 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Comparative Study of Pre-trained Speech and Audio Embeddings for Speech Emotion Recognition
Apr 22, 2023
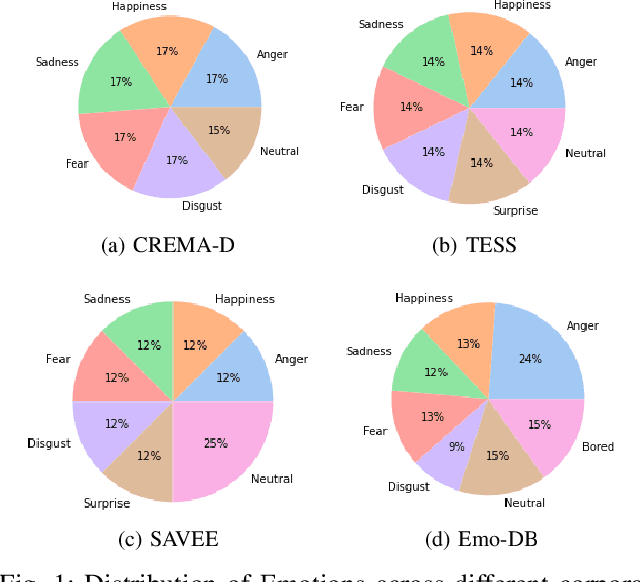

Pre-trained models (PTMs) have shown great promise in the speech and audio domain. Embeddings leveraged from these models serve as inputs for learning algorithms with applications in various downstream tasks. One such crucial task is Speech Emotion Recognition (SER) which has a wide range of applications, including dynamic analysis of customer calls, mental health assessment, and personalized language learning. PTM embeddings have helped advance SER, however, a comprehensive comparison of these PTM embeddings that consider multiple facets such as embedding model architecture, data used for pre-training, and the pre-training procedure being followed is missing. A thorough comparison of PTM embeddings will aid in the faster and more efficient development of models and enable their deployment in real-world scenarios. In this work, we exploit this research gap and perform a comparative analysis of embeddings extracted from eight speech and audio PTMs (wav2vec 2.0, data2vec, wavLM, UniSpeech-SAT, wav2clip, YAMNet, x-vector, ECAPA). We perform an extensive empirical analysis with four speech emotion datasets (CREMA-D, TESS, SAVEE, Emo-DB) by training three algorithms (XGBoost, Random Forest, FCN) on the derived embeddings. The results of our study indicate that the best performance is achieved by algorithms trained on embeddings derived from PTMs trained for speaker recognition followed by wav2clip and UniSpeech-SAT. This can relay that the top performance by embeddings from speaker recognition PTMs is most likely due to the model taking up information about numerous speech features such as tone, accent, pitch, and so on during its speaker recognition training. Insights from this work will assist future studies in their selection of embeddings for applications related to SER.
Distillation Strategies for Discriminative Speech Recognition Rescoring
Jun 15, 2023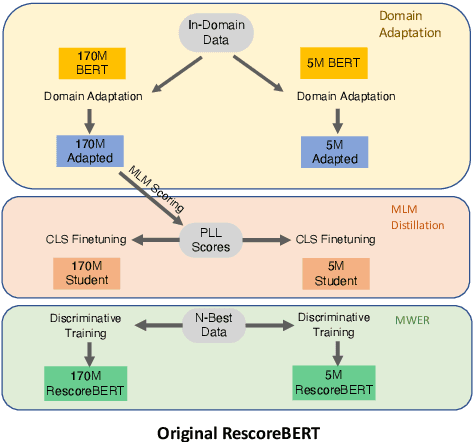
