 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Impact of Post-Training Quantization on Large Language Models
Sep 17, 2023Large language models (LLMs) are rapidly increasing in size, with the number of parameters becoming a key factor in the success of many commercial models, such as ChatGPT, Claude, and Bard. Even the recently released publicly accessible models for commercial usage, such as Falcon and Llama2, come equipped with billions of parameters. This significant increase in the number of parameters makes deployment and operation very costly. The remarkable progress in the field of quantization for large neural networks in general and LLMs in particular, has made these models more accessible by enabling them to be deployed on consumer-grade GPUs. Quantized models generally demonstrate comparable performance levels to their unquantized base counterparts. Nonetheless, there exists a notable gap in our comprehensive understanding of how these quantized models respond to hyperparameters, such as temperature, max new tokens, and topk, particularly for next word prediction. The present analysis reveals that nf4 and fp4 are equally proficient 4-bit quantization techniques, characterized by similar attributes such as inference speed, memory consumption, and the quality of generated content. the study identifies nf4 as displaying greater resilience to temperature variations in the case of the llama2 series of models at lower temperature, while fp4 and fp4-dq proves to be a more suitable choice for falcon series of models. It is noteworthy that, in general, 4-bit quantized models of varying sizes exhibit higher sensitivity to temperature in the range of 0.5 to 0.8, unlike their unquantized counterparts. Additionally, int8 quantization is associated with significantly slower inference speeds, whereas unquantized bfloat16 models consistently yield the fastest inference speeds across models of all sizes.
Semantic-WER: A Unified Metric for the Evaluation of ASR Transcript for End Usability
Jun 03, 2021
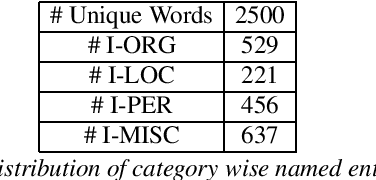

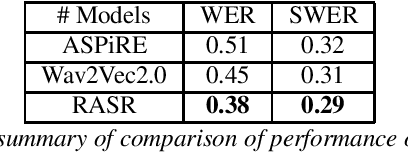
Recent advances in supervised, semi-supervised and self-supervised deep learning algorithms have shown significant improvement in the performance of automatic speech recognition(ASR) systems. The state-of-the-art systems have achieved a word error rate (WER) less than 5%. However, in the past, researchers have argued the non-suitability of the WER metric for the evaluation of ASR systems for downstream tasks such as spoken language understanding (SLU) and information retrieval. The reason is that the WER works at the surface level and does not include any syntactic and semantic knowledge.The current work proposes Semantic-WER (SWER), a metric to evaluate the ASR transcripts for downstream applications in general. The SWER can be easily customized for any down-stream task.
A Systematic Review of Hindi Prosody
May 09, 2017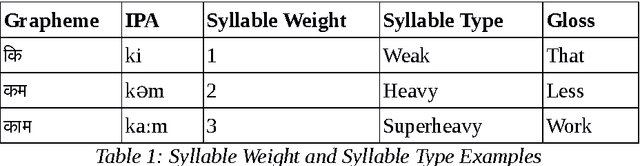
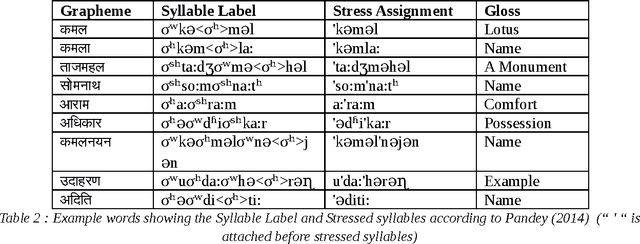
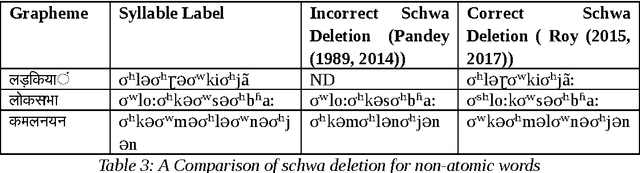

