 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Semantic-WER: A Unified Metric for the Evaluation of ASR Transcript for End Usability
Jun 03, 2021

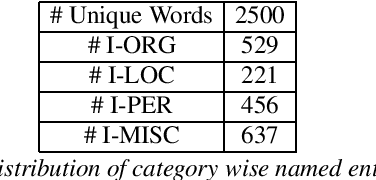

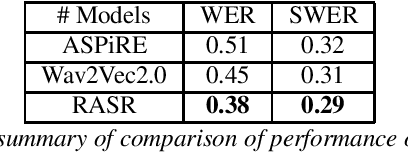
Recent advances in supervised, semi-supervised and self-supervised deep learning algorithms have shown significant improvement in the performance of automatic speech recognition(ASR) systems. The state-of-the-art systems have achieved a word error rate (WER) less than 5%. However, in the past, researchers have argued the non-suitability of the WER metric for the evaluation of ASR systems for downstream tasks such as spoken language understanding (SLU) and information retrieval. The reason is that the WER works at the surface level and does not include any syntactic and semantic knowledge.The current work proposes Semantic-WER (SWER), a metric to evaluate the ASR transcripts for downstream applications in general. The SWER can be easily customized for any down-stream task.
EESEN: End-to-End Speech Recognition using Deep RNN Models and WFST-based Decoding
Oct 18, 2015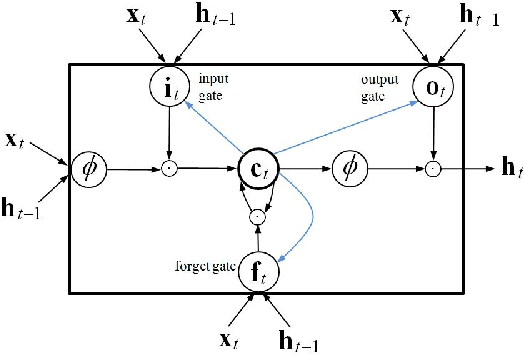

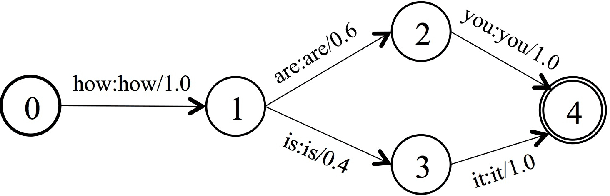

The performance of automatic speech recognition (ASR) has improved tremendously due to the application of deep neural networks (DNNs). Despite this progress, building a new ASR system remains a challenging task, requiring various resources, multiple training stages and significant expertise. This paper presents our Eesen framework which drastically simplifies the existing pipeline to build state-of-the-art ASR systems. Acoustic modeling in Eesen involves learning a single recurrent neural network (RNN) predicting context-independent targets (phonemes or characters). To remove the need for pre-generated frame labels, we adopt the connectionist temporal classification (CTC) objective function to infer the alignments between speech and label sequences. A distinctive feature of Eesen is a generalized decoding approach based on weighted finite-state transducers (WFSTs), which enables the efficient incorporation of lexicons and language models into CTC decoding. Experiments show that compared with the standard hybrid DNN systems, Eesen achieves comparable word error rates (WERs), while at the same time speeding up decoding significantly.