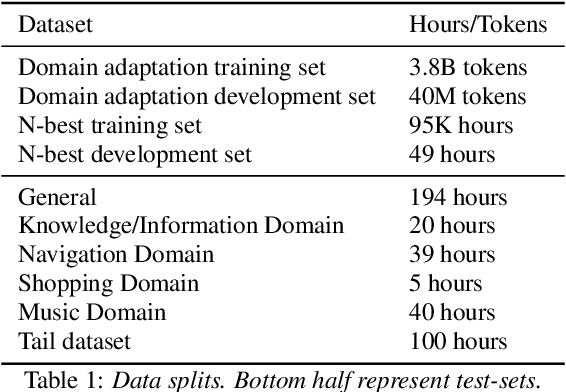
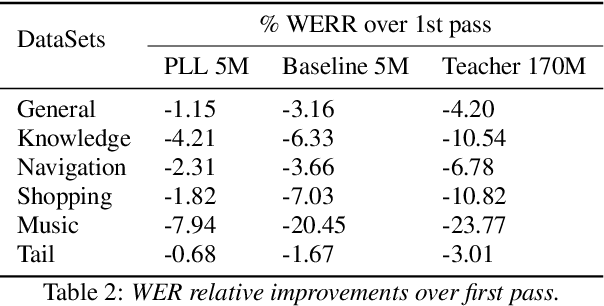
Second-pass rescoring is employed in most state-of-the-art speech recognition systems. Recently, BERT based models have gained popularity for re-ranking the n-best hypothesis by exploiting the knowledge from masked language model pre-training. Further, fine-tuning with discriminative loss such as minimum word error rate (MWER) has shown to perform better than likelihood-based loss. Streaming applications with low latency requirements impose significant constraints on the size of the models, thereby limiting the word error rate (WER) performance gains. In this paper, we propose effective strategies for distilling from large models discriminatively trained with the MWER objective. We experiment on Librispeech and production scale internal dataset for voice-assistant. Our results demonstrate relative improvements of upto 7% WER over student models trained with MWER. We also show that the proposed distillation can reduce the WER gap between the student and the teacher by 62% upto 100%.
a unified front-end framework for english text-to-speech synthesis
May 18, 2023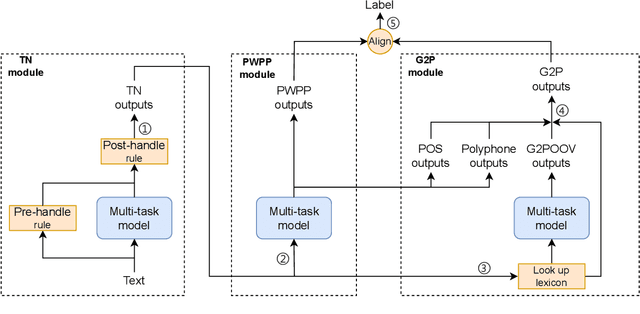

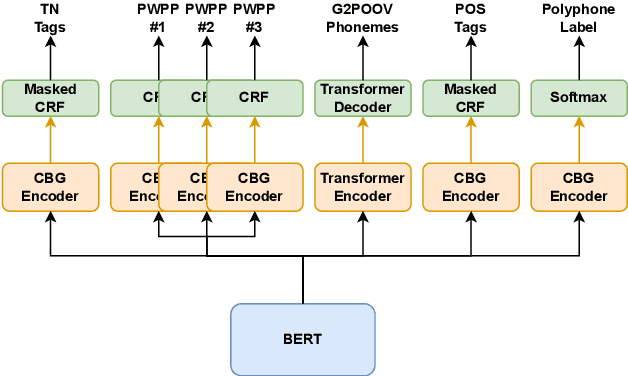
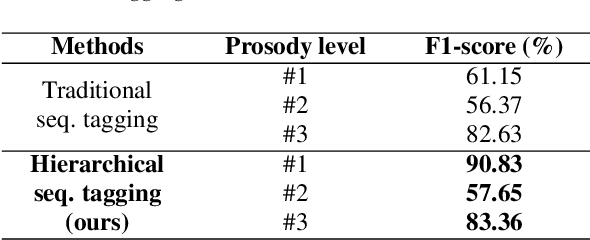
The front-end is a critical component of English text-to-speech (TTS) systems, responsible for extracting linguistic features that are essential for a text-to-speech model to synthesize speech, such as prosodies and phonemes. The English TTS front-end typically consists of a text normalization (TN) module, a prosody word prosody phrase (PWPP) module, and a grapheme-to-phoneme (G2P) module. However, current research on the English TTS front-end focuses solely on individual modules, neglecting the interdependence between them and resulting in sub-optimal performance for each module. Therefore, this paper proposes a unified front-end framework that captures the dependencies among the English TTS front-end modules. Extensive experiments have demonstrated that the proposed method achieves state-of-the-art (SOTA) performance in all modules.