Prosody describes both form and function of a sentence using the suprasegmental features of speech. Prosody phenomena are explored in the domain of higher phonological constituents such as word, phonological phrase and intonational phrase. The study of prosody at the word level is called word prosody and above word level is called sentence prosody. Word Prosody describes stress pattern by comparing the prosodic features of its constituent syllables. Sentence Prosody involves the study on phrasing pattern and intonatonal pattern of a language. The aim of this study is to summarize the existing works on Hindi prosody carried out in different domain of language and speech processing. The review is presented in a systematic fashion so that it could be a useful resource for one who wants to build on the existing works.
A Generative Model of a Pronunciation Lexicon for Hindi
May 06, 2017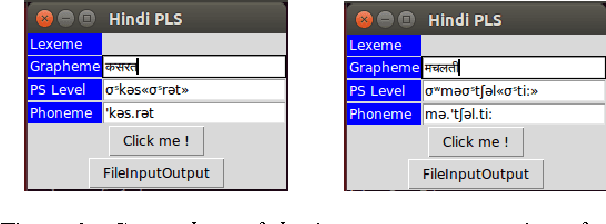
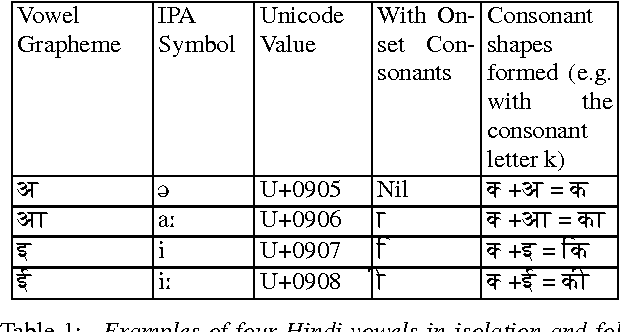
Voice browser applications in Text-to- Speech (TTS) and Automatic Speech Recognition (ASR) systems crucially depend on a pronunciation lexicon. The present paper describes the model of pronunciation lexicon of Hindi developed to automatically generate the output forms of Hindi at two levels, the <phoneme> and the <PS> (PS, in short for Prosodic Structure). The latter level involves both syllable-division and stress placement. The paper describes the tool developed for generating the two-level outputs of lexica in Hindi.
A Finite State and Rule-based Akshara to Prosodeme Converter in Hindi
May 04, 2017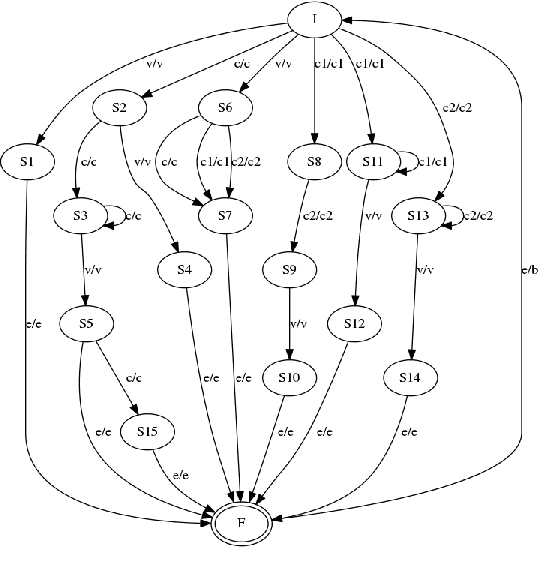
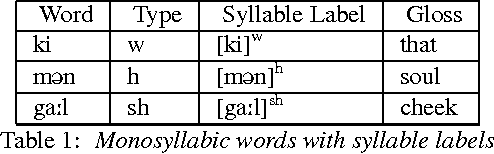

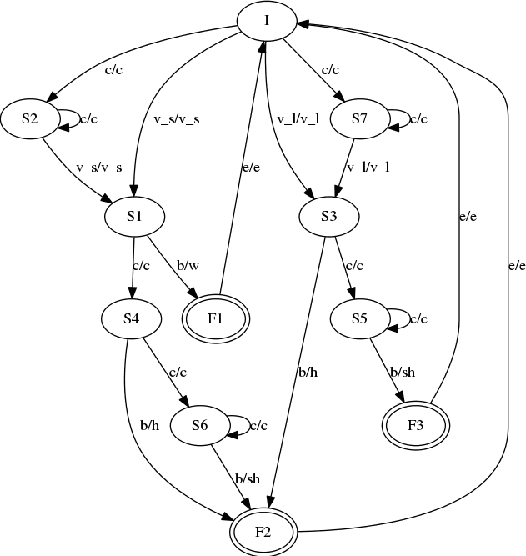
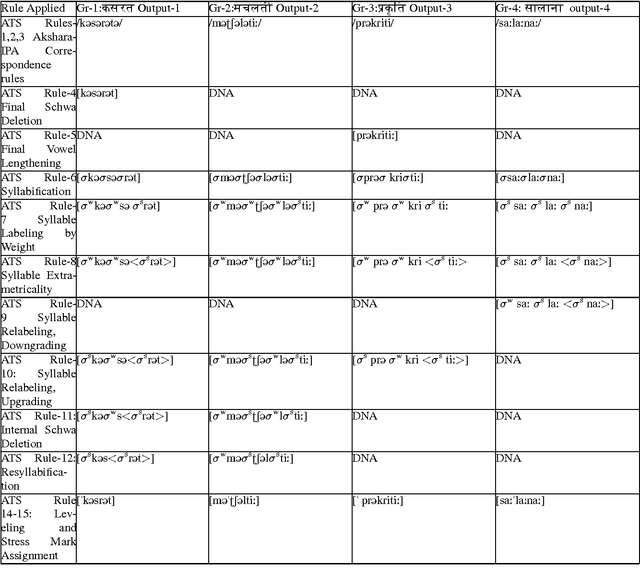
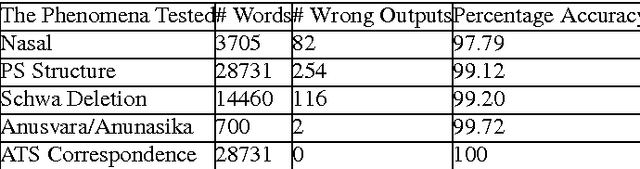
This article describes a software module called Akshara to Prosodeme (A2P) converter in Hindi. It converts an input grapheme into prosedeme (sequence of phonemes with the specification of syllable boundaries and prosodic labels). The software is based on two proposed finite state machines\textemdash one for the syllabification and another for the syllable labeling. In addition to that, it also uses a set of nonlinear phonological rules proposed for foot formation in Hindi, which encompass solutions to schwa-deletion in simple, compound, derived and inflected words. The nonlinear phonological rules are based on metrical phonology with the provision of recursive foot structure. A software module is implemented in Python. The testing of the software for syllabification, syllable labeling, schwa deletion and prosodic labeling yield an accuracy of more than 99% on a lexicon of size 28664 words.