 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech Recognition
Feb 05, 2014
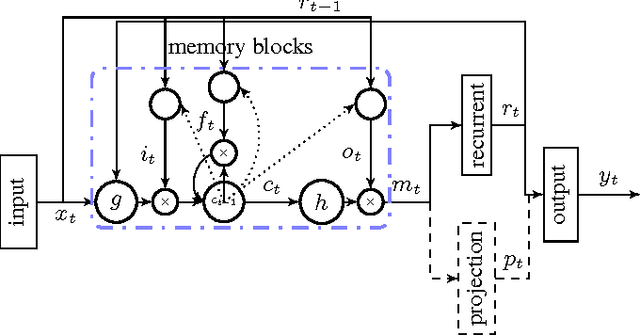
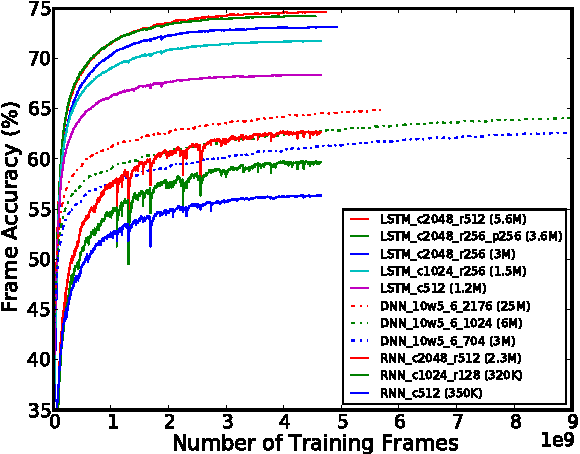
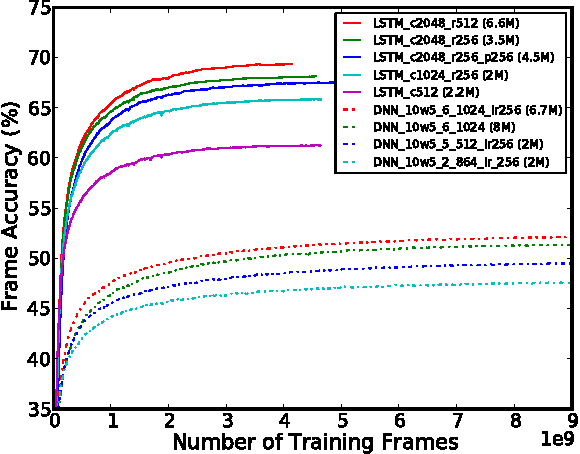
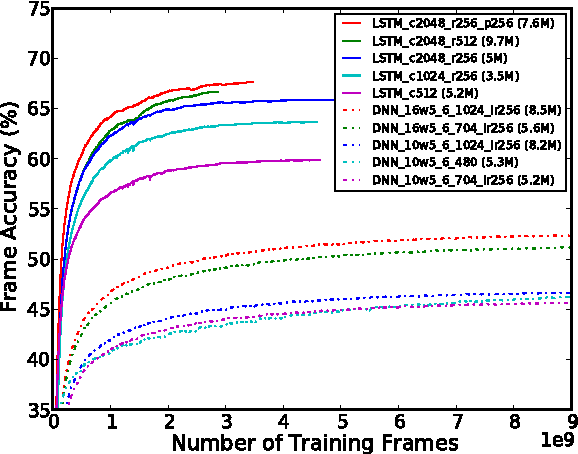
Long Short-Term Memory (LSTM) is a recurrent neural network (RNN) architecture that has been designed to address the vanishing and exploding gradient problems of conventional RNNs. Unlike feedforward neural networks, RNNs have cyclic connections making them powerful for modeling sequences. They have been successfully used for sequence labeling and sequence prediction tasks, such as handwriting recognition, language modeling, phonetic labeling of acoustic frames. However, in contrast to the deep neural networks, the use of RNNs in speech recognition has been limited to phone recognition in small scale tasks. In this paper, we present novel LSTM based RNN architectures which make more effective use of model parameters to train acoustic models for large vocabulary speech recognition. We train and compare LSTM, RNN and DNN models at various numbers of parameters and configurations. We show that LSTM models converge quickly and give state of the art speech recognition performance for relatively small sized models.
