 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Cycle-consistency training for end-to-end speech recognition
Nov 02, 2018
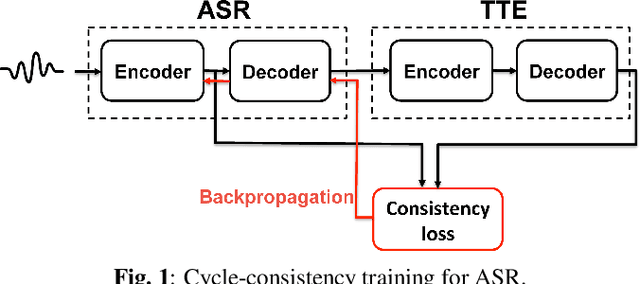
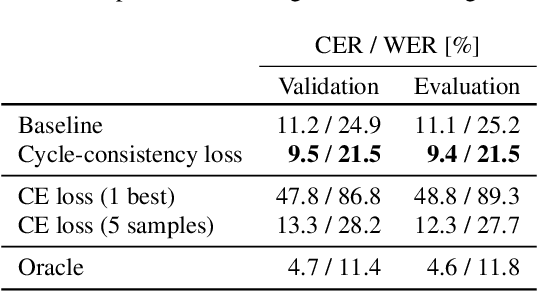
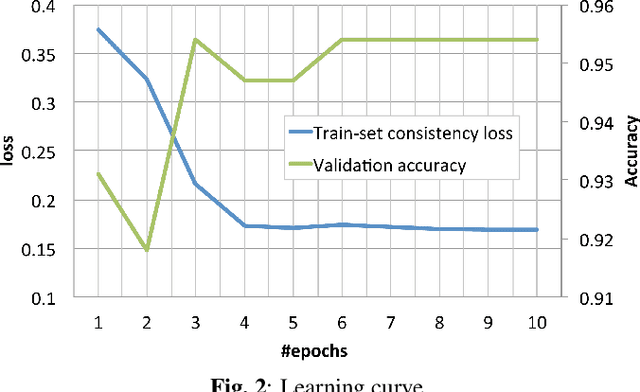

This paper presents a method to train end-to-end automatic speech recognition (ASR) models using unpaired data. Although the end-to-end approach can eliminate the need for expert knowledge such as pronunciation dictionaries to build ASR systems, it still requires a large amount of paired data, i.e., speech utterances and their transcriptions. Cycle-consistency losses have been recently proposed as a way to mitigate the problem of limited paired data. These approaches compose a reverse operation with a given transformation, e.g., text-to-speech (TTS) with ASR, to build a loss that only requires unsupervised data, speech in this example. Applying cycle consistency to ASR models is not trivial since fundamental information, such as speaker traits, are lost in the intermediate text bottleneck. To solve this problem, this work presents a loss that is based on the speech encoder state sequence instead of the raw speech signal. This is achieved by training a Text-To-Encoder model and defining a loss based on the encoder reconstruction error. Experimental results on the LibriSpeech corpus show that the proposed cycle-consistency training reduced the word error rate by 14.7% from an initial model trained with 100-hour paired data, using an additional 360 hours of audio data without transcriptions. We also investigate the use of text-only data mainly for language modeling to further improve the performance in the unpaired data training scenario.
