 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Do End-to-End Speech Recognition Models Care About Context?
Feb 17, 2021
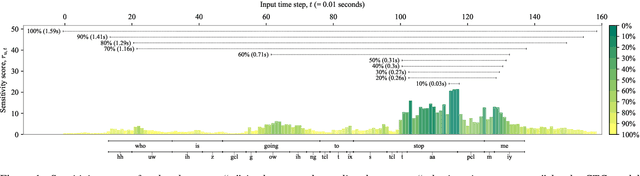
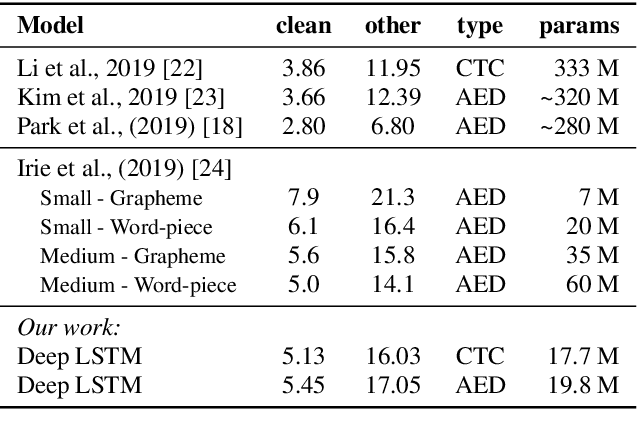
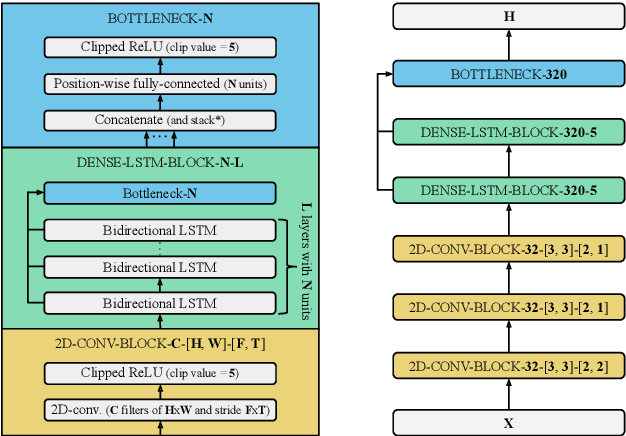
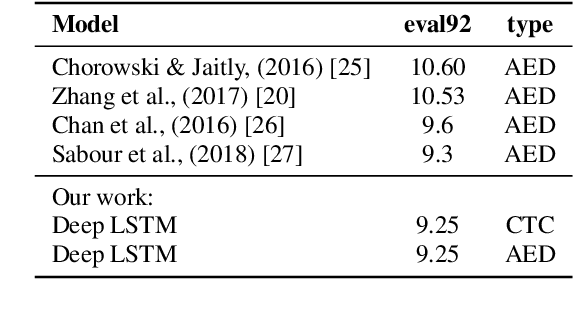
The two most common paradigms for end-to-end speech recognition are connectionist temporal classification (CTC) and attention-based encoder-decoder (AED) models. It has been argued that the latter is better suited for learning an implicit language model. We test this hypothesis by measuring temporal context sensitivity and evaluate how the models perform when we constrain the amount of contextual information in the audio input. We find that the AED model is indeed more context sensitive, but that the gap can be closed by adding self-attention to the CTC model. Furthermore, the two models perform similarly when contextual information is constrained. Finally, in contrast to previous research, our results show that the CTC model is highly competitive on WSJ and LibriSpeech without the help of an external language model.