CMGAN: Conformer-based Metric GAN for Speech Enhancement
Mar 28, 2022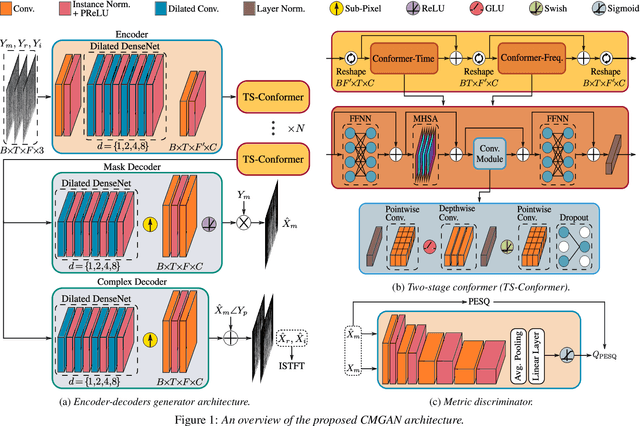
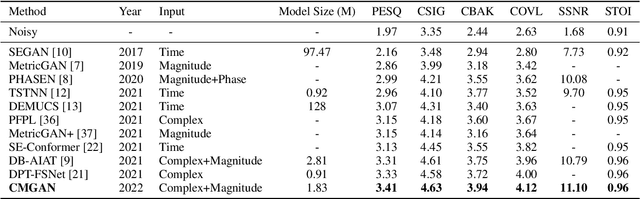
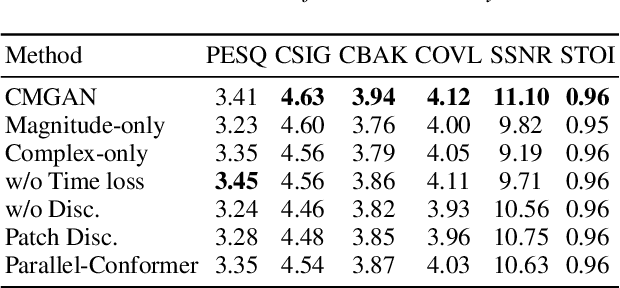
Recently, convolution-augmented transformer (Conformer) has achieved promising performance in automatic speech recognition (ASR) and time-domain speech enhancement (SE), as it can capture both local and global dependencies in the speech signal. In this paper, we propose a conformer-based metric generative adversarial network (CMGAN) for SE in the time-frequency (TF) domain. In the generator, we utilize two-stage conformer blocks to aggregate all magnitude and complex spectrogram information by modeling both time and frequency dependencies. The estimation of magnitude and complex spectrogram is decoupled in the decoder stage and then jointly incorporated to reconstruct the enhanced speech. In addition, a metric discriminator is employed to further improve the quality of the enhanced estimated speech by optimizing the generator with respect to a corresponding evaluation score. Quantitative analysis on Voice Bank+DEMAND dataset indicates the capability of CMGAN in outperforming various previous models with a margin, i.e., PESQ of 3.41 and SSNR of 11.10 dB.