ISyNet: Convolutional Neural Networks design for AI accelerator
Sep 04, 2021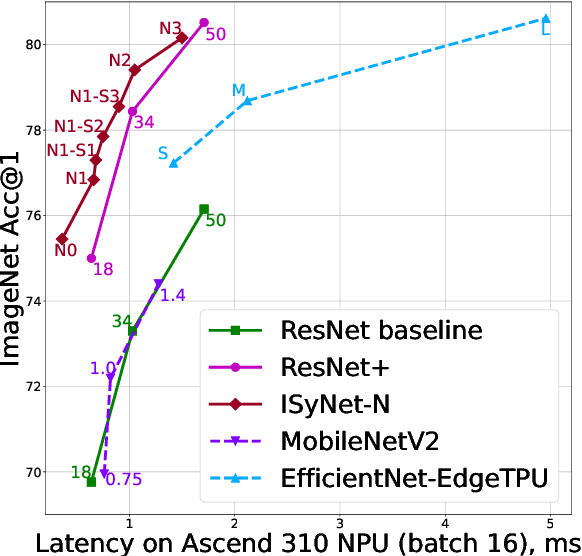
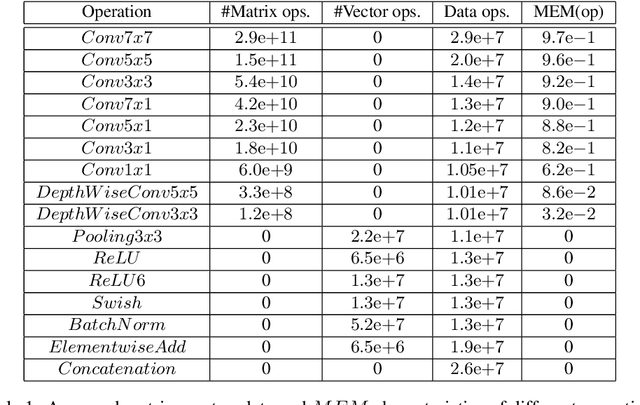
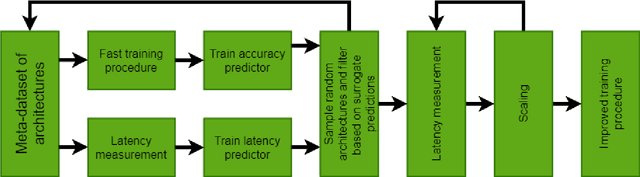
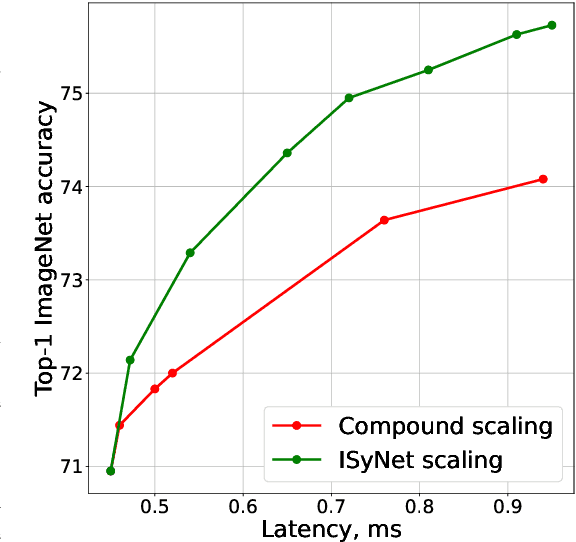
In recent years Deep Learning reached significant results in many practical problems, such as computer vision, natural language processing, speech recognition and many others. For many years the main goal of the research was to improve the quality of models, even if the complexity was impractically high. However, for the production solutions, which often require real-time work, the latency of the model plays a very important role. Current state-of-the-art architectures are found with neural architecture search (NAS) taking model complexity into account. However, designing of the search space suitable for specific hardware is still a challenging task. To address this problem we propose a measure of hardware efficiency of neural architecture search space - matrix efficiency measure (MEM); a search space comprising of hardware-efficient operations; a latency-aware scaling method; and ISyNet - a set of architectures designed to be fast on the specialized neural processing unit (NPU) hardware and accurate at the same time. We show the advantage of the designed architectures for the NPU devices on ImageNet and the generalization ability for the downstream classification and detection tasks.