End-to-End Speech to Intent Prediction to improve E-commerce Customer Support Voicebot in Hindi and English
Oct 26, 2022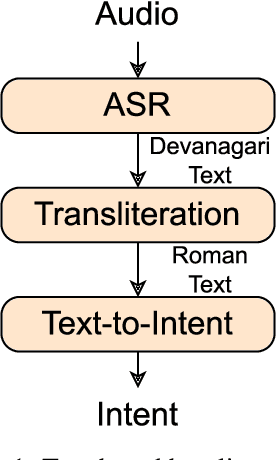

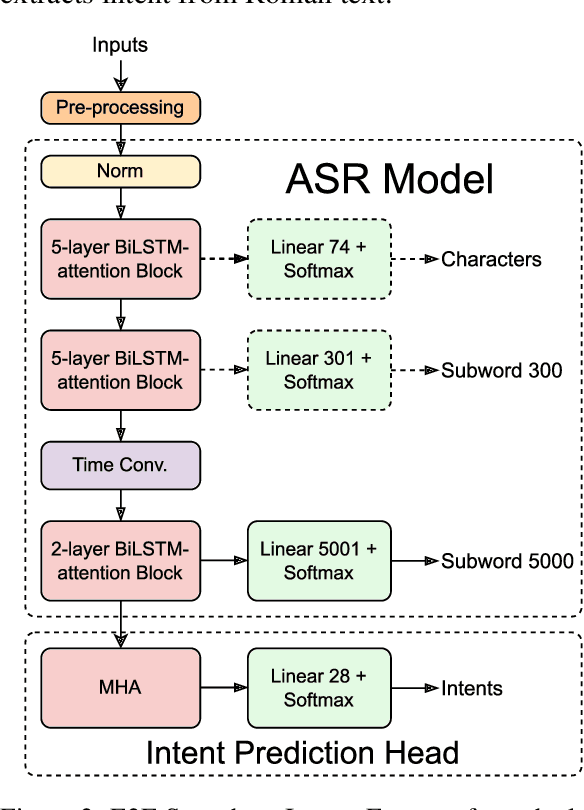
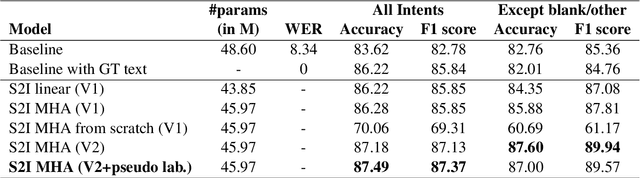
Automation of on-call customer support relies heavily on accurate and efficient speech-to-intent (S2I) systems. Building such systems using multi-component pipelines can pose various challenges because they require large annotated datasets, have higher latency, and have complex deployment. These pipelines are also prone to compounding errors. To overcome these challenges, we discuss an end-to-end (E2E) S2I model for customer support voicebot task in a bilingual setting. We show how we can solve E2E intent classification by leveraging a pre-trained automatic speech recognition (ASR) model with slight modification and fine-tuning on small annotated datasets. Experimental results show that our best E2E model outperforms a conventional pipeline by a relative ~27% on the F1 score.
Cross-domain Speech Recognition with Unsupervised Character-level Distribution Matching
Apr 16, 2021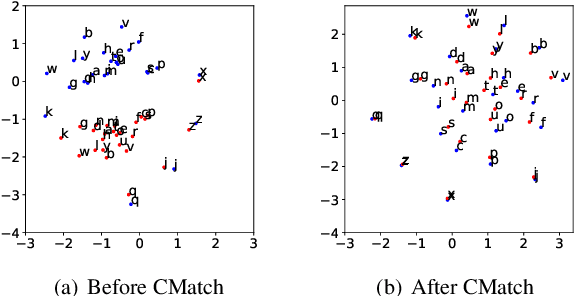

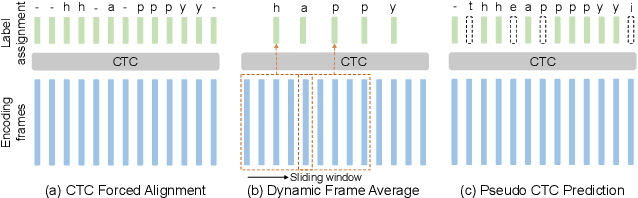
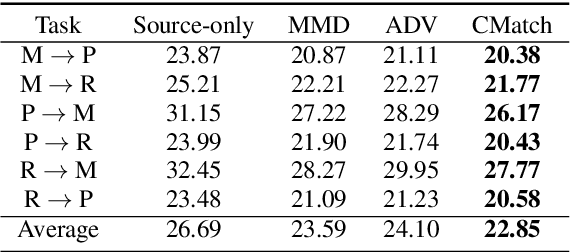
End-to-end automatic speech recognition (ASR) can achieve promising performance with large-scale training data. However, it is known that domain mismatch between training and testing data often leads to a degradation of recognition accuracy. In this work, we focus on the unsupervised domain adaptation for ASR and propose CMatch, a Character-level distribution matching method to perform fine-grained adaptation between each character in two domains. First, to obtain labels for the features belonging to each character, we achieve frame-level label assignment using the Connectionist Temporal Classification (CTC) pseudo labels. Then, we match the character-level distributions using Maximum Mean Discrepancy. We train our algorithm using the self-training technique. Experiments on the Libri-Adapt dataset show that our proposed approach achieves 14.39% and 16.50% relative Word Error Rate (WER) reduction on both cross-device and cross-environment ASR. We also comprehensively analyze the different strategies for frame-level label assignment and Transformer adaptations.
