 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Non-Parallel Voice Conversion for ASR Augmentation
Sep 15, 2022
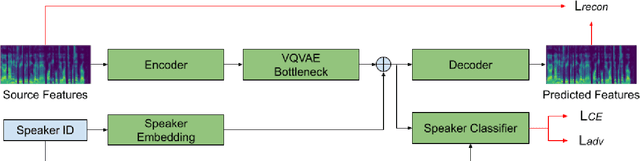
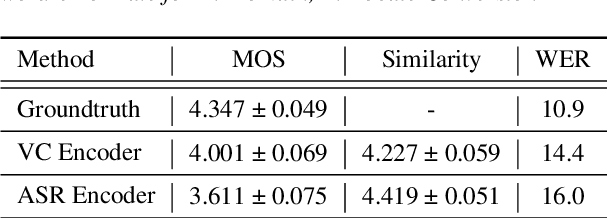
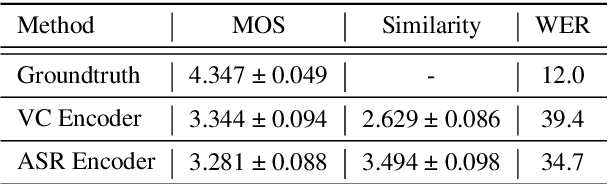
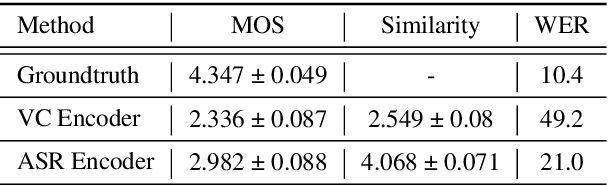
Automatic speech recognition (ASR) needs to be robust to speaker differences. Voice Conversion (VC) modifies speaker characteristics of input speech. This is an attractive feature for ASR data augmentation. In this paper, we demonstrate that voice conversion can be used as a data augmentation technique to improve ASR performance, even on LibriSpeech, which contains 2,456 speakers. For ASR augmentation, it is necessary that the VC model be robust to a wide range of input speech. This motivates the use of a non-autoregressive, non-parallel VC model, and the use of a pretrained ASR encoder within the VC model. This work suggests that despite including many speakers, speaker diversity may remain a limitation to ASR quality. Finally, interrogation of our VC performance has provided useful metrics for objective evaluation of VC quality.
The THUEE System Description for the IARPA OpenASR21 Challenge
Jun 29, 2022



This paper describes the THUEE team's speech recognition system for the IARPA Open Automatic Speech Recognition Challenge (OpenASR21), with further experiment explorations. We achieve outstanding results under both the Constrained and Constrained-plus training conditions. For the Constrained training condition, we construct our basic ASR system based on the standard hybrid architecture. To alleviate the Out-Of-Vocabulary (OOV) problem, we extend the pronunciation lexicon using Grapheme-to-Phoneme (G2P) techniques for both OOV and potential new words. Standard acoustic model structures such as CNN-TDNN-F and CNN-TDNN-F-A are adopted. In addition, multiple data augmentation techniques are applied. For the Constrained-plus training condition, we use the self-supervised learning framework wav2vec2.0. We experiment with various fine-tuning techniques with the Connectionist Temporal Classification (CTC) criterion on top of the publicly available pre-trained model XLSR-53. We find that the frontend feature extractor plays an important role when applying the wav2vec2.0 pre-trained model to the encoder-decoder based CTC/Attention ASR architecture. Extra improvements can be achieved by using the CTC model finetuned in the target language as the frontend feature extractor.