A Unified Cascaded Encoder ASR Model for Dynamic Model Sizes
Apr 20, 2022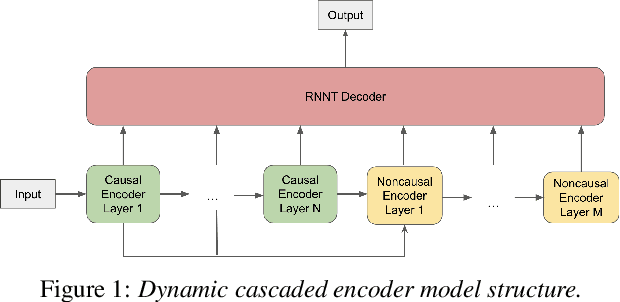
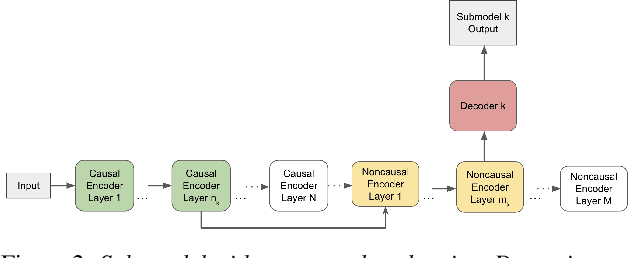
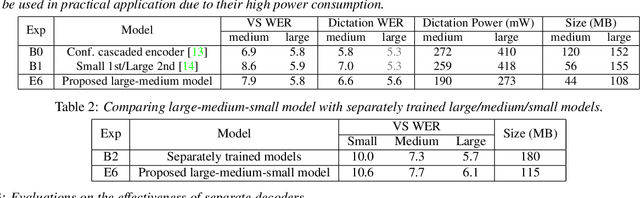
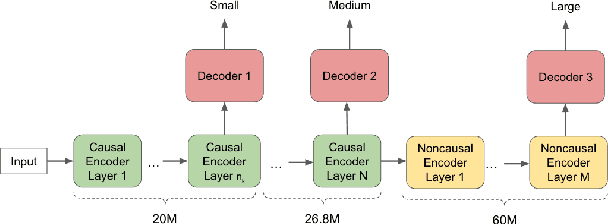
In this paper, we propose a dynamic cascaded encoder Automatic Speech Recognition (ASR) model, which unifies models for different deployment scenarios. Moreover, the model can significantly reduce model size and power consumption without loss of quality. Namely, with the dynamic cascaded encoder model, we explore three techniques to maximally boost the performance of each model size: 1) Use separate decoders for each sub-model while sharing the encoders; 2) Use funnel-pooling to improve the encoder efficiency; 3) Balance the size of causal and non-causal encoders to improve quality and fit deployment constraints. Overall, the proposed large-medium model has 30% smaller size and reduces power consumption by 33%, compared to the baseline cascaded encoder model. The triple-size model that unifies the large, medium, and small models achieves 37% total size reduction with minimal quality loss, while substantially reducing the engineering efforts of having separate models.
Deep scattering network for speech emotion recognition
May 11, 2021
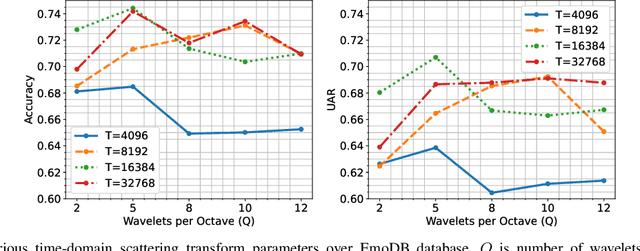

This paper introduces scattering transform for speech emotion recognition (SER). Scattering transform generates feature representations which remain stable to deformations and shifting in time and frequency without much loss of information. In speech, the emotion cues are spread across time and localised in frequency. The time and frequency invariance characteristic of scattering coefficients provides a representation robust against emotion irrelevant variations e.g., different speakers, language, gender etc. while preserving the variations caused by emotion cues. Hence, such a representation captures the emotion information more efficiently from speech. We perform experiments to compare scattering coefficients with standard mel-frequency cepstral coefficients (MFCCs) over different databases. It is observed that frequency scattering performs better than time-domain scattering and MFCCs. We also investigate layer-wise scattering coefficients to analyse the importance of time shift and deformation stable scalogram and modulation spectrum coefficients for SER. We observe that layer-wise coefficients taken independently also perform better than MFCCs.