Interpretable Style Transfer for Text-to-Speech with ControlVAE and Diffusion Bridge
Jun 07, 2023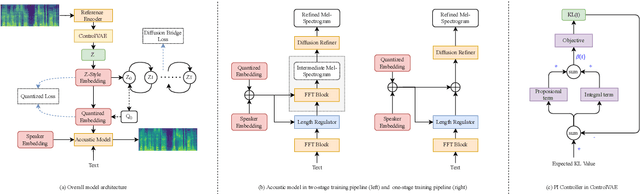
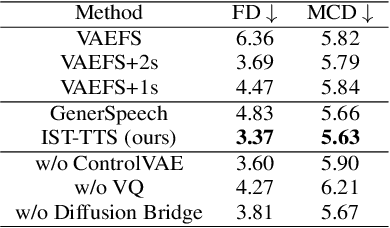
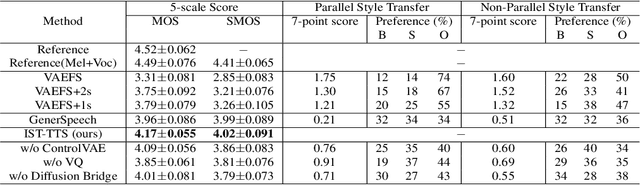
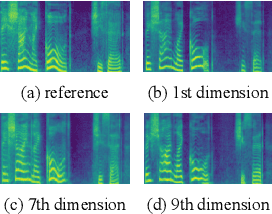
With the demand for autonomous control and personalized speech generation, the style control and transfer in Text-to-Speech (TTS) is becoming more and more important. In this paper, we propose a new TTS system that can perform style transfer with interpretability and high fidelity. Firstly, we design a TTS system that combines variational autoencoder (VAE) and diffusion refiner to get refined mel-spectrograms. Specifically, a two-stage and a one-stage system are designed respectively, to improve the audio quality and the performance of style transfer. Secondly, a diffusion bridge of quantized VAE is designed to efficiently learn complex discrete style representations and improve the performance of style transfer. To have a better ability of style transfer, we introduce ControlVAE to improve the reconstruction quality and have good interpretability simultaneously. Experiments on LibriTTS dataset demonstrate that our method is more effective than baseline models.
CALLS: Japanese Empathetic Dialogue Speech Corpus of Complaint Handling and Attentive Listening in Customer Center
May 23, 2023
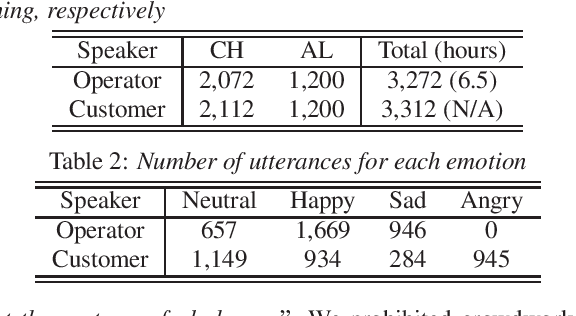
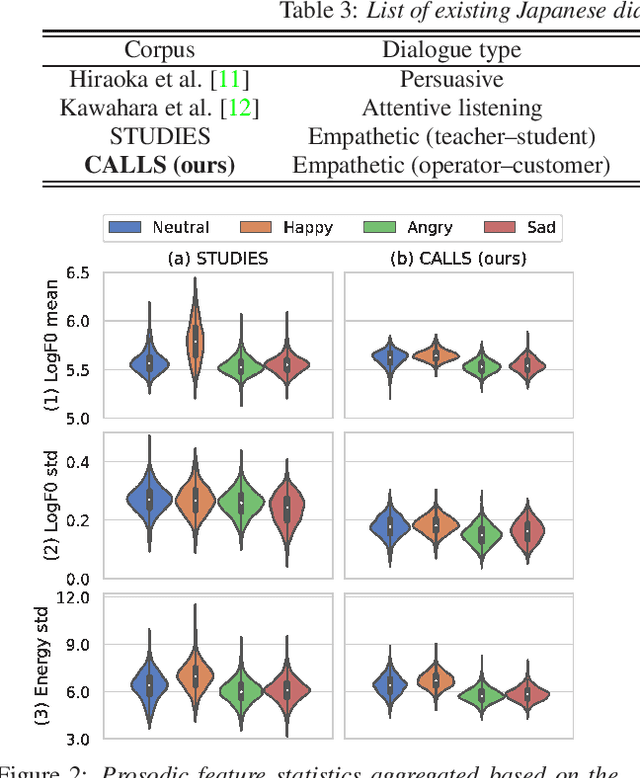
We present CALLS, a Japanese speech corpus that considers phone calls in a customer center as a new domain of empathetic spoken dialogue. The existing STUDIES corpus covers only empathetic dialogue between a teacher and student in a school. To extend the application range of empathetic dialogue speech synthesis (EDSS), we designed our corpus to include the same female speaker as the STUDIES teacher, acting as an operator in simulated phone calls. We describe a corpus construction