Acoustic-aware Non-autoregressive Spell Correction with Mask Sample Decoding
Oct 16, 2022
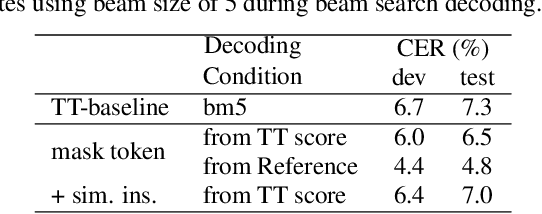

Masked language model (MLM) has been widely used for understanding tasks, e.g. BERT. Recently, MLM has also been used for generation tasks. The most popular one in speech is using Mask-CTC for non-autoregressive speech recognition. In this paper, we take one step further, and explore the possibility of using MLM as a non-autoregressive spell correction (SC) model for transformer-transducer (TT), denoted as MLM-SC. Our initial experiments show that MLM-SC provides no improvements on Librispeech data. The problem might be the choice of modeling units (word pieces) and the inaccuracy of the TT confidence scores for English data. To solve the problem, we propose a mask sample decoding (MS-decode) method where the masked tokens can have the choice of being masked or not to compensate for the inaccuracy. As a result, we reduce the WER of a streaming TT from 7.6% to 6.5% on the Librispeech test-other data and the CER from 7.3% to 6.1% on the Aishell test data, respectively.
Exploring Pre-training with Alignments for RNN Transducer based End-to-End Speech Recognition
May 01, 2020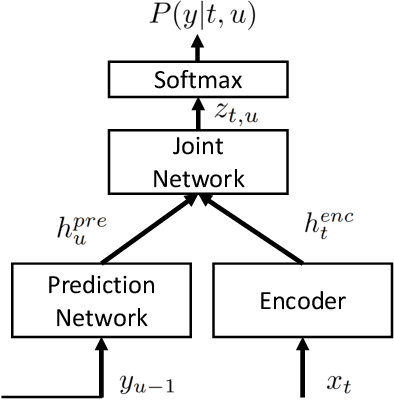

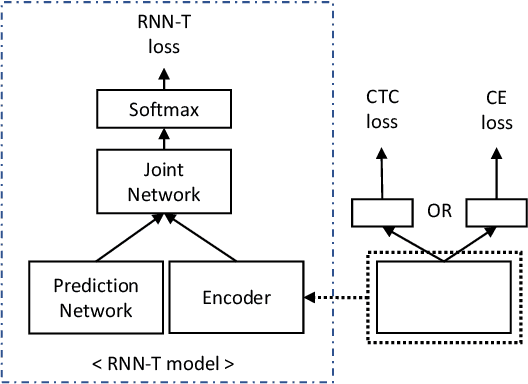
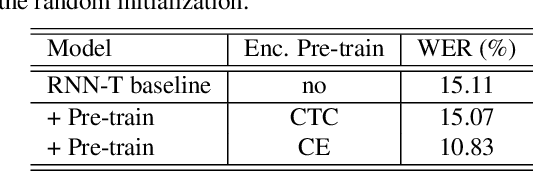
Recently, the recurrent neural network transducer (RNN-T) architecture has become an emerging trend in end-to-end automatic speech recognition research due to its advantages of being capable for online streaming speech recognition. However, RNN-T training is made difficult by the huge memory requirements, and complicated neural structure. A common solution to ease the RNN-T training is to employ connectionist temporal classification (CTC) model along with RNN language model (RNNLM) to initialize the RNN-T parameters. In this work, we conversely leverage external alignments to seed the RNN-T model. Two different pre-training solutions are explored, referred to as encoder pre-training, and whole-network pre-training respectively. Evaluated on Microsoft 65,000 hours anonymized production data with personally identifiable information removed, our proposed methods can obtain significant improvement. In particular, the encoder pre-training solution achieved a 10% and a 8% relative word error rate reduction when compared with random initialization and the widely used CTC+RNNLM initialization strategy, respectively. Our solutions also significantly reduce the RNN-T model latency from the baseline.
