) has surged, demonstrating remarkable efficacy, particularly in predicting heart failure. The synergy of voice analysis and ML algorithms provides a non-invasive and easily accessible means to evaluate patients' health. However, there is a lack of voice biomarkers for predicting mortality rates among heart failure patients with standardized speech protocols. Here, we demonstrate a powerful and effective ML model for predicting mortality rates in hospitalized HF patients through the utilization of voice biomarkers. By seamlessly integrating voice biomarkers into routine patient monitoring, this strategy has the potential to improve patient outcomes, optimize resource allocation, and advance patient-centered HF management. In this study, a Machine Learning system, specifically a logistic regression model, is trained to predict patients' 5-year mortality rates using their speech as input. The model performs admirably and consistently, as demonstrated by cross-validation and statistical approaches (p-value < 0.001). Furthermore, integrating NT-proBNP, a diagnostic biomarker in HF, improves the model's predictive accuracy substantially.
Bayesian Parameter-Efficient Fine-Tuning for Overcoming Catastrophic Forgetting
Feb 19, 2024Although motivated by the adaptation of text-to-speech synthesis models, we argue that more generic parameter-efficient fine-tuning (PEFT) is an appropriate framework to do such adaptation. However, catastrophic forgetting remains an issue with PEFT, damaging the pre-trained model's inherent capabilities. We demonstrate that existing Bayesian learning techniques can be applied to PEFT to prevent catastrophic forgetting as long as the parameter shift of the fine-tuned layers can be calculated differentiably. In a principled series of experiments on language modeling and speech synthesis tasks, we utilize established Laplace approximations, including diagonal and Kronecker factored approaches, to regularize PEFT with the low-rank adaptation (LoRA) and compare their performance in pre-training knowledge preservation. Our results demonstrate that catastrophic forgetting can be overcome by our methods without degrading the fine-tuning performance, and using the Kronecker factored approximations produces a better preservation of the pre-training knowledge than the diagonal ones.
AnyGPT: Unified Multimodal LLM with Discrete Sequence Modeling
Feb 26, 2024We introduce AnyGPT, an any-to-any multimodal language model that utilizes discrete representations for the unified processing of various modalities, including speech, text, images, and music. AnyGPT can be trained stably without any alterations to the current large language model (LLM) architecture or training paradigms. Instead, it relies exclusively on data-level preprocessing, facilitating the seamless integration of new modalities into LLMs, akin to the incorporation of new languages. We build a multimodal text-centric dataset for multimodal alignment pre-training. Utilizing generative models, we synthesize the first large-scale any-to-any multimodal instruction dataset. It consists of 108k samples of multi-turn conversations that intricately interweave various modalities, thus equipping the model to handle arbitrary combinations of multimodal inputs and outputs. Experimental results demonstrate that AnyGPT is capable of facilitating any-to-any multimodal conversation while achieving performance comparable to specialized models across all modalities, proving that discrete representations can effectively and conveniently unify multiple modalities within a language model. Demos are shown in https://junzhan2000.github.io/AnyGPT.github.io/