Time-Domain Mapping Based Single-Channel Speech Separation With Hierarchical Constraint Training
Oct 20, 2021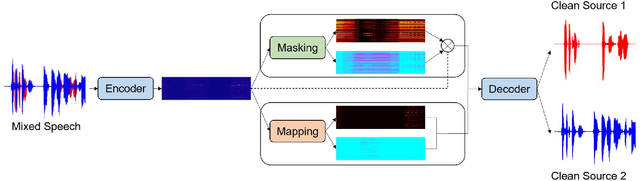
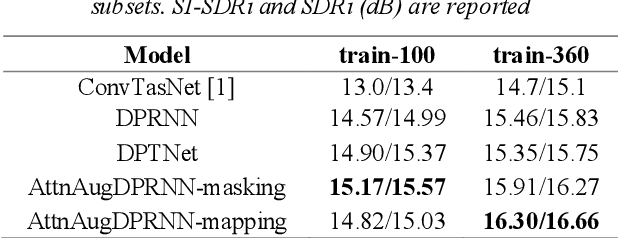

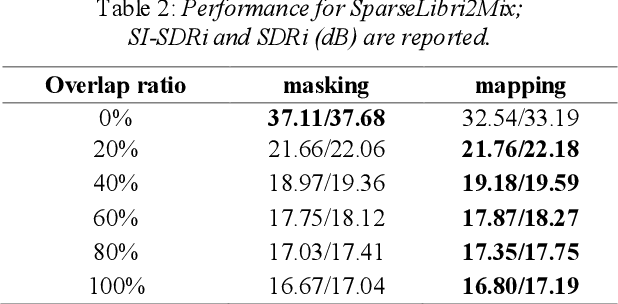
Single-channel speech separation is required for multi-speaker speech recognition. Recent deep learning-based approaches focused on time-domain audio separation net (TasNet) because it has superior performance and lower latency compared to the conventional time-frequency-based (T-F-based) approaches. Most of these works rely on the masking-based method that estimates a linear mapping function (mask) for each speaker. However, the other commonly used method, the mapping-based method that is less sensitive to SNR variations, is inadequately studied in the time domain. We explore the potential of the mapping-based method by introducing attention augmented DPRNN (AttnAugDPRNN) which directly approximates the clean sources from the mixture for speech separation. Permutation Invariant Training (PIT) has been a paradigm to solve the label ambiguity problem for speech separation but usually leads to suboptimal performance. To solve this problem, we propose an efficient training strategy called Hierarchical Constraint Training (HCT) to regularize the training, which could effectively improve the model performance. When using PIT, our results showed that mapping-based AttnAugDPRNN outperformed masking-based AttnAugDPRNN when the training corpus is large. Mapping-based AttnAugDPRNN with HCT significantly improved the SI-SDR by 10.1% compared to the masking-based AttnAugDPRNN without HCT.
Byakto Speech: Real-time long speech synthesis with convolutional neural network: Transfer learning from English to Bangla
May 31, 2021
Speech synthesis is one of the challenging tasks to automate by deep learning, also being a low-resource language there are very few attempts at Bangla speech synthesis. Most of the existing works can't work with anything other than simple Bangla characters script, very short sentences, etc. This work attempts to solve these problems by introducing Byakta, the first-ever open-source deep learning-based bilingual (Bangla and English) text to a speech synthesis system. A speech recognition model-based automated scoring metric was also proposed to evaluate the performance of a TTS model. We also introduce a test benchmark dataset for Bangla speech synthesis models for evaluating speech quality. The TTS is available at https://github.com/zabir-nabil/bangla-tts
BSTC: A Large-Scale Chinese-English Speech Translation Dataset
Apr 19, 2021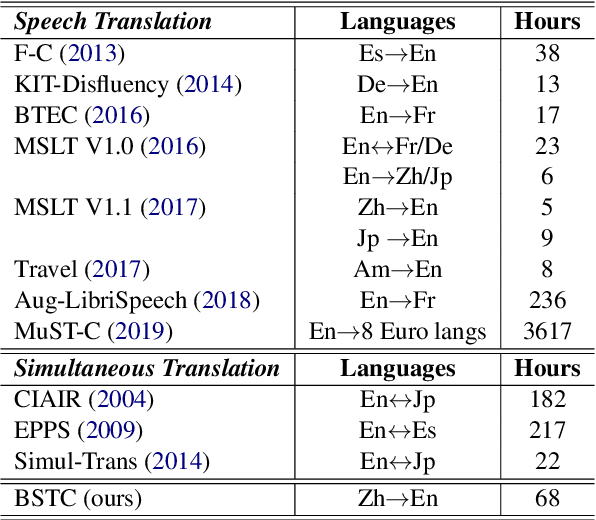
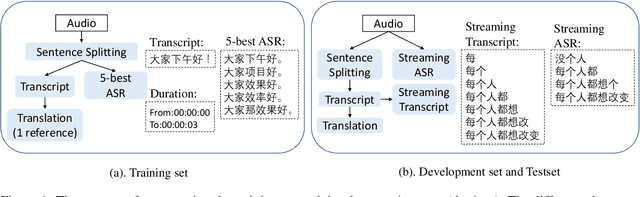

This paper presents BSTC (Baidu Speech Translation Corpus), a large-scale Chinese-English speech translation dataset. This dataset is constructed based on a collection of licensed videos of talks or lectures, including about 68 hours of Mandarin data, their manual transcripts and translations into English, as well as automated transcripts by an automatic speech recognition (ASR) model. We have further asked three experienced interpreters to simultaneously interpret the testing talks in a mock conference setting. This corpus is expected to promote the research of automatic simultaneous translation as well as the development of practical systems. We have organized simultaneous translation tasks and used this corpus to evaluate automatic simultaneous translation systems.