Speech Recognition: Keyword Spotting Through Image Recognition
Mar 10, 2018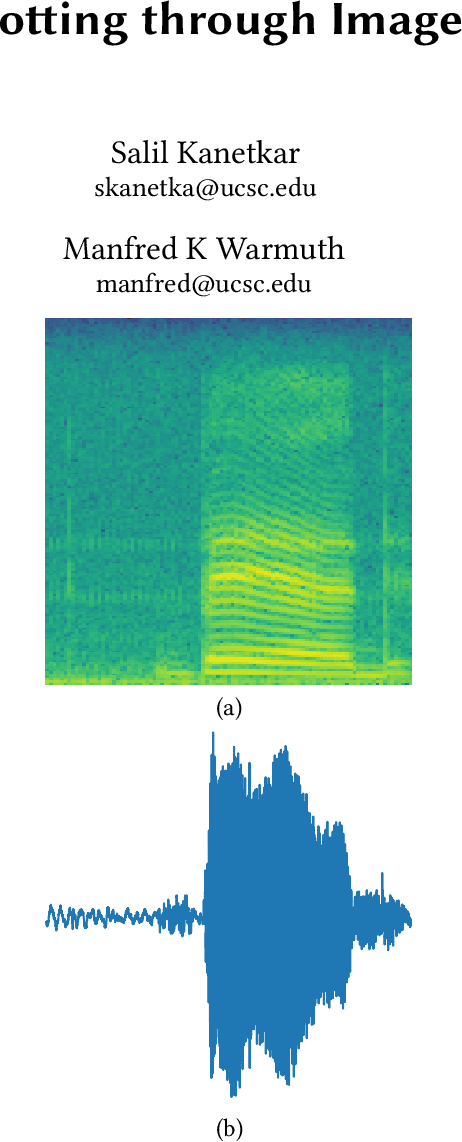
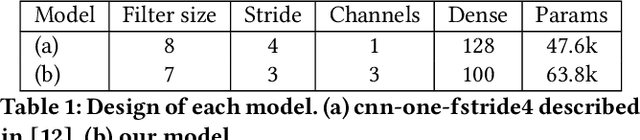
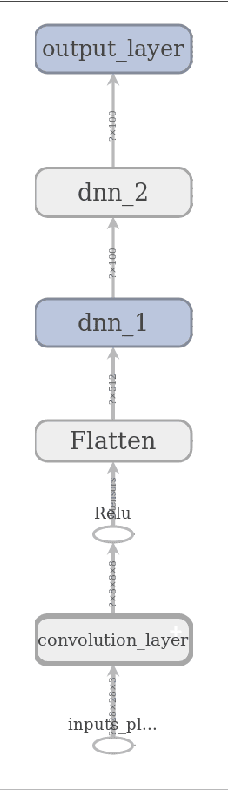
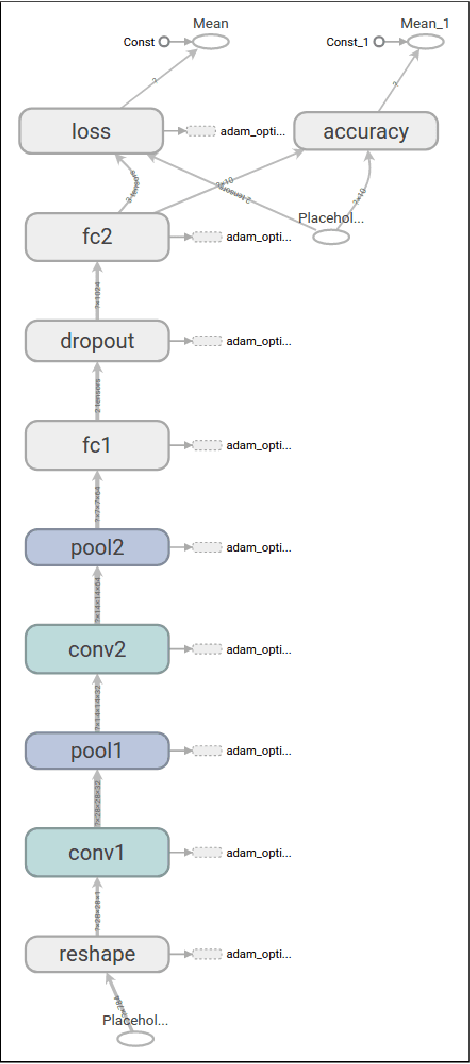
The problem of identifying voice commands has always been a challenge due to the presence of noise and variability in speed, pitch, etc. We will compare the efficacies of several neural network architectures for the speech recognition problem. In particular, we will build a model to determine whether a one second audio clip contains a particular word (out of a set of 10), an unknown word, or silence. The models to be implemented are a CNN recommended by the Tensorflow Speech Recognition tutorial, a low-latency CNN, and an adversarially trained CNN. The result is a demonstration of how to convert a problem in audio recognition to the better-studied domain of image classification, where the powerful techniques of convolutional neural networks are fully developed. Additionally, we demonstrate the applicability of the technique of Virtual Adversarial Training (VAT) to this problem domain, functioning as a powerful regularizer with promising potential future applications.