Multistage linguistic conditioning of convolutional layers for speech emotion recognition
Oct 13, 2021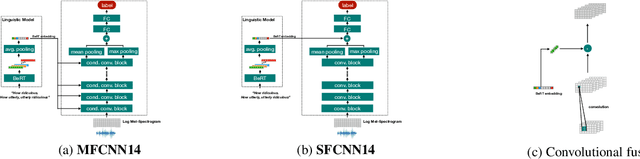
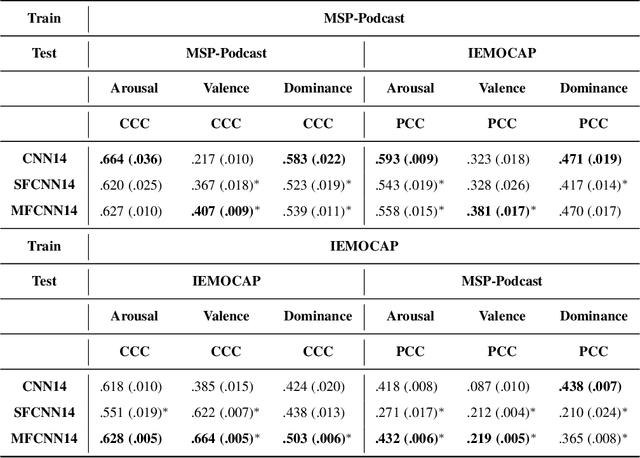
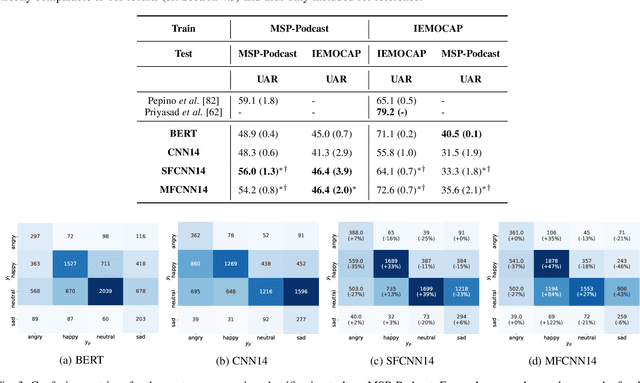
In this contribution, we investigate the effectiveness of deep fusion of text and audio features for categorical and dimensional speech emotion recognition (SER). We propose a novel, multistage fusion method where the two information streams are integrated in several layers of a deep neural network (DNN), and contrast it with a single-stage one where the streams are merged in a single point. Both methods depend on extracting summary linguistic embeddings from a pre-trained BERT model, and conditioning one or more intermediate representations of a convolutional model operating on log-Mel spectrograms. Experiments on the widely used IEMOCAP and MSP-Podcast databases demonstrate that the two fusion methods clearly outperform a shallow (late) fusion baseline and their unimodal constituents, both in terms of quantitative performance and qualitative behaviour. Our accompanying analysis further reveals a hitherto unexplored role of the underlying dialogue acts on unimodal and bimodal SER, with different models showing a biased behaviour across different acts. Overall, our multistage fusion shows better quantitative performance, surpassing all alternatives on most of our evaluations. This illustrates the potential of multistage fusion in better assimilating text and audio information.
CUSIDE: Chunking, Simulating Future Context and Decoding for Streaming ASR
Mar 31, 2022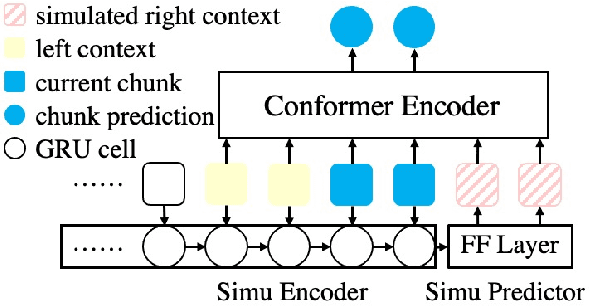
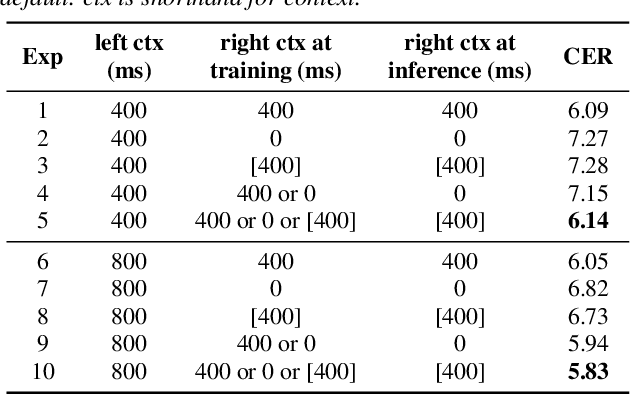

History and future contextual information are known to be important for accurate acoustic modeling. However, acquiring future context brings latency for streaming ASR. In this paper, we propose a new framework - Chunking, Simulating Future Context and Decoding (CUSIDE) for streaming speech recognition. A new simulation module is introduced to recursively simulate the future contextual frames, without waiting for future context. The simulation module is jointly trained with the ASR model using a self-supervised loss; the ASR model is optimized with the usual ASR loss, e.g., CTC-CRF as used in our experiments. Experiments show that, compared to using real future frames as right context, using simulated future context can drastically reduce latency while maintaining recognition accuracy. With CUSIDE, we obtain new state-of-the-art streaming ASR results on the AISHELL-1 dataset.
