 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Recognition and Multi-Speaker Diarization of Long Conversations
Paper and Code
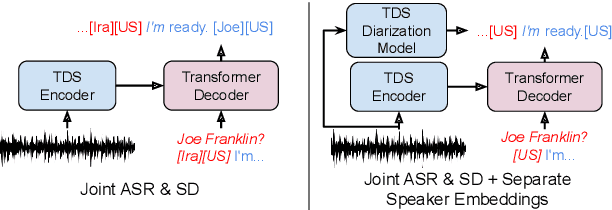
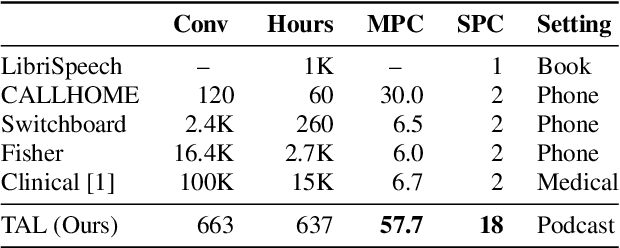
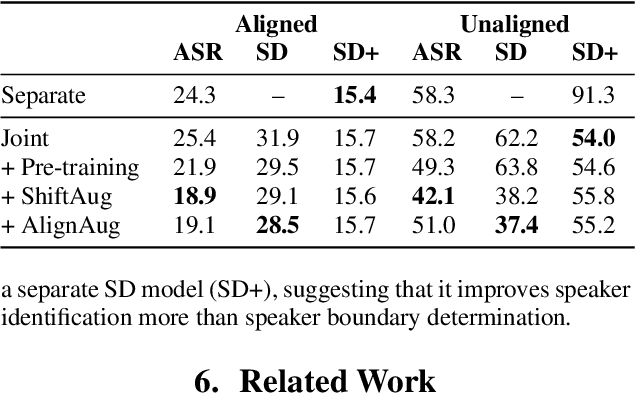
Speech recognition (ASR) and speaker diarization (SD) models have traditionally been trained separately to produce rich conversation transcripts with speaker labels. Recent advances have shown that joint ASR and SD models can learn to leverage audio-lexical inter-dependencies to improve word diarization performance. We introduce a new benchmark of hour-long podcasts collected from the weekly This American Life radio program to better compare these approaches when applied to extended multi-speaker conversations. We find that training separate ASR and SD models perform better when utterance boundaries are known but otherwise joint models can perform better. To handle long conversations with unknown utterance boundaries, we introduce a striding attention decoding algorithm and data augmentation techniques which, combined with model pre-training, improves ASR and SD.