Information Flow Routes: Automatically Interpreting Language Models at Scale
Feb 27, 2024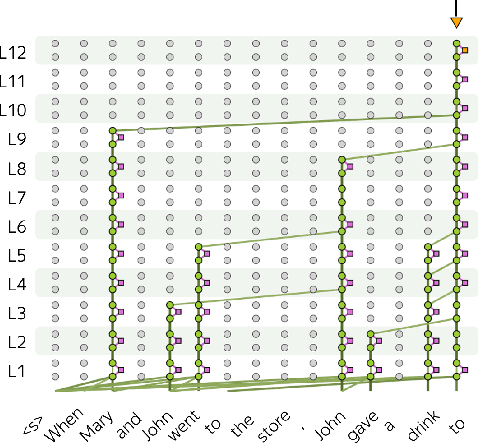
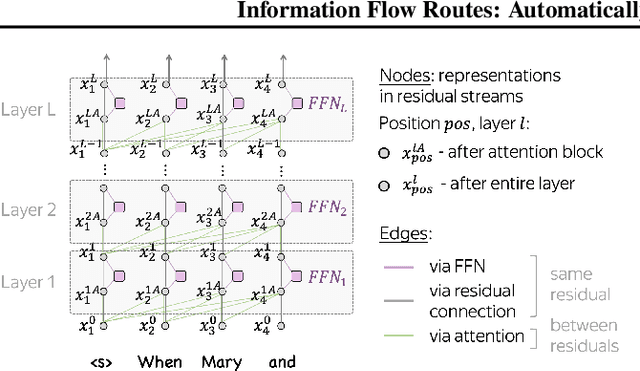
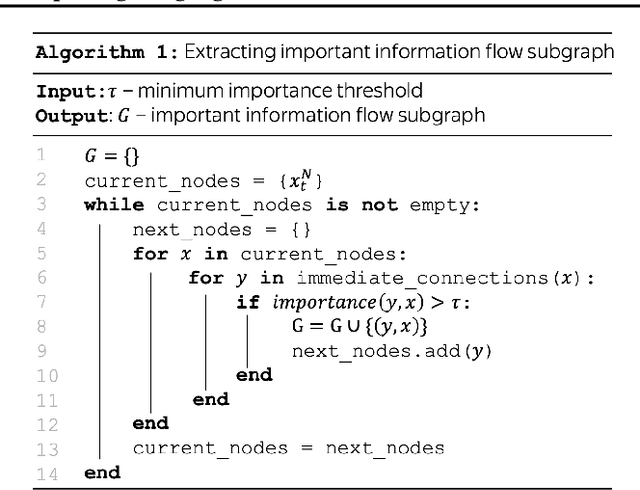
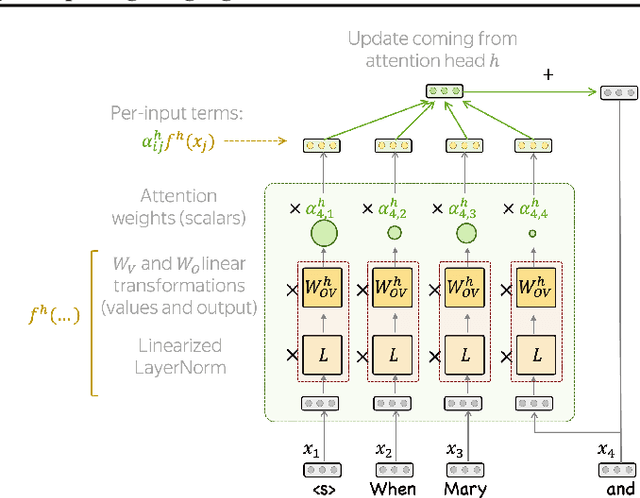
Information flows by routes inside the network via mechanisms implemented in the model. These routes can be represented as graphs where nodes correspond to token representations and edges to operations inside the network. We automatically build these graphs in a top-down manner, for each prediction leaving only the most important nodes and edges. In contrast to the existing workflows relying on activation patching, we do this through attribution: this allows us to efficiently uncover existing circuits with just a single forward pass. Additionally, the applicability of our method is far beyond patching: we do not need a human to carefully design prediction templates, and we can extract information flow routes for any prediction (not just the ones among the allowed templates). As a result, we can talk about model behavior in general, for specific types of predictions, or different domains. We experiment with Llama 2 and show that the role of some attention heads is overall important, e.g. previous token heads and subword merging heads. Next, we find similarities in Llama 2 behavior when handling tokens of the same part of speech. Finally, we show that some model components can be specialized on domains such as coding or multilingual texts.
Harmonic Detection from Noisy Speech with Auditory Frame Gain for Intelligibility Enhancement
Jan 22, 2024This paper introduces a novel (HDAG - Harmonic Detection for Auditory Gain) method for speech intelligibility enhancement in noisy scenarios. In the proposed scheme, a series of selective Gammachirp filters are adopted to emphasize the harmonic components of speech reducing the masking effects of acoustic noises. The fundamental frequency are estimated by the HHT-Amp technique. Harmonic patterns estimated with low accuracy are detected and adjusted according the FSFFE low/high pitch separation. The central frequencies of the filterbank are defined considering the third octave subbands which are best suited to cover the regions most relevant to intelligibility. Before signal reconstruction, the gammachirp filtered components are amplified by gain factors regulated by FSFFE classification. The proposed HDAG solution and three baseline techniques are examined considering six background noises with four signal-to-noise ratios. Three objective measures are adopted for the evaluation of speech intelligibility and quality. Several experiments are conducted to demonstrate that the proposed scheme achieves better speech intelligibility improvement when compared to the competing approaches. A perceptual listening test is further considered and corroborates with the objective results.