The Microsoft 2017 Conversational Speech Recognition System
Aug 24, 2017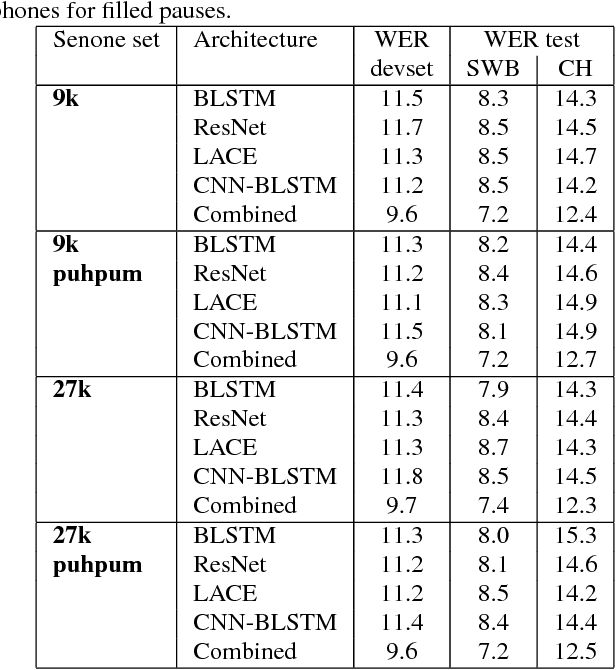
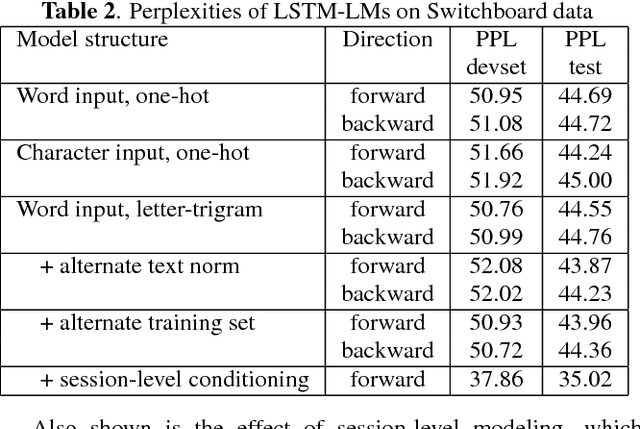
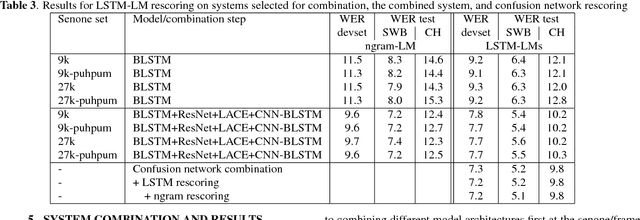
We describe the 2017 version of Microsoft's conversational speech recognition system, in which we update our 2016 system with recent developments in neural-network-based acoustic and language modeling to further advance the state of the art on the Switchboard speech recognition task. The system adds a CNN-BLSTM acoustic model to the set of model architectures we combined previously, and includes character-based and dialog session aware LSTM language models in rescoring. For system combination we adopt a two-stage approach, whereby subsets of acoustic models are first combined at the senone/frame level, followed by a word-level voting via confusion networks. We also added a confusion network rescoring step after system combination. The resulting system yields a 5.1\% word error rate on the 2000 Switchboard evaluation set.