Minimising Biasing Word Errors for Contextual ASR with the Tree-Constrained Pointer Generator
May 18, 2022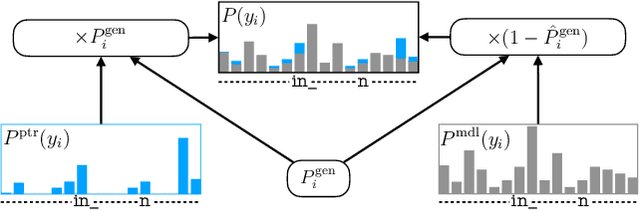
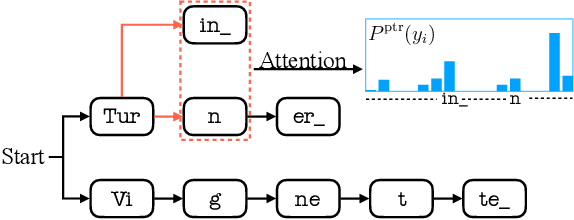
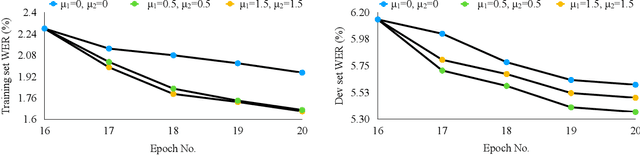
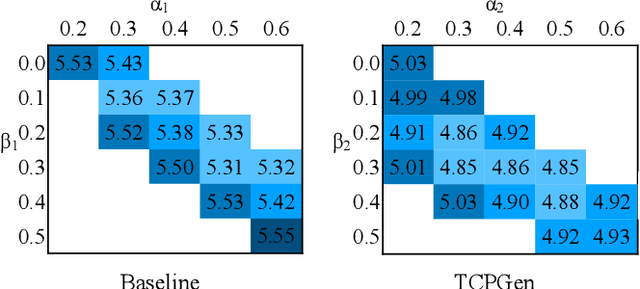
Contextual knowledge is essential for reducing speech recognition errors on high-valued long-tail words. This paper proposes a novel tree-constrained pointer generator (TCPGen) component that enables end-to-end ASR models to bias towards a list of long-tail words obtained using external contextual information. With only a small overhead in memory use and computation cost, TCPGen can structure thousands of biasing words efficiently into a symbolic prefix-tree and creates a neural shortcut between the tree and the final ASR output to facilitate the recognition of the biasing words. To enhance TCPGen, we further propose a novel minimum biasing word error (MBWE) loss that directly optimises biasing word errors during training, along with a biasing-word-driven language model discounting (BLMD) method during the test. All contextual ASR systems were evaluated on the public Librispeech audiobook corpus and the data from the dialogue state tracking challenges (DSTC) with the biasing lists extracted from the dialogue-system ontology. Consistent word error rate (WER) reductions were achieved with TCPGen, which were particularly significant on the biasing words with around 40\% relative reductions in the recognition error rates. MBWE and BLMD further improved the effectiveness of TCPGen and achieved more significant WER reductions on the biasing words. TCPGen also achieved zero-shot learning of words not in the audio training set with large WER reductions on the out-of-vocabulary words in the biasing list.
Linguistic-Acoustic Similarity Based Accent Shift for Accent Recognition
Apr 07, 2022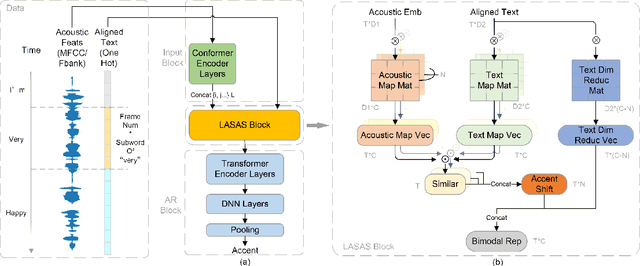
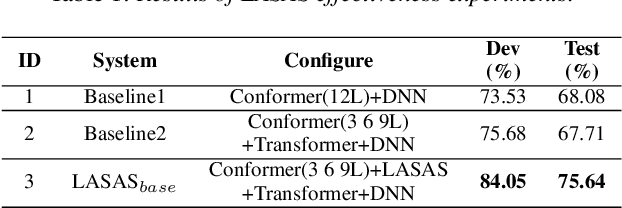
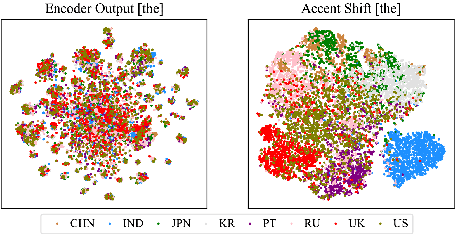
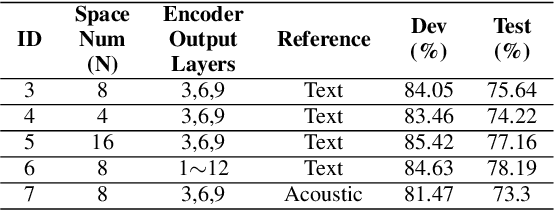
General accent recognition (AR) models tend to directly extract low-level information from spectrums, which always significantly overfit on speakers or channels. Considering accent can be regarded as a series of shifts relative to native pronunciation, distinguishing accents will be an easier task with accent shift as input. But due to the lack of native utterance as an anchor, estimating the accent shift is difficult. In this paper, we propose linguistic-acoustic similarity based accent shift (LASAS) for AR tasks. For an accent speech utterance, after mapping the corresponding text vector to multiple accent-associated spaces as anchors, its accent shift could be estimated by the similarities between the acoustic embedding and those anchors. Then, we concatenate the accent shift with a dimension-reduced text vector to obtain a linguistic-acoustic bimodal representation. Compared with pure acoustic embedding, the bimodal representation is richer and more clear by taking full advantage of both linguistic and acoustic information, which can effectively improve AR performance. Experiments on Accented English Speech Recognition Challenge (AESRC) dataset show that our method achieves 77.42% accuracy on Test set, obtaining a 6.94% relative improvement over a competitive system in the challenge.