A Multi-Aspect Framework for Counter Narrative Evaluation using Large Language Models
Feb 18, 2024Counter narratives - informed responses to hate speech contexts designed to refute hateful claims and de-escalate encounters - have emerged as an effective hate speech intervention strategy. While previous work has proposed automatic counter narrative generation methods to aid manual interventions, the evaluation of these approaches remains underdeveloped. Previous automatic metrics for counter narrative evaluation lack alignment with human judgment as they rely on superficial reference comparisons instead of incorporating key aspects of counter narrative quality as evaluation criteria. To address prior evaluation limitations, we propose a novel evaluation framework prompting LLMs to provide scores and feedback for generated counter narrative candidates using 5 defined aspects derived from guidelines from counter narrative specialized NGOs. We found that LLM evaluators achieve strong alignment to human-annotated scores and feedback and outperform alternative metrics, indicating their potential as multi-aspect, reference-free and interpretable evaluators for counter narrative evaluation.
DIFFRENT: A Diffusion Model for Recording Environment Transfer of Speech
Jan 16, 2024Properly setting up recording conditions, including microphone type and placement, room acoustics, and ambient noise, is essential to obtaining the desired acoustic characteristics of speech. In this paper, we propose Diff-R-EN-T, a Diffusion model for Recording ENvironment Transfer which transforms the input speech to have the recording conditions of a reference speech while preserving the speech content. Our model comprises the content enhancer, the recording environment encoder, and the diffusion decoder which generates the target mel-spectrogram by utilizing both enhancer and encoder as input conditions. We evaluate DiffRENT in the speech enhancement and acoustic matching scenarios. The results show that DiffRENT generalizes well to unseen environments and new speakers. Also, the proposed model achieves superior performances in objective and subjective evaluation. Sound examples of our proposed model are available online.
GPT-HateCheck: Can LLMs Write Better Functional Tests for Hate Speech Detection?
Feb 23, 2024Online hate detection suffers from biases incurred in data sampling, annotation, and model pre-training. Therefore, measuring the averaged performance over all examples in held-out test data is inadequate. Instead, we must identify specific model weaknesses and be informed when it is more likely to fail. A recent proposal in this direction is HateCheck, a suite for testing fine-grained model functionalities on synthesized data generated using templates of the kind "You are just a [slur] to me." However, despite enabling more detailed diagnostic insights, the HateCheck test cases are often generic and have simplistic sentence structures that do not match the real-world data. To address this limitation, we propose GPT-HateCheck, a framework to generate more diverse and realistic functional tests from scratch by instructing large language models (LLMs). We employ an additional natural language inference (NLI) model to verify the generations. Crowd-sourced annotation demonstrates that the generated test cases are of high quality. Using the new functional tests, we can uncover model weaknesses that would be overlooked using the original HateCheck dataset.
SpiRit-LM: Interleaved Spoken and Written Language Model
Feb 08, 2024We introduce SPIRIT-LM, a foundation multimodal language model that freely mixes text and speech. Our model is based on a pretrained text language model that we extend to the speech modality by continuously training it on text and speech units. Speech and text sequences are concatenated as a single set of tokens, and trained with a word-level interleaving method using a small automatically-curated speech-text parallel corpus. SPIRIT-LM comes in two versions: a BASE version that uses speech semantic units and an EXPRESSIVE version that models expressivity using pitch and style units in addition to the semantic units. For both versions, the text is encoded with subword BPE tokens. The resulting model displays both the semantic abilities of text models and the expressive abilities of speech models. Additionally, we demonstrate that SPIRIT-LM is able to learn new tasks in a few-shot fashion across modalities (i.e. ASR, TTS, Speech Classification).
Whose LLM is it Anyway? Linguistic Comparison and LLM Attribution for GPT-3.5, GPT-4 and Bard
Feb 22, 2024Large Language Models (LLMs) are capable of generating text that is similar to or surpasses human quality. However, it is unclear whether LLMs tend to exhibit distinctive linguistic styles akin to how human authors do. Through a comprehensive linguistic analysis, we compare the vocabulary, Part-Of-Speech (POS) distribution, dependency distribution, and sentiment of texts generated by three of the most popular LLMS today (GPT-3.5, GPT-4, and Bard) to diverse inputs. The results point to significant linguistic variations which, in turn, enable us to attribute a given text to its LLM origin with a favorable 88\% accuracy using a simple off-the-shelf classification model. Theoretical and practical implications of this intriguing finding are discussed.