Improving callsign recognition with air-surveillance data in air-traffic communication
Aug 27, 2021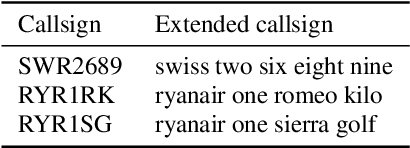
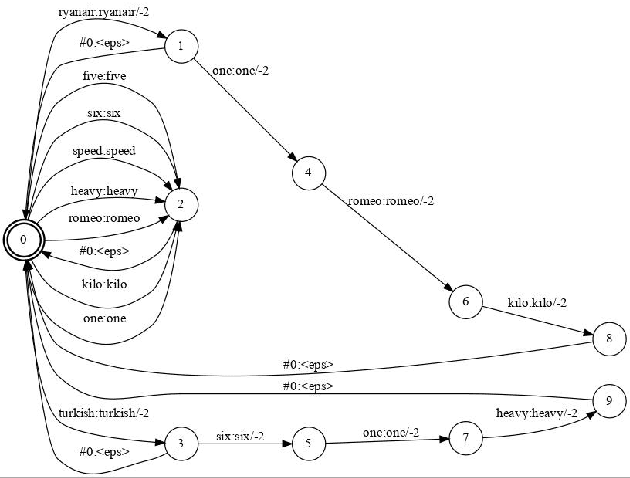
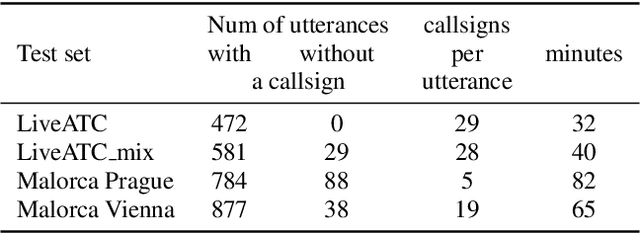
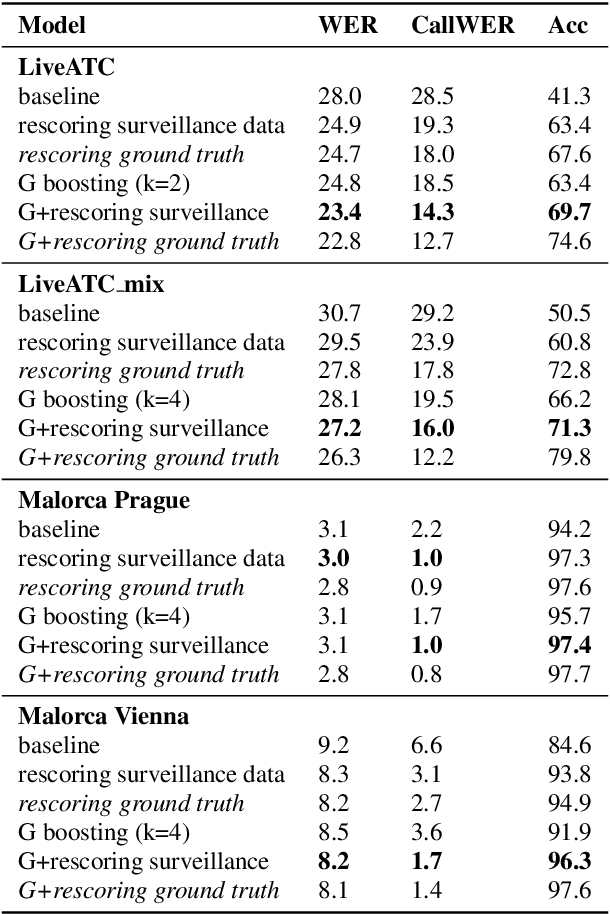
Automatic Speech Recognition (ASR) can be used as the assistance of speech communication between pilots and air-traffic controllers. Its application can significantly reduce the complexity of the task and increase the reliability of transmitted information. Evidently, high accuracy predictions are needed to minimize the risk of errors. Especially, high accuracy is required in recognition of key information, such as commands and callsigns, used to navigate pilots. Our results prove that the surveillance data containing callsigns can help to considerably improve the recognition of a callsign in an utterance when the weights of probable callsign n-grams are reduced per utterance. In this paper, we investigate two approaches: (1) G-boosting, when callsigns weights are adjusted at language model level (G) and followed by the dynamic decoder with an on-the-fly composition, and (2) lattice rescoring when callsign information is introduced on top of lattices generated using a conventional decoder. Boosting callsign n-grams with the combination of two methods allowed us to gain 28.4% of absolute improvement in callsign recognition accuracy and up to 74.2% of relative improvement in WER of callsign recognition.