Assessing the Tolerance of Neural Machine Translation Systems Against Speech Recognition Errors
Apr 24, 2019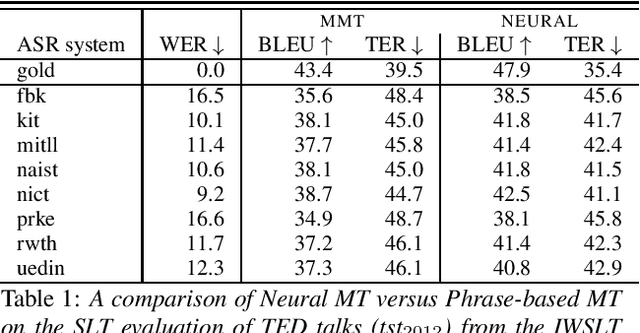
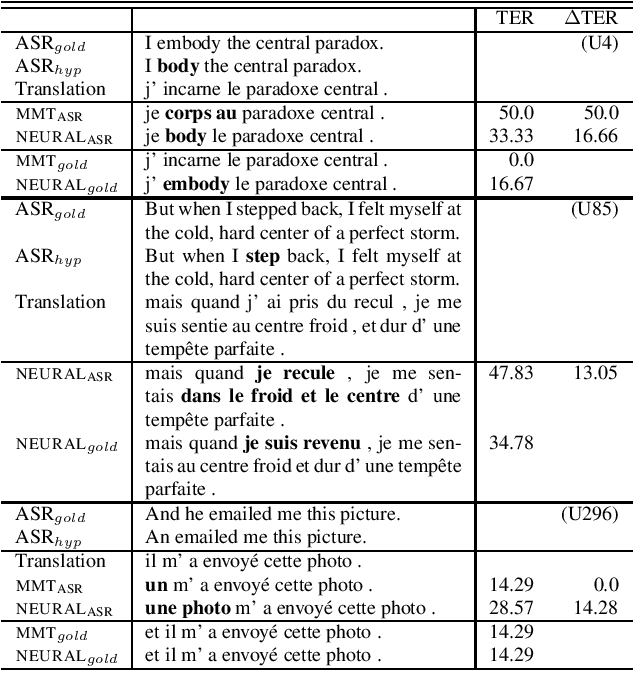
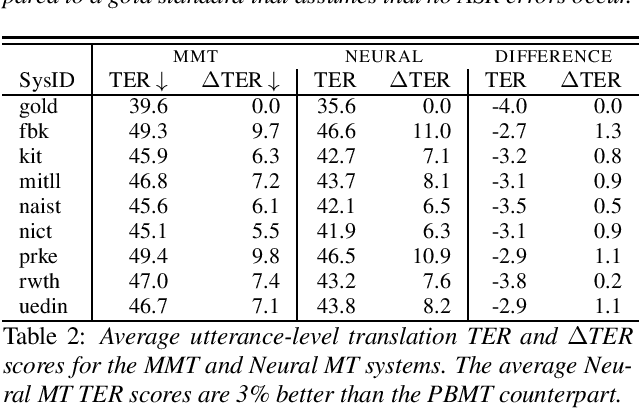
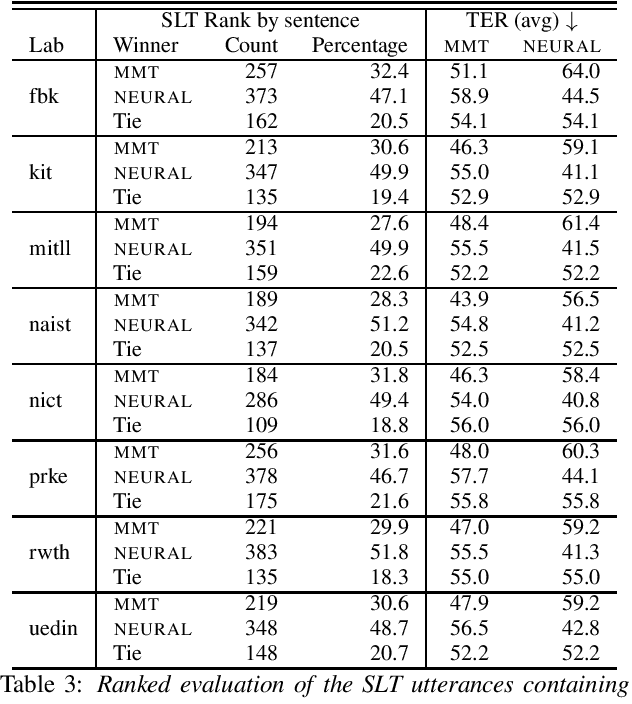
Machine translation systems are conventionally trained on textual resources that do not model phenomena that occur in spoken language. While the evaluation of neural machine translation systems on textual inputs is actively researched in the literature , little has been discovered about the complexities of translating spoken language data with neural models. We introduce and motivate interesting problems one faces when considering the translation of automatic speech recognition (ASR) outputs on neural machine translation (NMT) systems. We test the robustness of sentence encoding approaches for NMT encoder-decoder modeling, focusing on word-based over byte-pair encoding. We compare the translation of utterances containing ASR errors in state-of-the-art NMT encoder-decoder systems against a strong phrase-based machine translation baseline in order to better understand which phenomena present in ASR outputs are better represented under the NMT framework than approaches that represent translation as a linear model.