Context-aware Fine-tuning of Self-supervised Speech Models
Dec 16, 2022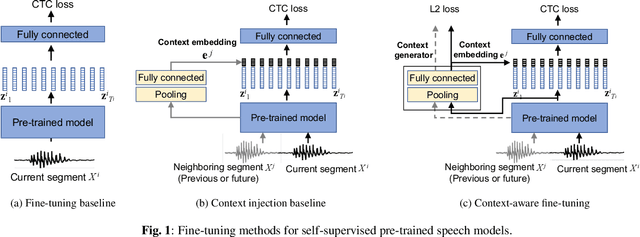
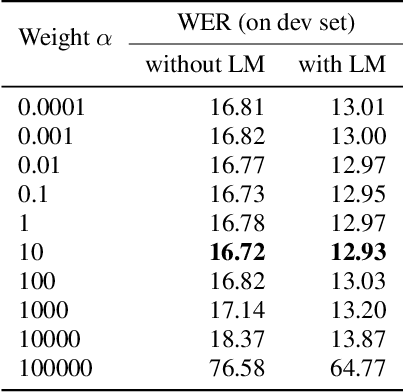
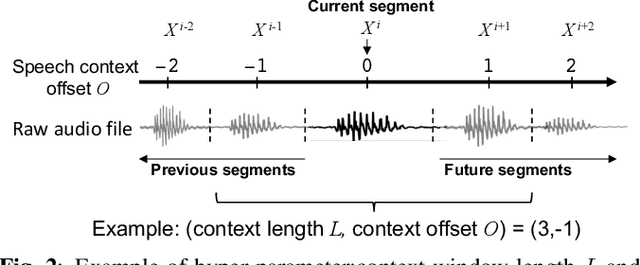
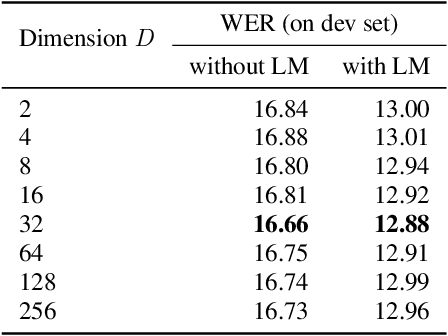
Self-supervised pre-trained transformers have improved the state of the art on a variety of speech tasks. Due to the quadratic time and space complexity of self-attention, they usually operate at the level of relatively short (e.g., utterance) segments. In this paper, we study the use of context, i.e., surrounding segments, during fine-tuning and propose a new approach called context-aware fine-tuning. We attach a context module on top of the last layer of a pre-trained model to encode the whole segment into a context embedding vector which is then used as an additional feature for the final prediction. During the fine-tuning stage, we introduce an auxiliary loss that encourages this context embedding vector to be similar to context vectors of surrounding segments. This allows the model to make predictions without access to these surrounding segments at inference time and requires only a tiny overhead compared to standard fine-tuned models. We evaluate the proposed approach using the SLUE and Librilight benchmarks for several downstream tasks: Automatic speech recognition (ASR), named entity recognition (NER), and sentiment analysis (SA). The results show that context-aware fine-tuning not only outperforms a standard fine-tuning baseline but also rivals a strong context injection baseline that uses neighboring speech segments during inference.