Attention-Based End-to-End Speech Recognition on Voice Search
Feb 13, 2018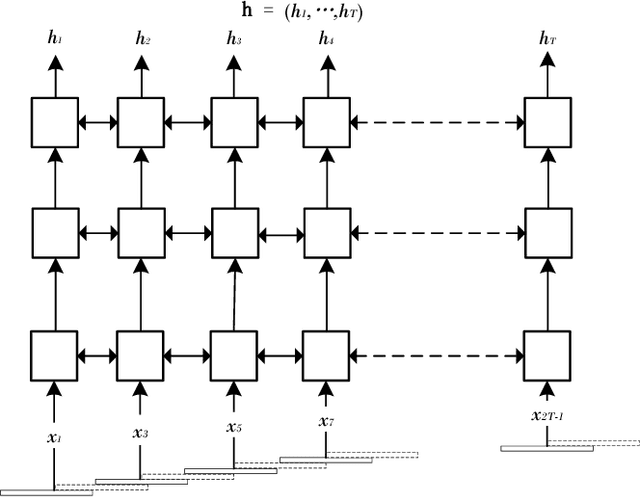
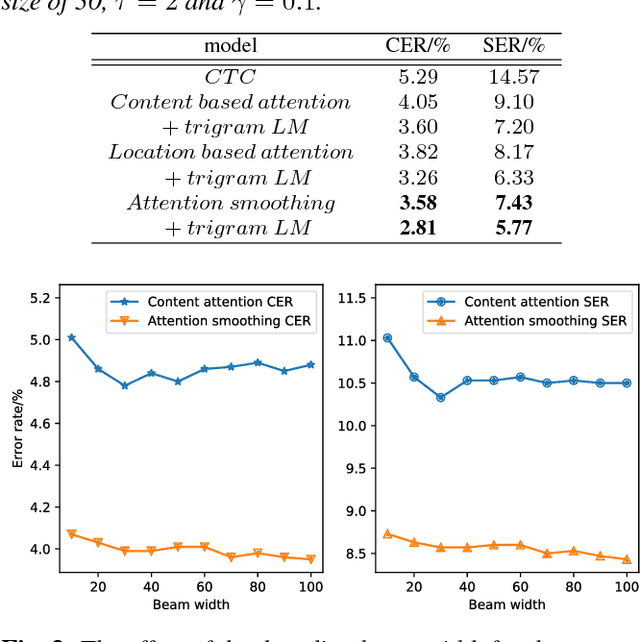
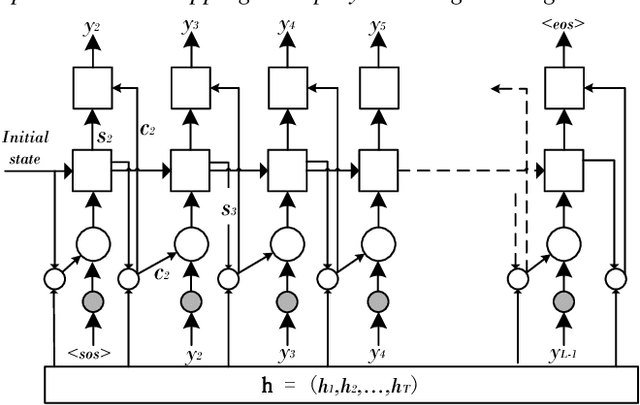
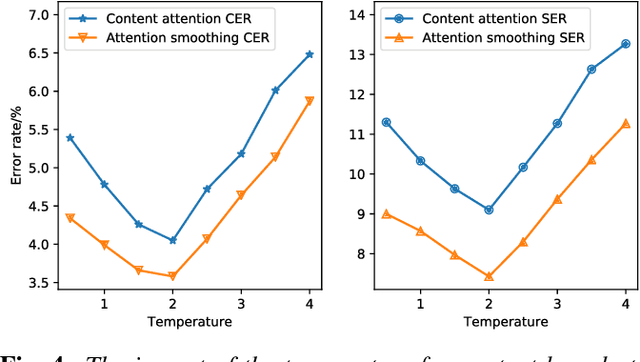
Recently, there has been a growing interest in end-to-end speech recognition that directly transcribes speech to text without any predefined alignments. In this paper, we explore the use of attention-based encoder-decoder model for Mandarin speech recognition on a voice search task. Previous attempts have shown that applying attention-based encoder-decoder to Mandarin speech recognition was quite difficult due to the logographic orthography of Mandarin, the large vocabulary and the conditional dependency of the attention model. In this paper, we use character embedding to deal with the large vocabulary. Several tricks are used for effective model training, including L2 regularization, Gaussian weight noise and frame skipping. We compare two attention mechanisms and use attention smoothing to cover long context in the attention model. Taken together, these tricks allow us to finally achieve a character error rate (CER) of 3.58% and a sentence error rate (SER) of 7.43% on the MiTV voice search dataset. While together with a trigram language model, CER and SER reach 2.81% and 5.77%, respectively.