Stream attention-based multi-array end-to-end speech recognition
Nov 12, 2018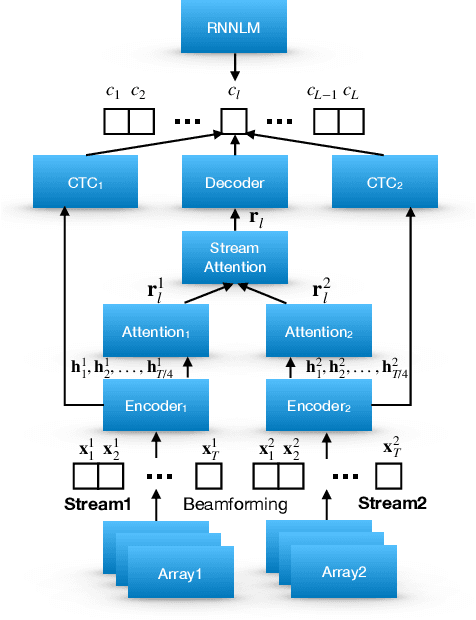
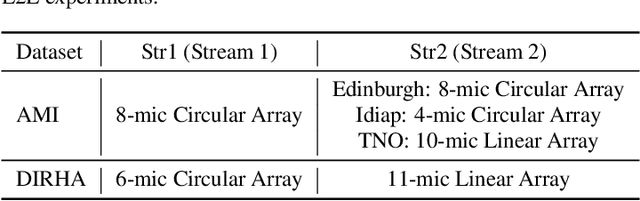
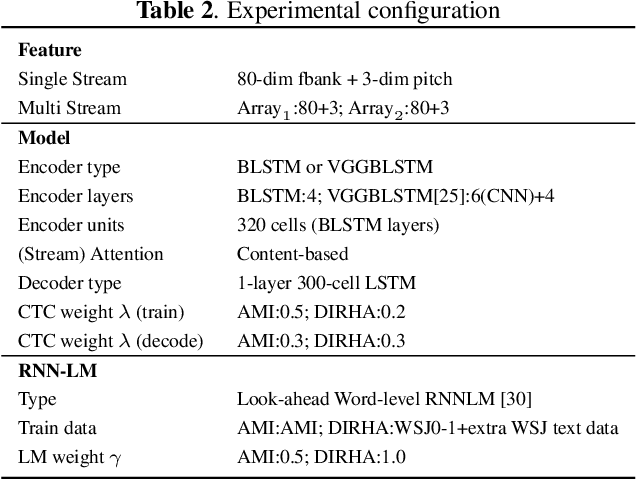
Automatic Speech Recognition (ASR) using multiple microphone arrays has achieved great success in the far-field robustness. Taking advantage of all the information that each array shares and contributes is crucial in this task. Motivated by the advances of joint Connectionist Temporal Classification (CTC)/attention mechanism in the End-to-End (E2E) ASR, a stream attention-based multi-array framework is proposed in this work. Microphone arrays, acting as information streams, are activated by separate encoders and decoded under the instruction of both CTC and attention networks. In terms of attention, a hierarchical structure is adopted. On top of the regular attention networks, stream attention is introduced to steer the decoder toward the most informative encoders. Experiments have been conducted on AMI and DIRHA multi-array corpora using the encoder-decoder architecture. Compared with the best single-array