Novel Dual-Channel Long Short-Term Memory Compressed Capsule Networks for Emotion Recognition
Dec 26, 2021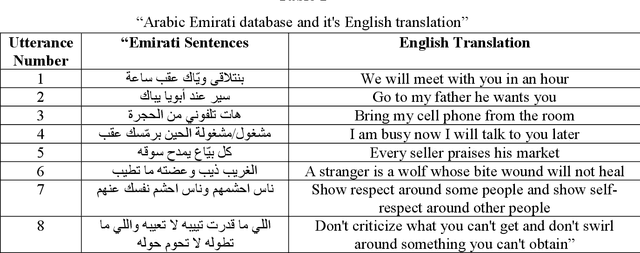
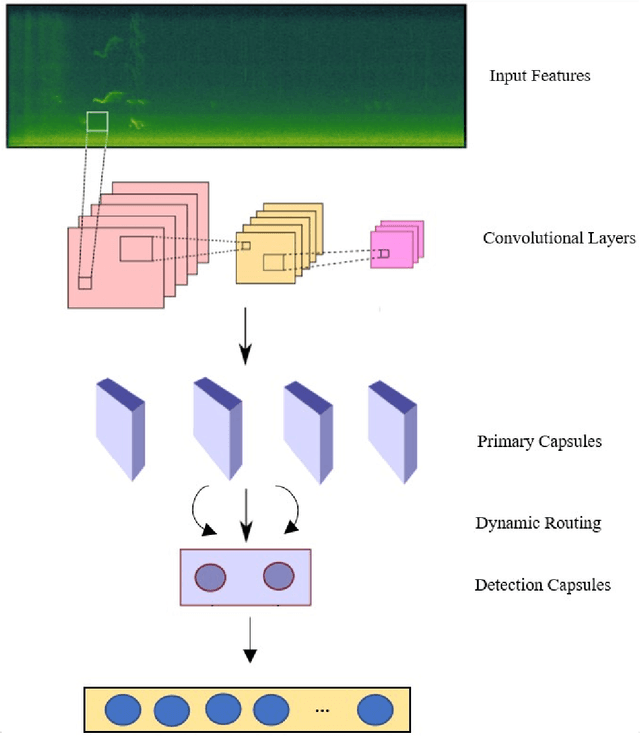
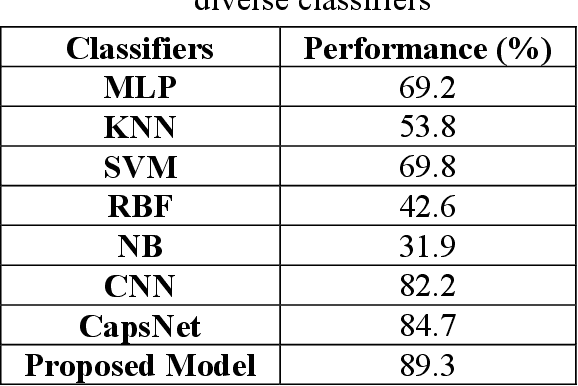
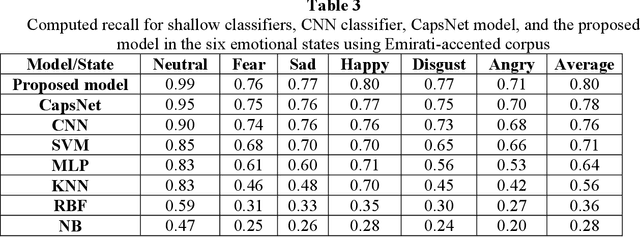
Recent analysis on speech emotion recognition has made considerable advances with the use of MFCCs spectrogram features and the implementation of neural network approaches such as convolutional neural networks (CNNs). Capsule networks (CapsNet) have gained gratitude as alternatives to CNNs with their larger capacities for hierarchical representation. To address these issues, this research introduces a text-independent and speaker-independent SER novel architecture, where a dual-channel long short-term memory compressed-CapsNet (DC-LSTM COMP-CapsNet) algorithm is proposed based on the structural features of CapsNet. Our proposed novel classifier can ensure the energy efficiency of the model and adequate compression method in speech emotion recognition, which is not delivered through the original structure of a CapsNet. Moreover, the grid search approach is used to attain optimal solutions. Results witnessed an improved performance and reduction in the training and testing running time. The speech datasets used to evaluate our algorithm are: Arabic Emirati-accented corpus, English speech under simulated and actual stress corpus, English Ryerson audio-visual database of emotional speech and song corpus, and crowd-sourced emotional multimodal actors dataset. This work reveals that the optimum feature extraction method compared to other known methods is MFCCs delta-delta. Using the four datasets and the MFCCs delta-delta, DC-LSTM