Visual Speech Recognition
Sep 03, 2014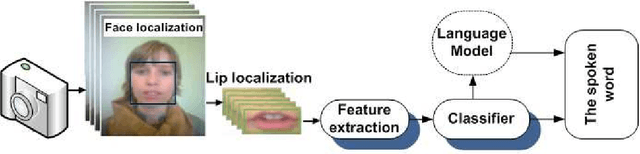
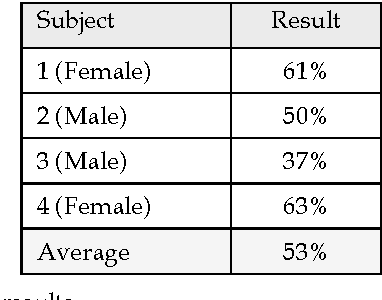
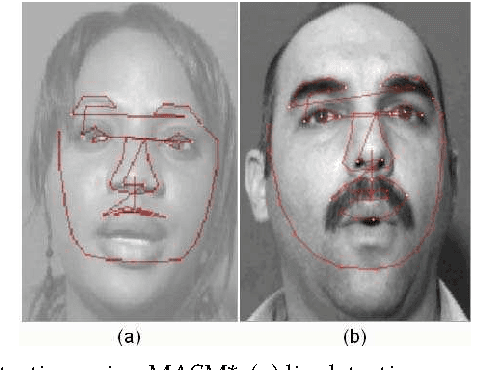
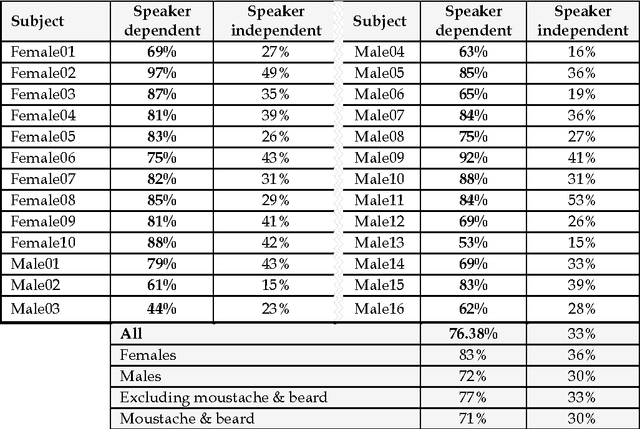
Lip reading is used to understand or interpret speech without hearing it, a technique especially mastered by people with hearing difficulties. The ability to lip read enables a person with a hearing impairment to communicate with others and to engage in social activities, which otherwise would be difficult. Recent advances in the fields of computer vision, pattern recognition, and signal processing has led to a growing interest in automating this challenging task of lip reading. Indeed, automating the human ability to lip read, a process referred to as visual speech recognition (VSR) (or sometimes speech reading), could open the door for other novel related applications. VSR has received a great deal of attention in the last decade for its potential use in applications such as human-computer interaction (HCI), audio-visual speech recognition (AVSR), speaker recognition, talking heads, sign language recognition and video surveillance. Its main aim is to recognise spoken word(s) by using only the visual signal that is produced during speech. Hence, VSR deals with the visual domain of speech and involves image processing, artificial intelligence, object detection, pattern recognition, statistical modelling, etc.
