 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Speaker Diarization: Recent Advances with Deep Learning
Paper and Code
Jan 24, 2021
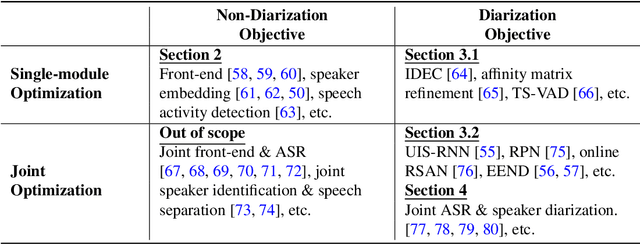
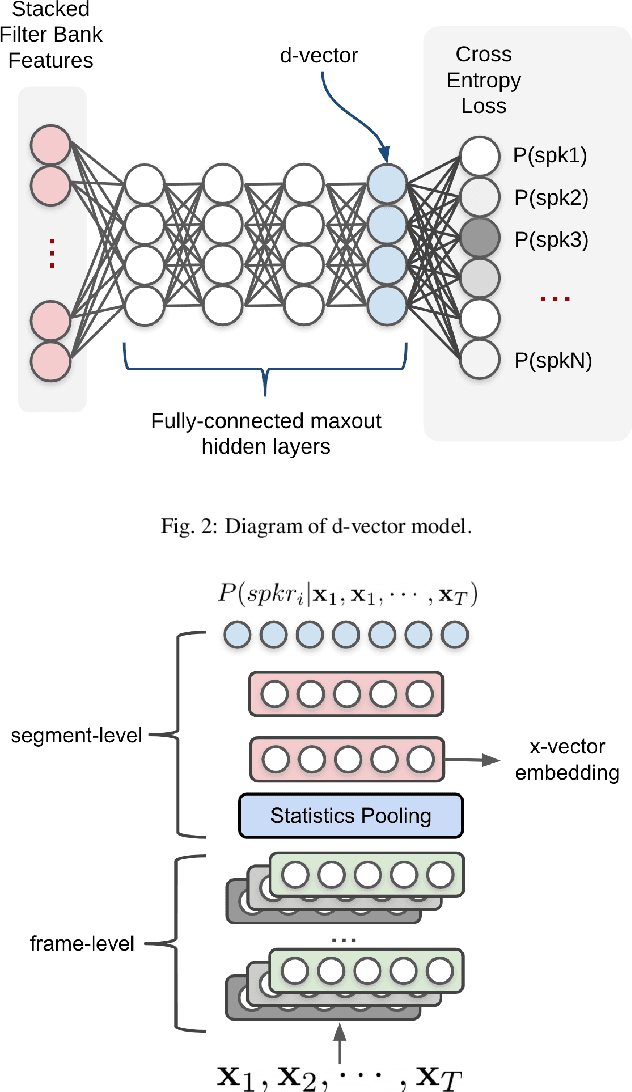
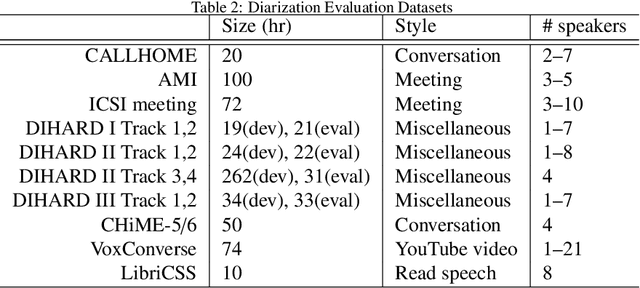
Speaker diarization is a task to label audio or video recordings with classes corresponding to speaker identity, or in short, a task to identify "who spoke when". In the early years, speaker diarization algorithms were developed for speech recognition on multi-speaker audio recordings to enable speaker adaptive processing, but also gained its own value as a stand-alone application over time to provide speaker-specific meta information for downstream tasks such as audio retrieval. More recently, with the rise of deep learning technology that has been a driving force to revolutionary changes in research and practices across speech application domains in the past decade, more rapid advancements have been made for speaker diarization. In this paper, we review not only the historical development of speaker diarization technology but also the recent advancements in neural speaker diarization approaches. We also discuss how speaker diarization systems have been integrated with speech recognition applications and how the recent surge of deep learning is leading the way of jointly modeling these two components to be complementary to each other. By considering such exciting technical trends, we believe that it is a valuable contribution to the community to provide a survey work by consolidating the recent developments with neural methods and thus facilitating further progress towards a more efficient speaker diarization.