Three-Module Modeling For End-to-End Spoken Language Understanding Using Pre-trained DNN-HMM-Based Acoustic-Phonetic Model
Apr 07, 2022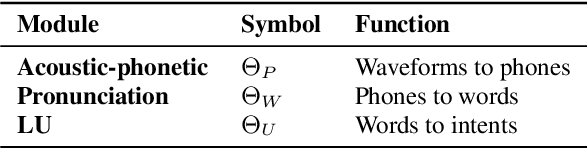
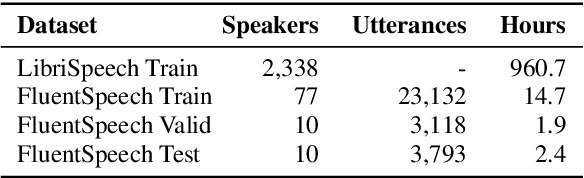
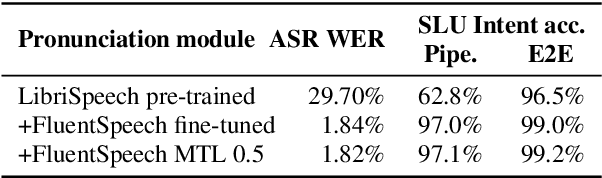

In spoken language understanding (SLU), what the user says is converted to his/her intent. Recent work on end-to-end SLU has shown that accuracy can be improved via pre-training approaches. We revisit ideas presented by Lugosch et al. using speech pre-training and three-module modeling; however, to ease construction of the end-to-end SLU model, we use as our phoneme module an open-source acoustic-phonetic model from a DNN-HMM hybrid automatic speech recognition (ASR) system instead of training one from scratch. Hence we fine-tune on speech only for the word module, and we apply multi-target learning (MTL) on the word and intent modules to jointly optimize SLU performance. MTL yields a relative reduction of 40% in intent-classification error rates (from 1.0% to 0.6%). Note that our three-module model is a streaming method. The final outcome of the proposed three-module modeling approach yields an intent accuracy of 99.4% on FluentSpeech, an intent error rate reduction of 50% compared to that of Lugosch et al. Although we focus on real-time streaming methods, we also list non-streaming methods for comparison.
Spoken SQuAD: A Study of Mitigating the Impact of Speech Recognition Errors on Listening Comprehension
Apr 01, 2018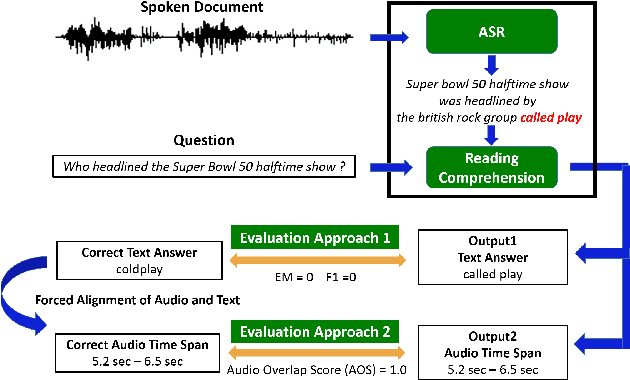
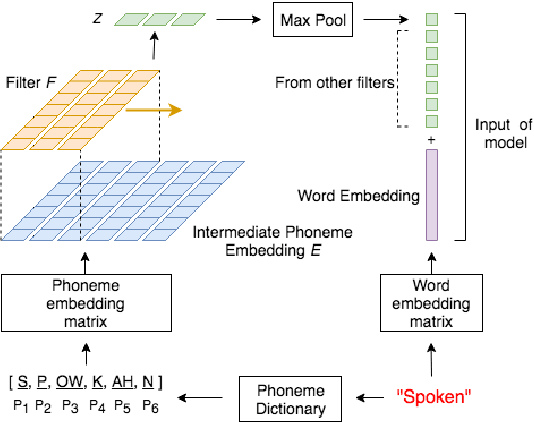
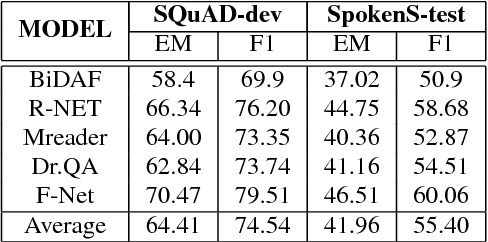

Reading comprehension has been widely studied. One of the most representative reading comprehension tasks is Stanford Question Answering Dataset (SQuAD), on which machine is already comparable with human. On the other hand, accessing large collections of multimedia or spoken content is much more difficult and time-consuming than plain text content for humans. It's therefore highly attractive to develop machines which can automatically understand spoken content. In this paper, we propose a new listening comprehension task - Spoken SQuAD. On the new task, we found that speech recognition errors have catastrophic impact on machine comprehension, and several approaches are proposed to mitigate the impact.
