 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDescription-based Controllable Text-to-Speech with Cross-Lingual Voice Control
Sep 26, 2024We propose a novel description-based controllable text-to-speech (TTS) method with cross-lingual control capability. To address the lack of audio-description paired data in the target language, we combine a TTS model trained on the target language with a description control model trained on another language, which maps input text descriptions to the conditional features of the TTS model. These two models share disentangled timbre and style representations based on self-supervised learning (SSL), allowing for disentangled voice control, such as controlling speaking styles while retaining the original timbre. Furthermore, because the SSL-based timbre and style representations are language-agnostic, combining the TTS and description control models while sharing the same embedding space effectively enables cross-lingual control of voice characteristics. Experiments on English and Japanese TTS demonstrate that our method achieves high naturalness and controllability for both languages, even though no Japanese audio-description pairs are used.
LibriTTS-P: A Corpus with Speaking Style and Speaker Identity Prompts for Text-to-Speech and Style Captioning
Jun 12, 2024



We introduce LibriTTS-P, a new corpus based on LibriTTS-R that includes utterance-level descriptions (i.e., prompts) of speaking style and speaker-level prompts of speaker characteristics. We employ a hybrid approach to construct prompt annotations: (1) manual annotations that capture human perceptions of speaker characteristics and (2) synthetic annotations on speaking style. Compared to existing English prompt datasets, our corpus provides more diverse prompt annotations for all speakers of LibriTTS-R. Experimental results for prompt-based controllable TTS demonstrate that the TTS model trained with LibriTTS-P achieves higher naturalness than the model using the conventional dataset. Furthermore, the results for style captioning tasks show that the model utilizing LibriTTS-P generates 2.5 times more accurate words than the model using a conventional dataset. Our corpus, LibriTTS-P, is available at https://github.com/line/LibriTTS-P.
Audio-conditioned phonemic and prosodic annotation for building text-to-speech models from unlabeled speech data
Jun 12, 2024



This paper proposes an audio-conditioned phonemic and prosodic annotation model for building text-to-speech (TTS) datasets from unlabeled speech samples. For creating a TTS dataset that consists of label-speech paired data, the proposed annotation model leverages an automatic speech recognition (ASR) model to obtain phonemic and prosodic labels from unlabeled speech samples. By fine-tuning a large-scale pre-trained ASR model, we can construct the annotation model using a limited amount of label-speech paired data within an existing TTS dataset. To alleviate the shortage of label-speech paired data for training the annotation model, we generate pseudo label-speech paired data using text-only corpora and an auxiliary TTS model. This TTS model is also trained with the existing TTS dataset. Experimental results show that the TTS model trained with the dataset created by the proposed annotation method can synthesize speech as naturally as the one trained with a fully-labeled dataset.
Noise-Robust Voice Conversion by Conditional Denoising Training Using Latent Variables of Recording Quality and Environment
Jun 11, 2024



We propose noise-robust voice conversion (VC) which takes into account the recording quality and environment of noisy source speech. Conventional denoising training improves the noise robustness of a VC model by learning noisy-to-clean VC process. However, the naturalness of the converted speech is limited when the noise of the source speech is unseen during the training. To this end, our proposed training conditions a VC model on two latent variables representing the recording quality and environment of the source speech. These latent variables are derived from deep neural networks pre-trained on recording quality assessment and acoustic scene classification and calculated in an utterance-wise or frame-wise manner. As a result, the trained VC model can explicitly learn information about speech degradation during the training. Objective and subjective evaluations show that our training improves the quality of the converted speech compared to the conventional training.
SRC4VC: Smartphone-Recorded Corpus for Voice Conversion Benchmark
Jun 11, 2024



We present SRC4VC, a new corpus containing 11 hours of speech recorded on smartphones by 100 Japanese speakers. Although high-quality multi-speaker corpora can advance voice conversion (VC) technologies, they are not always suitable for testing VC when low-quality speech recording is given as the input. To this end, we first asked 100 crowdworkers to record their voice samples using smartphones. Then, we annotated the recorded samples with speaker-wise recording-quality scores and utterance-wise perceived emotion labels. We also benchmark SRC4VC on any-to-any VC, in which we trained a multi-speaker VC model on high-quality speech and used the SRC4VC speakers' voice samples as the source in VC. The results show that the recording quality mismatch between the training and evaluation data significantly degrades the VC performance, which can be improved by applying speech enhancement to the low-quality source speech samples.
PromptTTS++: Controlling Speaker Identity in Prompt-Based Text-to-Speech Using Natural Language Descriptions
Sep 15, 2023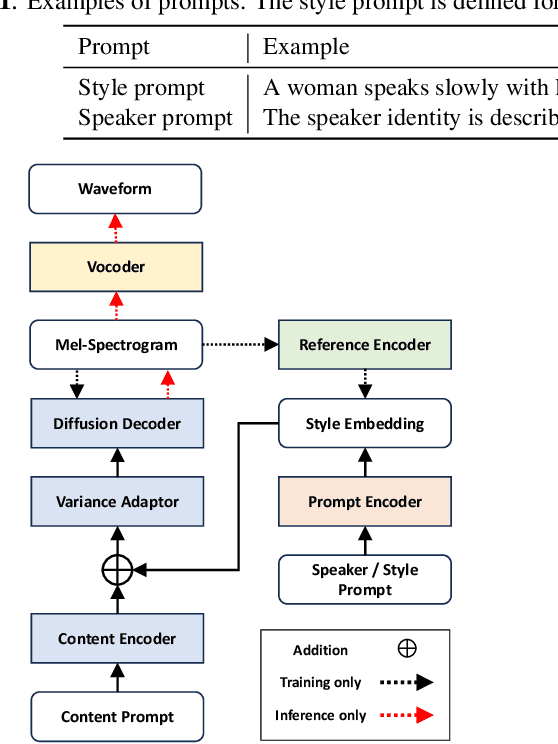
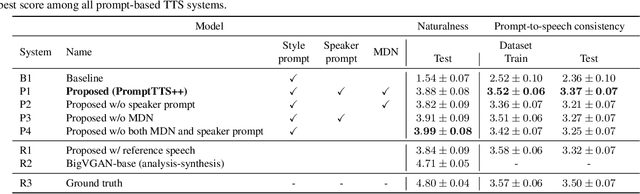
We propose PromptTTS++, a prompt-based text-to-speech (TTS) synthesis system that allows control over speaker identity using natural language descriptions. To control speaker identity within the prompt-based TTS framework, we introduce the concept of speaker prompt, which describes voice characteristics (e.g., gender-neutral, young, old, and muffled) designed to be approximately independent of speaking style. Since there is no large-scale dataset containing speaker prompts, we first construct a dataset based on the LibriTTS-R corpus with manually annotated speaker prompts. We then employ a diffusion-based acoustic model with mixture density networks to model diverse speaker factors in the training data. Unlike previous studies that rely on style prompts describing only a limited aspect of speaker individuality, such as pitch, speaking speed, and energy, our method utilizes an additional speaker prompt to effectively learn the mapping from natural language descriptions to the acoustic features of diverse speakers. Our subjective evaluation results show that the proposed method can better control speaker characteristics than the methods without the speaker prompt. Audio samples are available at https://reppy4620.github.io/demo.promptttspp/.
ChatGPT-EDSS: Empathetic Dialogue Speech Synthesis Trained from ChatGPT-derived Context Word Embeddings
May 23, 2023