COMP-CapsNet surpasses all the state-of-the-art systems, classical classifiers, CNN, and the original CapsNet. Using the Arabic Emirati-accented corpus, our results demonstrate that the proposed work yields average emotion recognition accuracy of 89.3% compared to 84.7%, 82.2%, 69.8%, 69.2%, 53.8%, 42.6%, and 31.9% based on CapsNet, CNN, support vector machine, multi-layer perceptron, k-nearest neighbor, radial basis function, and naive Bayes, respectively.
* 19 pages, 11 figures
Blind and neural network-guided convolutional beamformer for joint denoising, dereverberation, and source separation
Aug 04, 2021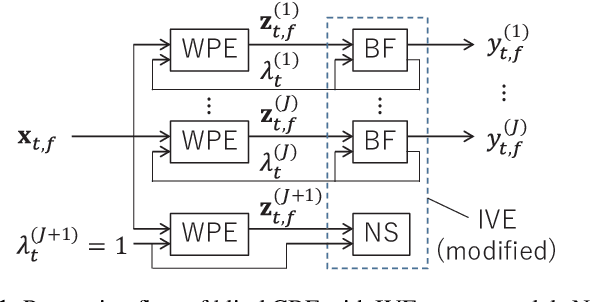
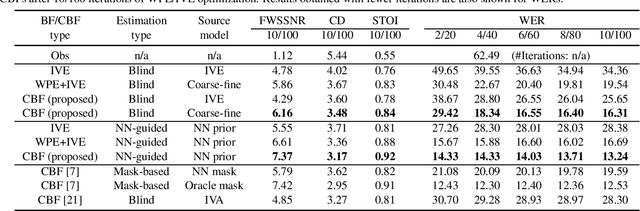
This paper proposes an approach for optimizing a Convolutional BeamFormer (CBF) that can jointly perform denoising (DN), dereverberation (DR), and source separation (SS). First, we develop a blind CBF optimization algorithm that requires no prior information on the sources or the room acoustics, by extending a conventional joint DR and SS method. For making the optimization computationally tractable, we incorporate two techniques into the approach: the Source-Wise Factorization (SW-Fact) of a CBF and the Independent Vector Extraction (IVE). To further improve the performance, we develop a method that integrates a neural network(NN) based source power spectra estimation with CBF optimization by an inverse-Gamma prior. Experiments using noisy reverberant mixtures reveal that our proposed method with both blind and NN-guided scenarios greatly outperforms the conventional state-of-the-art NN-supported mask-based CBF in terms of the improvement in automatic speech recognition and signal distortion reduction performance.