Algorithms for Speech Recognition and Language Processing
Sep 17, 1996Speech processing requires very efficient methods and algorithms. Finite-state transducers have been shown recently both to constitute a very useful abstract model and to lead to highly efficient time and space algorithms in this field. We present these methods and algorithms and illustrate them in the case of speech recognition. In addition to classical techniques, we describe many new algorithms such as minimization, global and local on-the-fly determinization of weighted automata, and efficient composition of transducers. These methods are currently used in large vocabulary speech recognition systems. We then show how the same formalism and algorithms can be used in text-to-speech applications and related areas of language processing such as morphology, syntax, and local grammars, in a very efficient way. The tutorial is self-contained and requires no specific computational or linguistic knowledge other than classical results.
Star Temporal Classification: Sequence Classification with Partially Labeled Data
Jan 28, 2022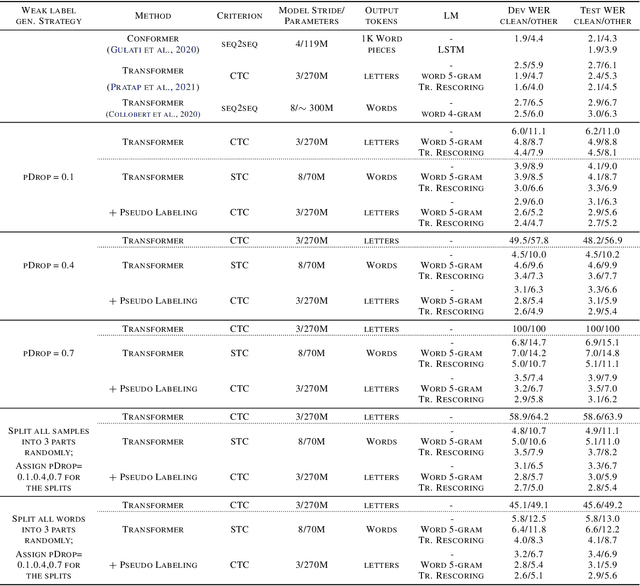
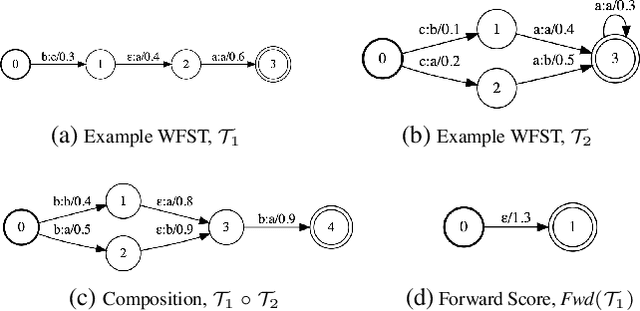
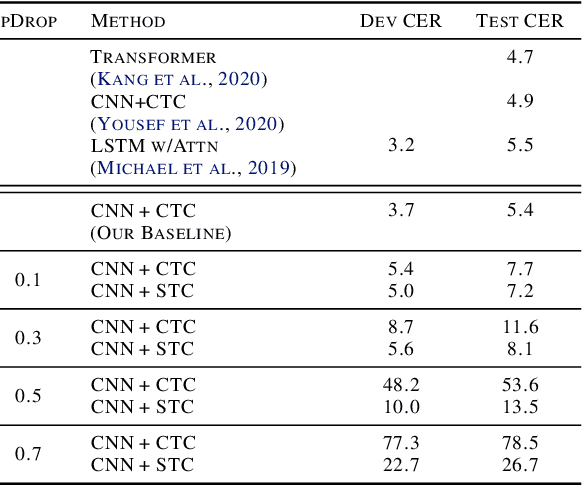
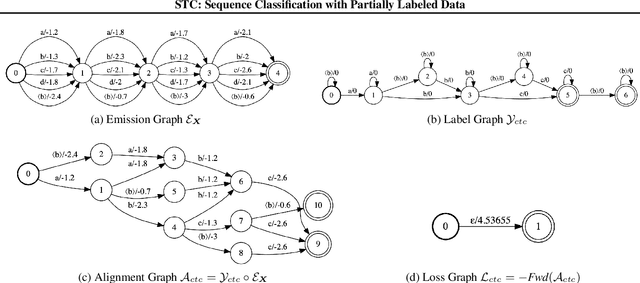
We develop an algorithm which can learn from partially labeled and unsegmented sequential data. Most sequential loss functions, such as Connectionist Temporal Classification (CTC), break down when many labels are missing. We address this problem with Star Temporal Classification (STC) which uses a special star token to allow alignments which include all possible tokens whenever a token could be missing. We express STC as the composition of weighted finite-state transducers (WFSTs) and use GTN (a framework for automatic differentiation with