methodology and analyze the recorded speech. We also conduct EDSS experiments using the CALLS and STUDIES corpora to investigate the effect of domain differences. The results show that mixing the two corpora during training causes biased improvements in the quality of synthetic speech due to the different degrees of expressiveness. Our project page of the corpus is http://sython.org/Corpus/STUDIES-2.
FonMTL: Towards Multitask Learning for the Fon Language
Sep 11, 2023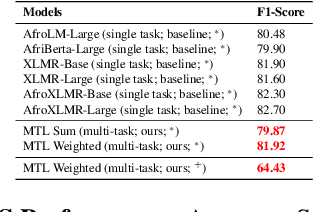
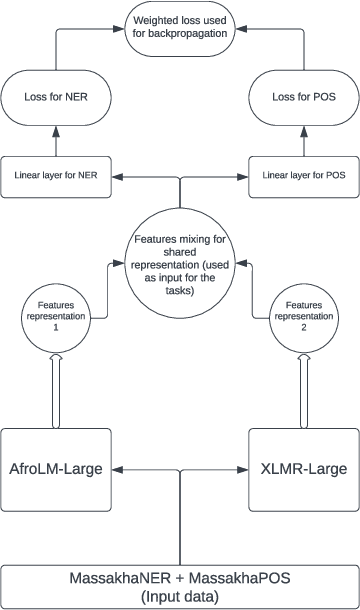
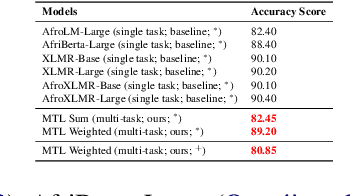
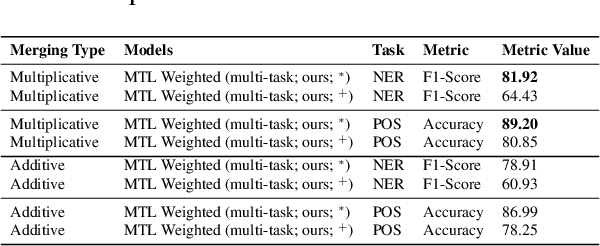
The Fon language, spoken by an average 2 million of people, is a truly low-resourced African language, with a limited online presence, and existing datasets (just to name but a few). Multitask learning is a learning paradigm that aims to improve the generalization capacity of a model by sharing knowledge across different but related tasks: this could be prevalent in very data-scarce scenarios. In this paper, we present the first explorative approach to multitask learning, for model capabilities enhancement in Natural Language Processing for the Fon language. Specifically, we explore the tasks of Named Entity Recognition (NER) and Part of Speech Tagging (POS) for Fon. We leverage two language model heads as encoders to build shared representations for the inputs, and we use linear layers blocks for classification relative to each task. Our results on the NER and POS tasks for Fon, show competitive (or better) performances compared to several multilingual pretrained language models finetuned on single tasks. Additionally, we perform a few ablation studies to leverage the efficiency of two different loss combination strategies and find out that the equal loss weighting approach works best in our case. Our code is open-sourced at https://github.com/bonaventuredossou/multitask_fon.