A Review of Speaker Diarization: Recent Advances with Deep Learning
Jan 24, 2021
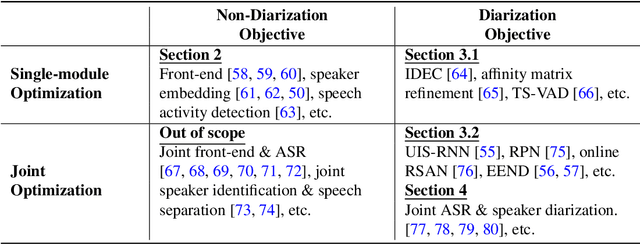
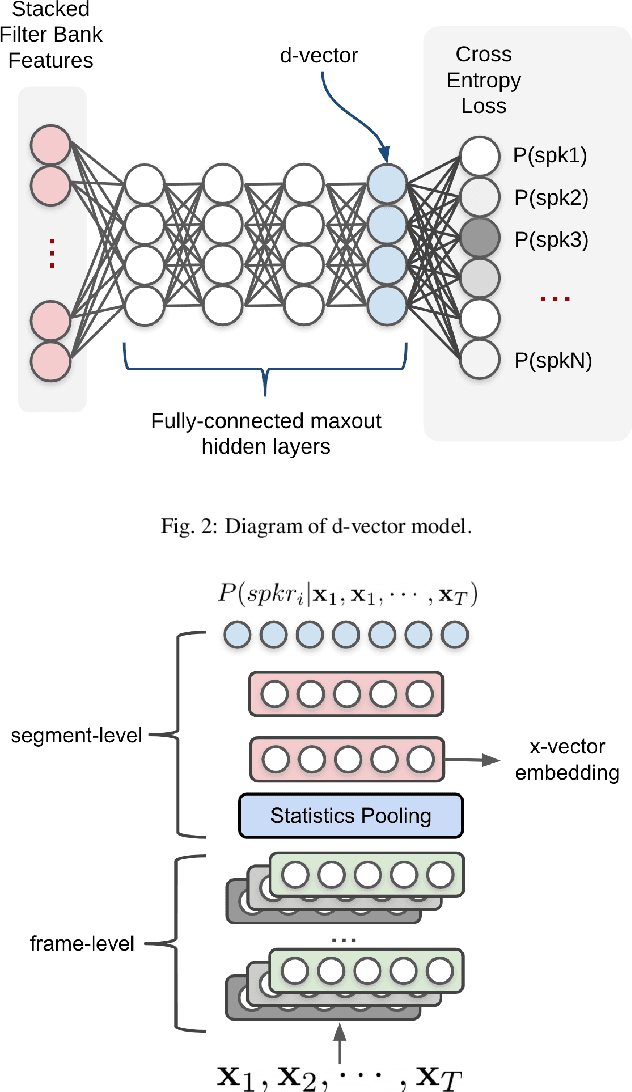
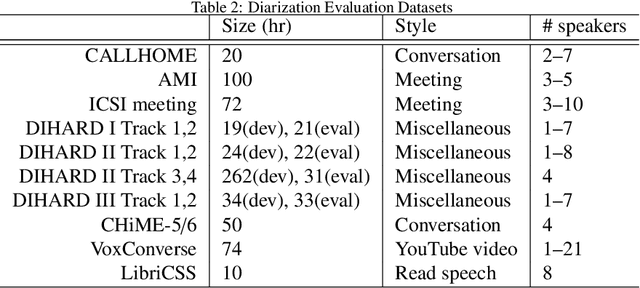
Speaker diarization is a task to label audio or video recordings with classes corresponding to speaker identity, or in short, a task to identify "who spoke when". In the early years, speaker diarization algorithms were developed for speech recognition on multi-speaker audio recordings to enable speaker adaptive processing, but also gained its own value as a stand-alone application over time to provide speaker-specific meta information for downstream tasks such as audio retrieval. More recently, with the rise of deep learning technology that has been a driving force to revolutionary changes in research and practices across speech application domains in the past decade, more rapid advancements have been made for speaker diarization. In this paper, we review not only the historical development of speaker diarization technology but also the recent advancements in neural speaker diarization approaches. We also discuss how speaker diarization systems have been integrated with speech recognition applications and how the recent surge of deep learning is leading the way of jointly modeling these two components to be complementary to each other. By considering such exciting technical trends, we believe that it is a valuable contribution to the community to provide a survey work by consolidating the recent developments with neural methods and thus facilitating further progress towards a more efficient speaker diarization.