WFSTs) to compute gradients. We perform extensive experiments on automatic speech recognition. These experiments show that STC can recover most of the performance of supervised baseline when up to 70% of the labels are missing. We also perform experiments in handwriting recognition to show that our method easily applies to other sequence classification tasks.
Improving the Robustness of DistilHuBERT to Unseen Noisy Conditions via Data Augmentation, Curriculum Learning, and Multi-Task Enhancement
Nov 12, 2022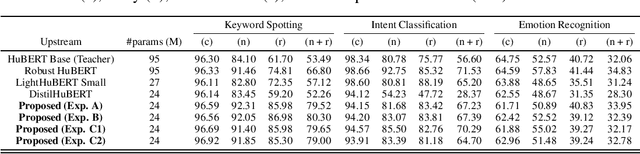
Self-supervised speech representation learning aims to extract meaningful factors from the speech signal that can later be used across different downstream tasks, such as speech and/or emotion recognition. Existing models, such as HuBERT, however, can be fairly large thus may not be suitable for edge speech applications. Moreover, realistic applications typically involve speech corrupted by noise and room reverberation, hence models need to provide representations that are robust to such environmental factors. In this study, we build on the so-called DistilHuBERT model, which distils HuBERT to a fraction of its original size, with three modifications, namely: (i) augment the training data with noise and reverberation, while the student model needs to distill the clean representations from the teacher model; (ii) introduce a curriculum learning approach where increasing levels of noise are introduced as the model trains, thus helping with convergence and with the creation of more robust representations; and (iii) introduce a multi-task learning approach where the model also reconstructs the clean waveform jointly with the distillation task, thus also acting as an enhancement step to ensure additional environment robustness to the representation. Experiments on three SUPERB tasks show the advantages of the proposed method not only relative to the original DistilHuBERT, but also to the original HuBERT, thus showing the advantages of the proposed method for ``in the wild'' edge speech applications.