Towards hate speech detection in low-resource languages: Comparing ASR to acoustic word embeddings on Wolof and Swahili
Jun 01, 2023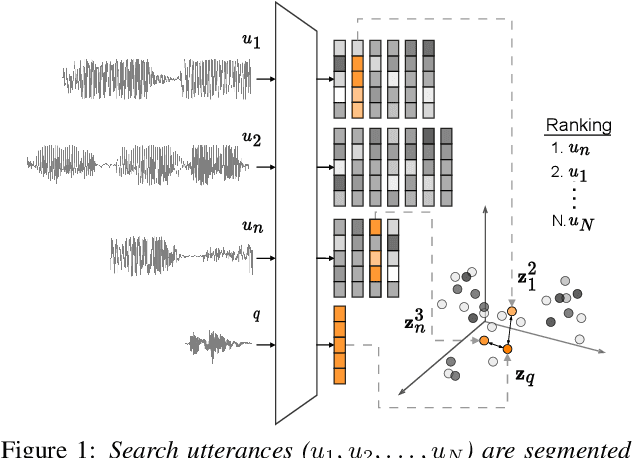
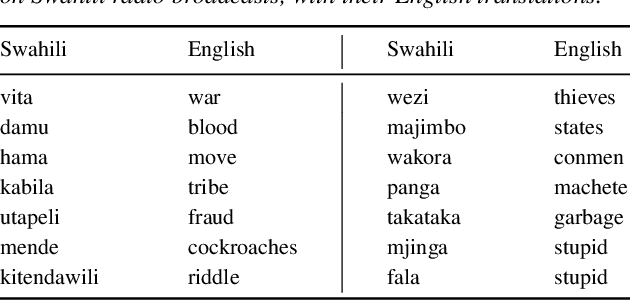
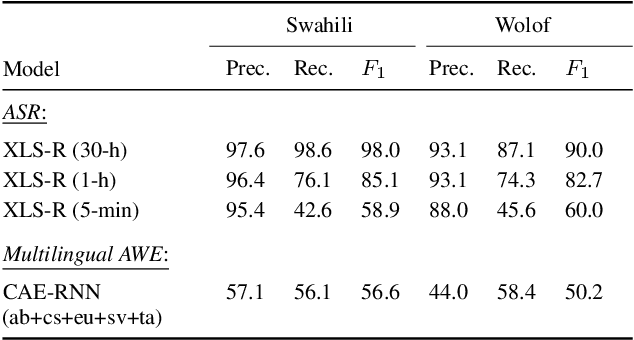
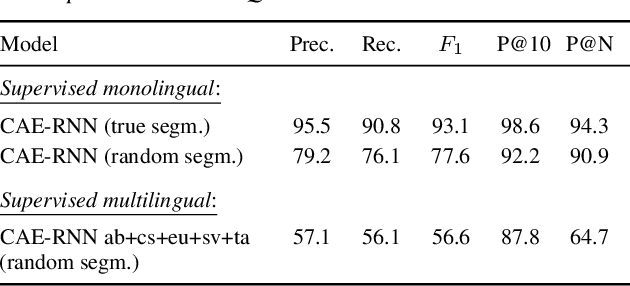
We consider hate speech detection through keyword spotting on radio broadcasts. One approach is to build an automatic speech recognition (ASR) system for the target low-resource language. We compare this to using acoustic word embedding (AWE) models that map speech segments to a space where matching words have similar vectors. We specifically use a multilingual AWE model trained on labelled data from well-resourced languages to spot keywords in data in the unseen target language. In contrast to ASR, the AWE approach only requires a few keyword exemplars. In controlled experiments on Wolof and Swahili where training and test data are from the same domain, an ASR model trained on just five minutes of data outperforms the AWE approach. But in an in-the-wild test on Swahili radio broadcasts with actual hate speech keywords, the AWE model (using one minute of template data) is more robust, giving similar performance to an ASR system trained on 30 hours of labelled data.