End-to-End Multi-Channel Transformer for Speech Recognition
Feb 08, 2021
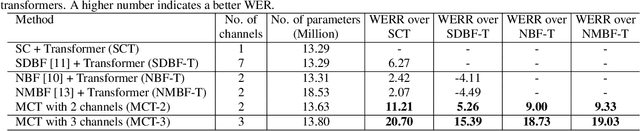
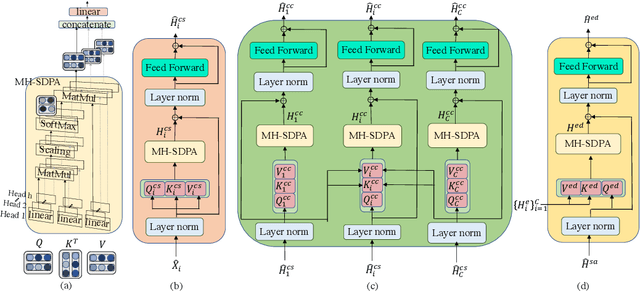

Transformers are powerful neural architectures that allow integrating different modalities using attention mechanisms. In this paper, we leverage the neural transformer architectures for multi-channel speech recognition systems, where the spectral and spatial information collected from different microphones are integrated using attention layers. Our multi-channel transformer network mainly consists of three parts: channel-wise self attention layers (CSA), cross-channel attention layers (CCA), and multi-channel encoder-decoder attention layers (EDA). The CSA and CCA layers encode the contextual relationship within and between channels and across time, respectively. The channel-attended outputs from CSA and CCA are then fed into the EDA layers to help decode the next token given the preceding ones. The experiments show that in a far-field in-house dataset, our method outperforms the baseline single-channel transformer, as well as the super-directive and neural beamformers cascaded with the transformers.
Does Joint Training Really Help Cascaded Speech Translation?
Oct 24, 2022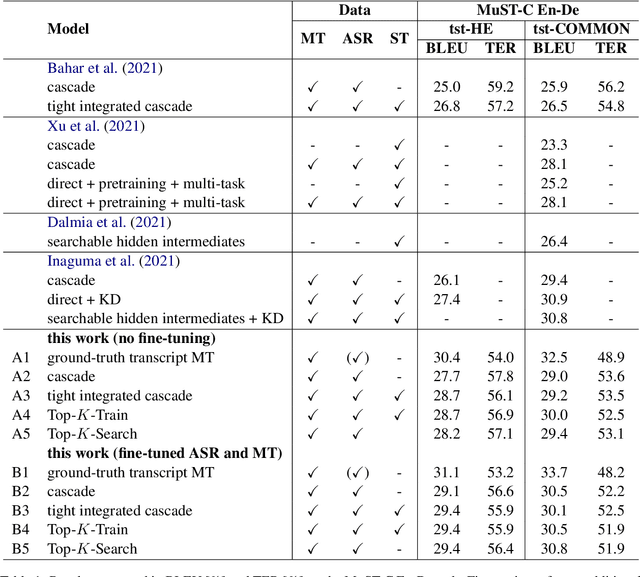
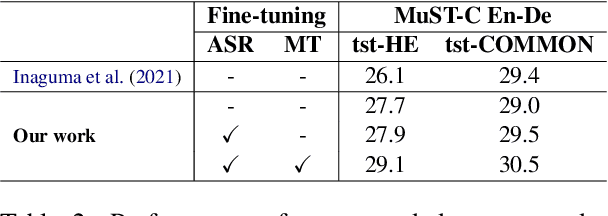
Currently, in speech translation, the straightforward approach - cascading a recognition system with a translation system - delivers state-of-the-art results. However, fundamental challenges such as error propagation from the automatic speech recognition system still remain. To mitigate these problems, recently, people turn their attention to direct data and propose various joint training methods. In this work, we seek to answer the question of whether joint training really helps cascaded speech translation. We review recent papers on the topic and also investigate a joint training criterion by marginalizing the transcription posterior probabilities. Our findings show that a strong cascaded baseline can diminish any improvements obtained using joint training, and we suggest alternatives to joint training. We hope this work can serve as a refresher of the current speech translation landscape, and motivate research in finding more efficient and creative ways to utilize the direct data for speech translation.