Automatic context window composition for distant speech recognition
May 26, 2018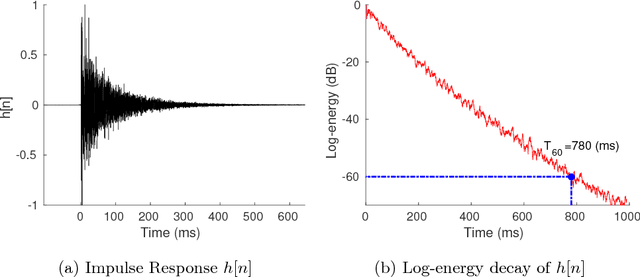
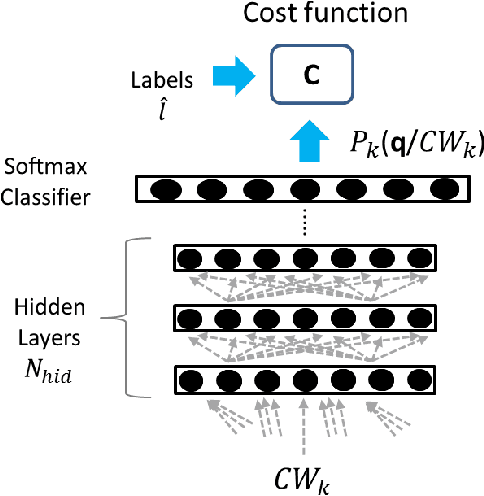
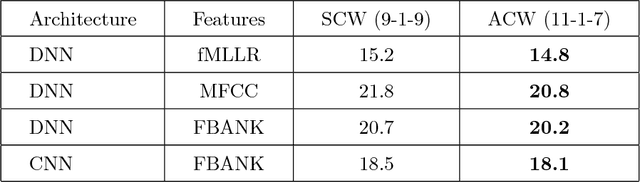
Distant speech recognition is being revolutionized by deep learning, that has contributed to significantly outperform previous HMM-GMM systems. A key aspect behind the rapid rise and success of DNNs is their ability to better manage large time contexts. With this regard, asymmetric context windows that embed more past than future frames have been recently used with feed-forward neural networks. This context configuration turns out to be useful not only to address low-latency speech recognition, but also to boost the recognition performance under reverberant conditions. This paper investigates on the mechanisms occurring inside DNNs, which lead to an effective application of asymmetric contexts.In particular, we propose a novel method for automatic context window composition based on a gradient analysis. The experiments, performed with different acoustic environments, features, DNN architectures, microphone settings, and recognition tasks show that our simple and efficient strategy leads to a less redundant frame configuration, which makes DNN training more effective in reverberant scenarios.
Speech Recognition and Multi-Speaker Diarization of Long Conversations
May 16, 2020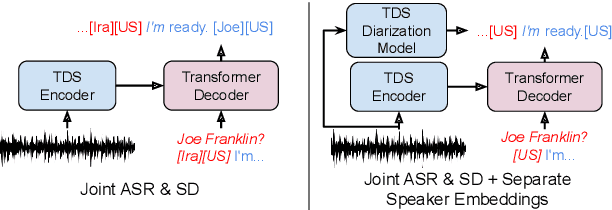
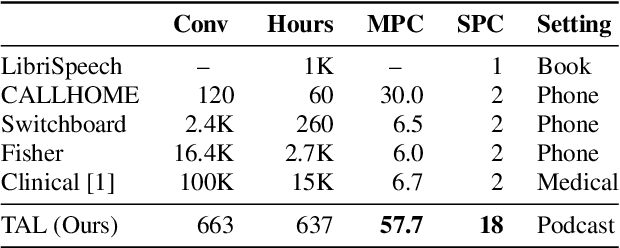
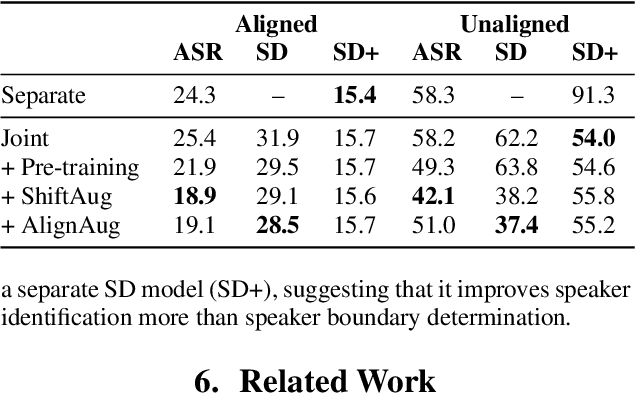
Speech recognition (ASR) and speaker diarization (SD) models have traditionally been trained separately to produce rich conversation transcripts with speaker labels. Recent advances have shown that joint ASR and SD models can learn to leverage audio-lexical inter-dependencies to improve word diarization performance. We introduce a new benchmark of hour-long podcasts collected from the weekly This American Life radio program to better compare these approaches when applied to extended multi-speaker conversations. We find that training separate ASR and SD models perform better when utterance boundaries are known but otherwise joint models can perform better. To handle long conversations with unknown utterance boundaries, we introduce a striding attention decoding algorithm and data augmentation techniques which, combined with model pre-training, improves ASR and SD.