NeuroHeed: Neuro-Steered Speaker Extraction using EEG Signals
Jul 26, 2023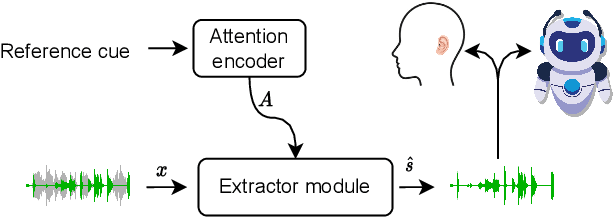
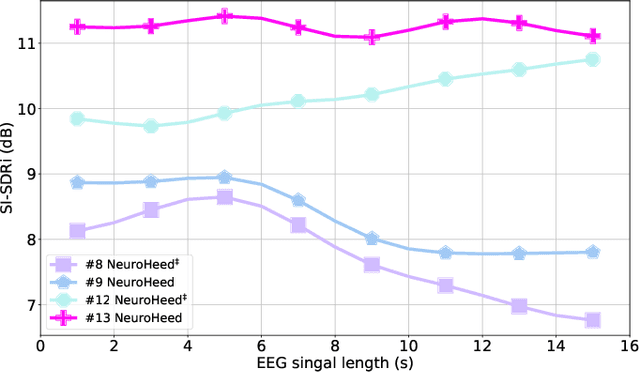
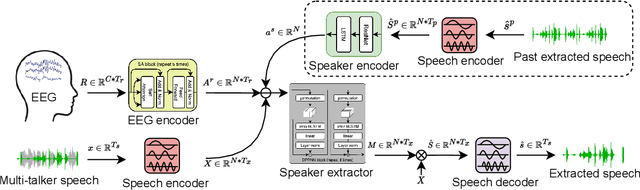
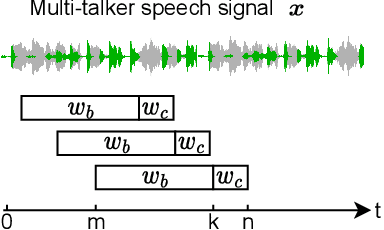
Humans possess the remarkable ability to selectively attend to a single speaker amidst competing voices and background noise, known as selective auditory attention. Recent studies in auditory neuroscience indicate a strong correlation between the attended speech signal and the corresponding brain's elicited neuronal activities, which the latter can be measured using affordable and non-intrusive electroencephalography (EEG) devices. In this study, we present NeuroHeed, a speaker extraction model that leverages EEG signals to establish a neuronal attractor which is temporally associated with the speech stimulus, facilitating the extraction of the attended speech signal in a cocktail party scenario. We propose both an offline and an online NeuroHeed, with the latter designed for real-time inference. In the online NeuroHeed, we additionally propose an autoregressive speaker encoder, which accumulates past extracted speech signals for self-enrollment of the attended speaker information into an auditory attractor, that retains the attentional momentum over time. Online NeuroHeed extracts the current window of the speech signals with guidance from both attractors. Experimental results demonstrate that NeuroHeed effectively extracts brain-attended speech signals, achieving high signal quality, excellent perceptual quality, and intelligibility in a two-speaker scenario.