A Fast-Converged Acoustic Modeling for Korean Speech Recognition: A Preliminary Study on Time Delay Neural Network
Jul 11, 2018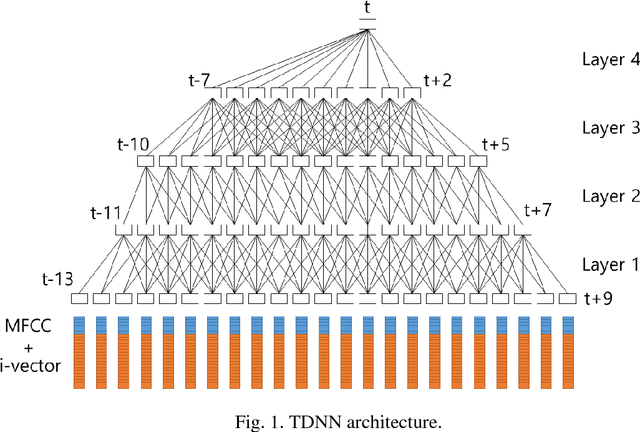

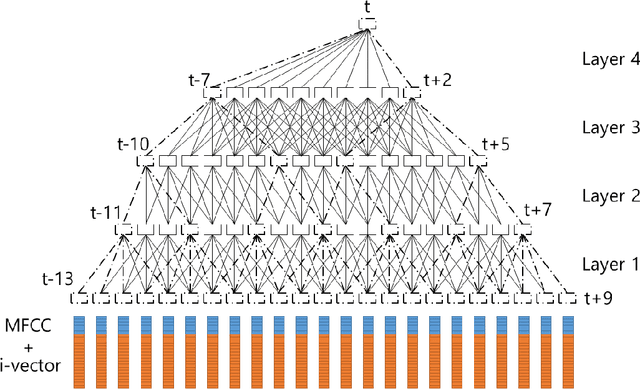
In this paper, a time delay neural network (TDNN) based acoustic model is proposed to implement a fast-converged acoustic modeling for Korean speech recognition. The TDNN has an advantage in fast-convergence where the amount of training data is limited, due to subsampling which excludes duplicated weights. The TDNN showed an absolute improvement of 2.12% in terms of character error rate compared to feed forward neural network (FFNN) based modelling for Korean speech corpora. The proposed model converged 1.67 times faster than a FFNN-based model did.
Can We Read Speech Beyond the Lips? Rethinking RoI Selection for Deep Visual Speech Recognition
Mar 09, 2020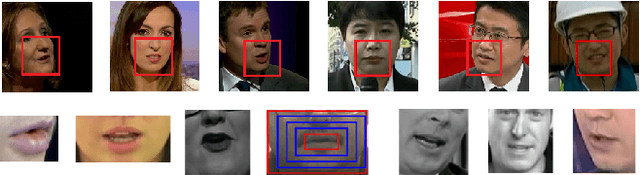

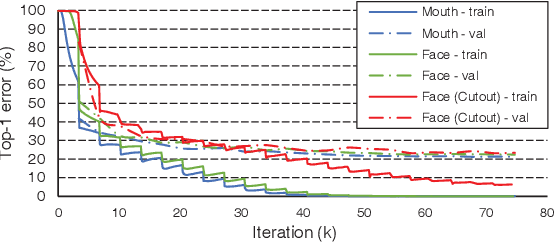
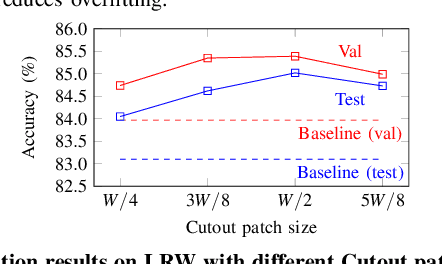
Recent advances in deep learning have heightened interest among researchers in the field of visual speech recognition (VSR). Currently, most existing methods equate VSR with automatic lip reading, which attempts to recognise speech by analysing lip motion. However, human experience and psychological studies suggest that we do not always fix our gaze at each other's lips during a face-to-face conversation, but rather scan the whole face repetitively. This inspires us to revisit a fundamental yet somehow overlooked problem: can VSR models benefit from reading extraoral facial regions, i.e. beyond the lips? In this paper, we perform a comprehensive study to evaluate the effects of different facial regions with state-of-the-art VSR models, including the mouth, the whole face, the upper face, and even the cheeks. Experiments are conducted on both word-level and sentence-level benchmarks with different characteristics. We find that despite the complex variations of the data, incorporating information from extraoral facial regions, even the upper face, consistently benefits VSR performance. Furthermore, we introduce a simple yet effective method based on Cutout to learn more discriminative features for face-based VSR, hoping to maximise the utility of information encoded in different facial regions. Our experiments show obvious improvements over existing state-of-the-art methods that use only the lip region as inputs, a result we believe would probably provide the VSR community with some new and exciting insights.