 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKandinsky 5.0: A Family of Foundation Models for Image and Video Generation
Nov 19, 2025



This report introduces Kandinsky 5.0, a family of state-of-the-art foundation models for high-resolution image and 10-second video synthesis. The framework comprises three core line-up of models: Kandinsky 5.0 Image Lite - a line-up of 6B parameter image generation models, Kandinsky 5.0 Video Lite - a fast and lightweight 2B parameter text-to-video and image-to-video models, and Kandinsky 5.0 Video Pro - 19B parameter models that achieves superior video generation quality. We provide a comprehensive review of the data curation lifecycle - including collection, processing, filtering and clustering - for the multi-stage training pipeline that involves extensive pre-training and incorporates quality-enhancement techniques such as self-supervised fine-tuning (SFT) and reinforcement learning (RL)-based post-training. We also present novel architectural, training, and inference optimizations that enable Kandinsky 5.0 to achieve high generation speeds and state-of-the-art performance across various tasks, as demonstrated by human evaluation. As a large-scale, publicly available generative framework, Kandinsky 5.0 leverages the full potential of its pre-training and subsequent stages to be adapted for a wide range of generative applications. We hope that this report, together with the release of our open-source code and training checkpoints, will substantially advance the development and accessibility of high-quality generative models for the research community.
ISyNet: Convolutional Neural Networks design for AI accelerator
Sep 04, 2021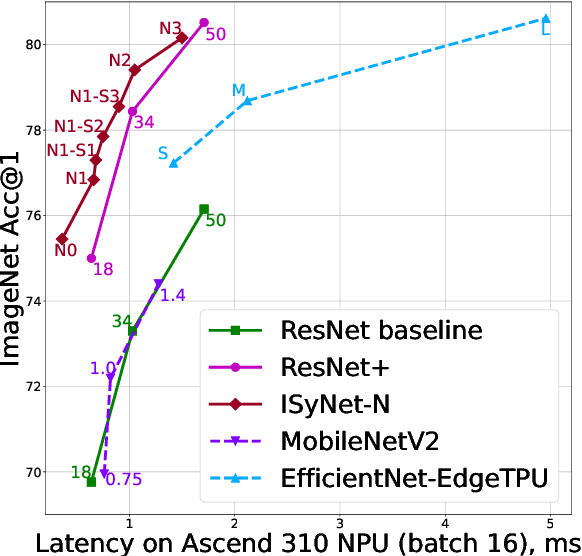
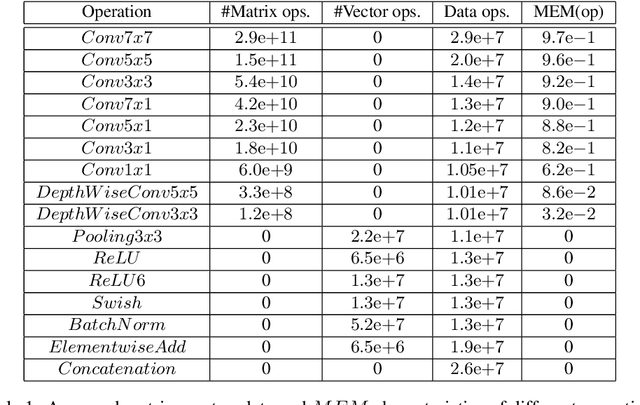
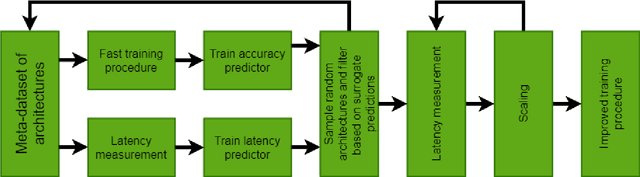
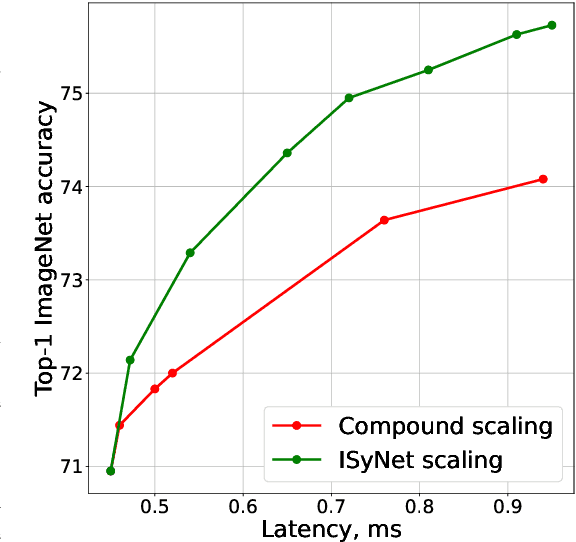
In recent years Deep Learning reached significant results in many practical problems, such as computer vision, natural language processing, speech recognition and many others. For many years the main goal of the research was to improve the quality of models, even if the complexity was impractically high. However, for the production solutions, which often require real-time work, the latency of the model plays a very important role. Current state-of-the-art architectures are found with neural architecture search (NAS) taking model complexity into account. However, designing of the search space suitable for specific hardware is still a challenging task. To address this problem we propose a measure of hardware efficiency of neural architecture search space - matrix efficiency measure (MEM); a search space comprising of hardware-efficient operations; a latency-aware scaling method; and ISyNet - a set of architectures designed to be fast on the specialized neural processing unit (NPU) hardware and accurate at the same time. We show the advantage of the designed architectures for the NPU devices on ImageNet and the generalization ability for the downstream classification and detection tasks.