We propose ChatGPT-EDSS, an empathetic dialogue speech synthesis (EDSS) method using ChatGPT for extracting dialogue context. ChatGPT is a chatbot that can deeply understand the content and purpose of an input prompt and appropriately respond to the user's request. We focus on ChatGPT's reading comprehension and introduce it to EDSS, a task of synthesizing speech that can empathize with the interlocutor's emotion. Our method first gives chat history to ChatGPT and asks it to generate three words representing the intention, emotion, and speaking style for each line in the chat. Then, it trains an EDSS model using the embeddings of ChatGPT-derived context words as the conditioning features. The experimental results demonstrate that our method performs comparably to ones using emotion labels or neural network-derived context embeddings learned from chat histories. The collected ChatGPT-derived context information is available at https://sarulab-speech.github.io/demo_ChatGPT_EDSS/.
CALLS: Japanese Empathetic Dialogue Speech Corpus of Complaint Handling and Attentive Listening in Customer Center
May 23, 2023We present CALLS, a Japanese speech corpus that considers phone calls in a customer center as a new domain of empathetic spoken dialogue. The existing STUDIES corpus covers only empathetic dialogue between a teacher and student in a school. To extend the application range of empathetic dialogue speech synthesis (EDSS), we designed our corpus to include the same female speaker as the STUDIES teacher, acting as an operator in simulated phone calls. We describe a corpus construction methodology and analyze the recorded speech. We also conduct EDSS experiments using the CALLS and STUDIES corpora to investigate the effect of domain differences. The results show that mixing the two corpora during training causes biased improvements in the quality of synthetic speech due to the different degrees of expressiveness. Our project page of the corpus is http://sython.org/Corpus/STUDIES-2.
Nonparallel High-Quality Audio Super Resolution with Domain Adaptation and Resampling CycleGANs
Oct 28, 2022


Neural audio super-resolution models are typically trained on low- and high-resolution audio signal pairs. Although these methods achieve highly accurate super-resolution if the acoustic characteristics of the input data are similar to those of the training data, challenges remain: the models suffer from quality degradation for out-of-domain data, and paired data are required for training. To address these problems, we propose Dual-CycleGAN, a high-quality audio super-resolution method that can utilize unpaired data based on two connected cycle consistent generative adversarial networks (CycleGAN). Our method decomposes the super-resolution method into domain adaptation and resampling processes to handle acoustic mismatch in the unpaired low- and high-resolution signals. The two processes are then jointly optimized within the CycleGAN framework. Experimental results verify that the proposed method significantly outperforms conventional methods when paired data are not available. Code and audio samples are available from https://chomeyama.github.io/DualCycleGAN-Demo/.
Period VITS: Variational Inference with Explicit Pitch Modeling for End-to-end Emotional Speech Synthesis
Oct 28, 2022



Several fully end-to-end text-to-speech (TTS) models have been proposed that have shown better performance compared to cascade models (i.e., training acoustic and vocoder models separately). However, they often generate unstable pitch contour with audible artifacts when the dataset contains emotional attributes, i.e., large diversity of pronunciation and prosody. To address this problem, we propose Period VITS, a novel end-to-end TTS model that incorporates an explicit periodicity generator. In the proposed method, we introduce a frame pitch predictor that predicts prosodic features, such as pitch and voicing flags, from the input text. From these features, the proposed periodicity generator produces a sample-level sinusoidal source that enables the waveform decoder to accurately reproduce the pitch. Finally, the entire model is jointly optimized in an end-to-end manner with variational inference and adversarial objectives. As a result, the decoder becomes capable of generating more stable, expressive, and natural output waveforms. The experimental results showed that the proposed model significantly outperforms baseline models in terms of naturalness, with improved pitch stability in the generated samples.