results, the proposed framework has achieved relative Word Error Rates (WERs) reduction of 3.7% and 9.7% in the two datasets, respectively, which is better than conventional strategies as well.
Mitigating the Impact of Speech Recognition Errors on Spoken Question Answering by Adversarial Domain Adaptation
Apr 16, 2019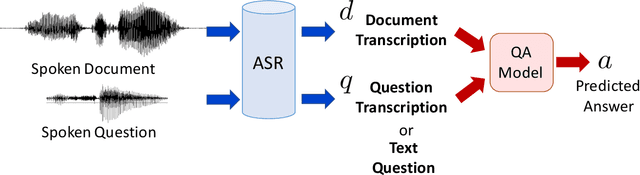
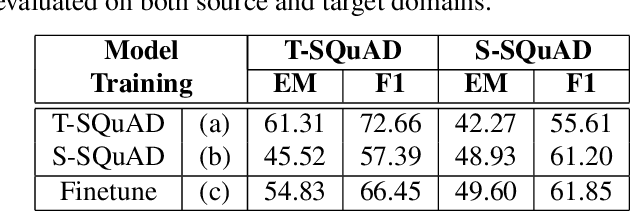
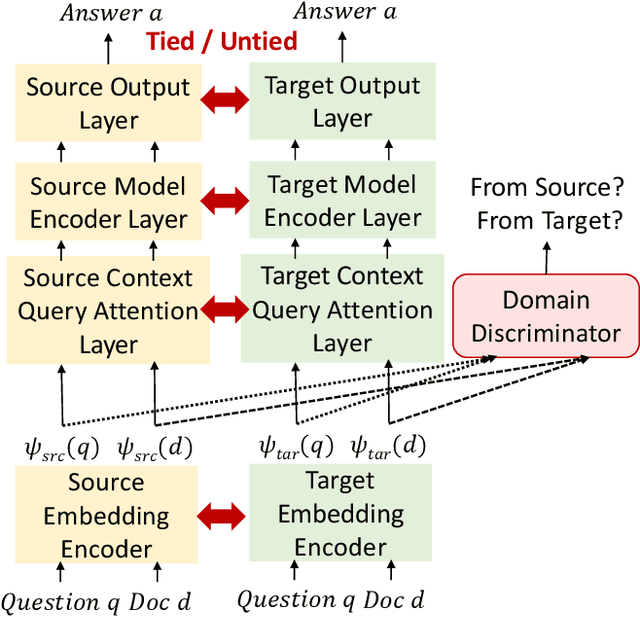
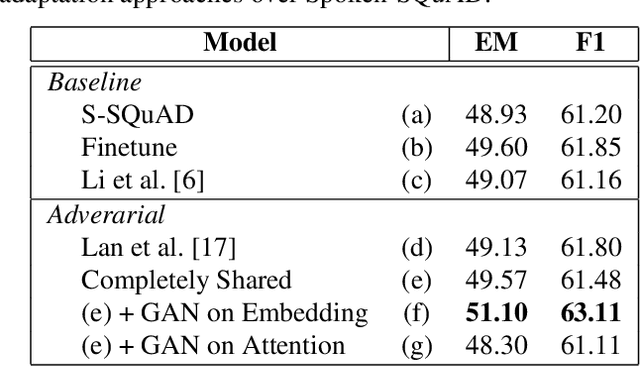
Spoken question answering (SQA) is challenging due to complex reasoning on top of the spoken documents. The recent studies have also shown the catastrophic impact of automatic speech recognition (ASR) errors on SQA. Therefore, this work proposes to mitigate the ASR errors by aligning the mismatch between ASR hypotheses and their corresponding reference transcriptions. An adversarial model is applied to this domain adaptation task, which forces the model to learn domain-invariant features the QA model can effectively utilize in order to improve the SQA results. The experiments successfully demonstrate the effectiveness of our proposed model, and the results are better than the previous best model by 2% EM score.