Fusion-S2iGan: An Efficient and Effective Single-Stage Framework for Speech-to-Image Generation
May 17, 2023
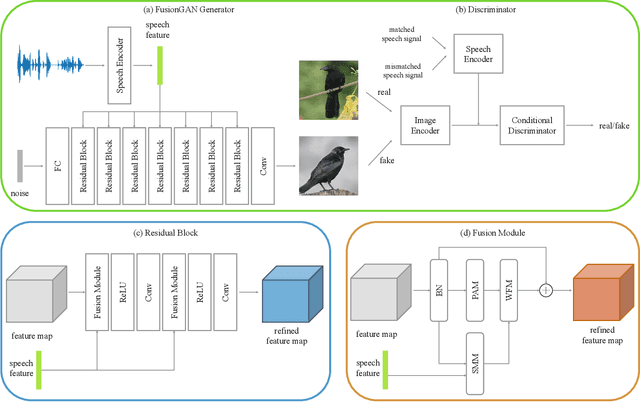
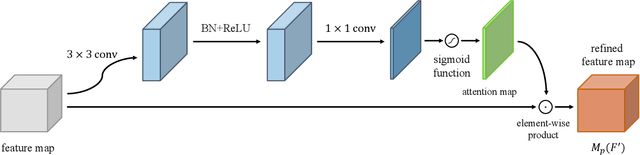
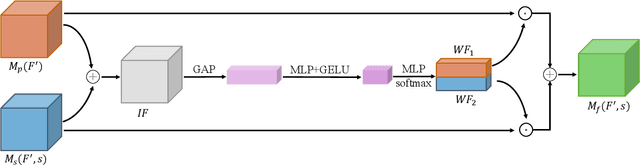
The goal of a speech-to-image transform is to produce a photo-realistic picture directly from a speech signal. Recently, various studies have focused on this task and have achieved promising performance. However, current speech-to-image approaches are based on a stacked modular framework that suffers from three vital issues: 1) Training separate networks is time-consuming as well as inefficient and the convergence of the final generative model strongly depends on the previous generators; 2) The quality of precursor images is ignored by this architecture; 3) Multiple discriminator networks are required to be trained. To this end, we propose an efficient and effective single-stage framework called Fusion-S2iGan to yield perceptually plausible and semantically consistent image samples on the basis of given spoken descriptions. Fusion-S2iGan introduces a visual+speech fusion module (VSFM), constructed with a pixel-attention module (PAM), a speech-modulation module (SMM) and a weighted-fusion module (WFM), to inject the speech embedding from a speech encoder into the generator while improving the quality of synthesized pictures. Fusion-S2iGan spreads the bimodal information over all layers of the generator network to reinforce the visual feature maps at various hierarchical levels in the architecture. We conduct a series of experiments on four benchmark data sets, i.e., CUB birds, Oxford-102, Flickr8k and Places-subset. The experimental results demonstrate the superiority of the presented Fusion-S2iGan compared to the state-of-the-art models with a multi-stage architecture and a performance level that is close to traditional text-to-image approaches.
Classifying Dementia in the Presence of Depression: A Cross-Corpus Study
Aug 16, 2023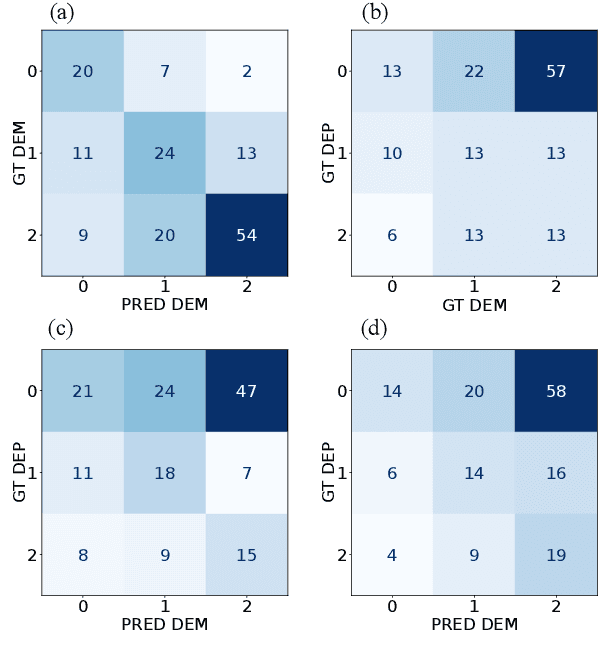
Automated dementia screening enables early detection and intervention, reducing costs to healthcare systems and increasing quality of life for those affected. Depression has shared symptoms with dementia, adding complexity to diagnoses. The research focus so far has been on binary classification of dementia (DEM) and healthy controls (HC) using speech from picture description tests from a single dataset. In this work, we apply established baseline systems to discriminate cognitive impairment in speech from the semantic Verbal Fluency Test and the Boston Naming Test using text, audio and emotion embeddings in a 3-class classification problem (HC vs. MCI vs. DEM). We perform cross-corpus and mixed-corpus experiments on two independently recorded German datasets to investigate generalization to larger populations and different recording conditions. In a detailed error analysis, we look at depression as a secondary diagnosis to understand what our classifiers actually learn.