 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultistage linguistic conditioning of convolutional layers for speech emotion recognition
Paper and Code
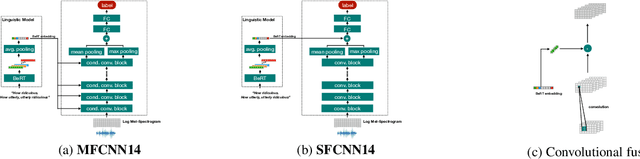
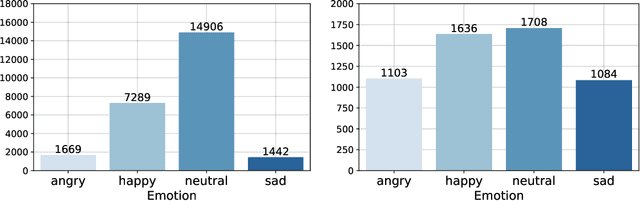
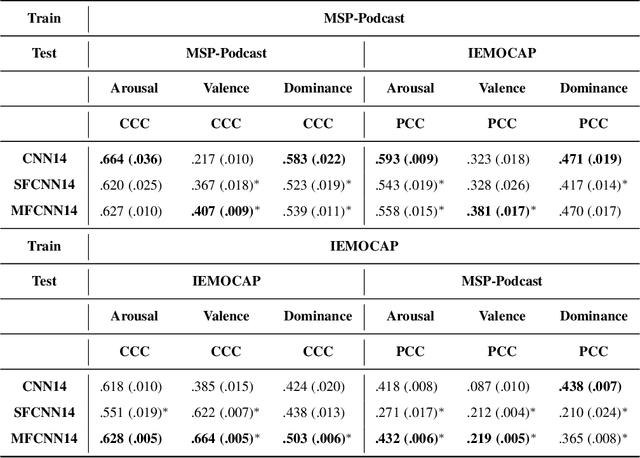
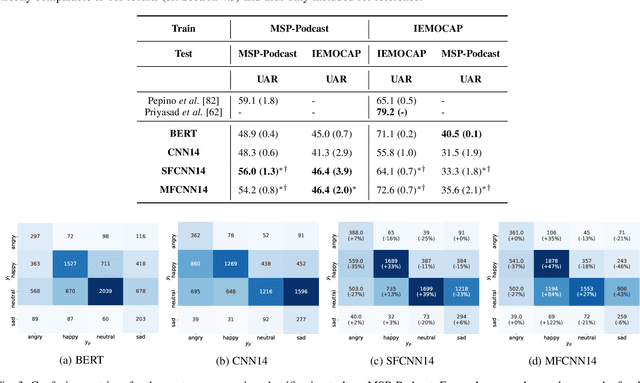
In this contribution, we investigate the effectiveness of deep fusion of text and audio features for categorical and dimensional speech emotion recognition (SER). We propose a novel, multistage fusion method where the two information streams are integrated in several layers of a deep neural network (DNN), and contrast it with a single-stage one where the streams are merged in a single point. Both methods depend on extracting summary linguistic embeddings from a pre-trained BERT model, and conditioning one or more intermediate representations of a convolutional model operating on log-Mel spectrograms. Experiments on the widely used IEMOCAP and MSP-Podcast databases demonstrate that the two fusion methods clearly outperform a shallow (late) fusion baseline and their unimodal constituents, both in terms of quantitative performance and qualitative behaviour. Our accompanying analysis further reveals a hitherto unexplored role of the underlying dialogue acts on unimodal and bimodal SER, with different models showing a biased behaviour across different acts. Overall, our multistage fusion shows better quantitative performance, surpassing all alternatives on most of our evaluations. This illustrates the potential of multistage fusion in better assimilating text and audio information.