Scaling ASR Improves Zero and Few Shot Learning
Nov 13, 2021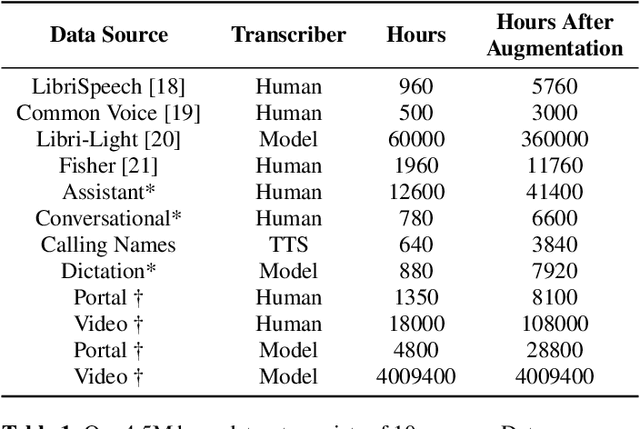
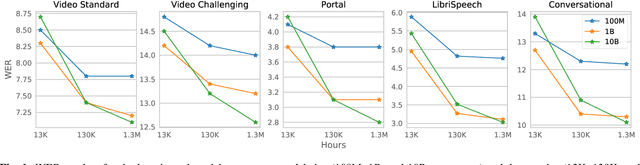
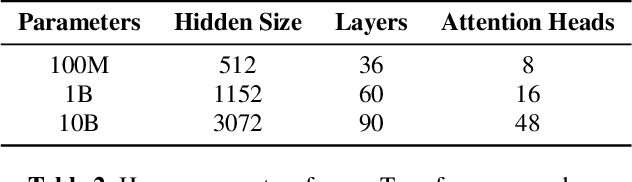
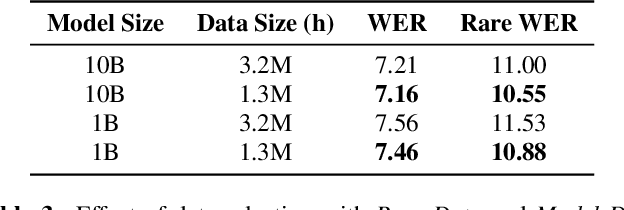
With 4.5 million hours of English speech from 10 different sources across 120 countries and models of up to 10 billion parameters, we explore the frontiers of scale for automatic speech recognition. We propose data selection techniques to efficiently scale training data to find the most valuable samples in massive datasets. To efficiently scale model sizes, we leverage various optimizations such as sparse transducer loss and model sharding. By training 1-10B parameter universal English ASR models, we push the limits of speech recognition performance across many domains. Furthermore, our models learn powerful speech representations with zero and few-shot capabilities on novel domains and styles of speech, exceeding previous results across multiple in-house and public benchmarks. For speakers with disorders due to brain damage, our best zero-shot and few-shot models achieve 22% and 60% relative improvement on the AphasiaBank test set, respectively, while realizing the best performance on public social media videos. Furthermore, the same universal model reaches equivalent performance with 500x less in-domain data on the SPGISpeech financial-domain dataset.