On using 2D sequence-to-sequence models for speech recognition
Nov 20, 2019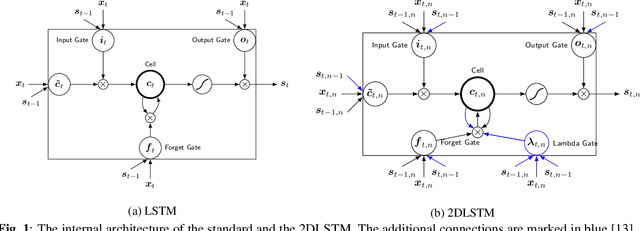

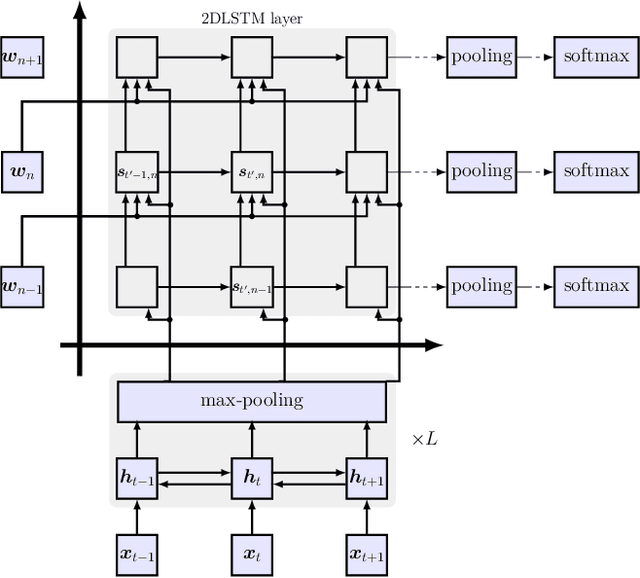
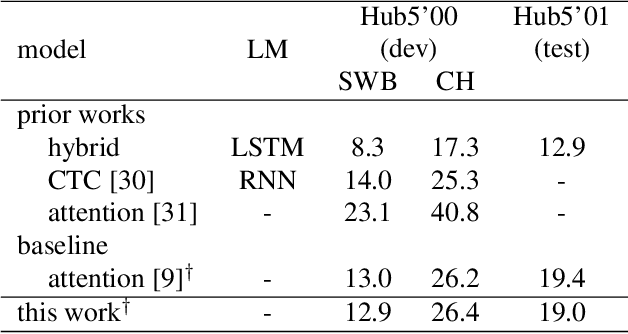
Attention-based sequence-to-sequence models have shown promising results in automatic speech recognition. Using these architectures, one-dimensional input and output sequences are related by an attention approach, thereby replacing more explicit alignment processes, like in classical HMM-based modeling. In contrast, here we apply a novel two-dimensional long short-term memory (2DLSTM) architecture to directly model the input/output relation between audio/feature vector sequences and word sequences. The proposed model is an alternative model such that instead of using any type of attention components, we apply a 2DLSTM layer to assimilate the context from both input observations and output transcriptions. The experimental evaluation on the Switchboard 300h automatic speech recognition task shows word error rates for the 2DLSTM model that are competitive to end-to-end attention-based model.
Hybrid phonetic-neural model for correction in speech recognition systems
Feb 12, 2021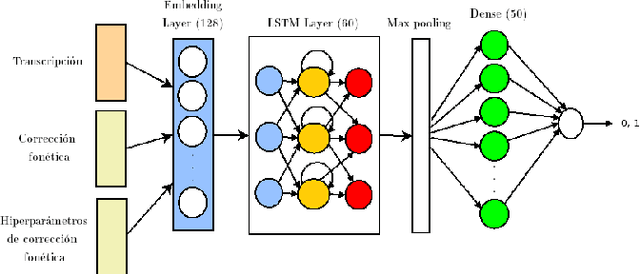
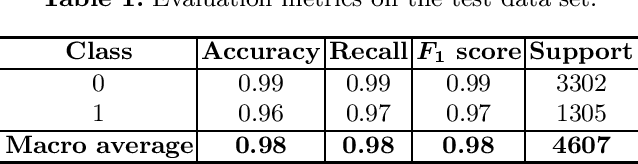
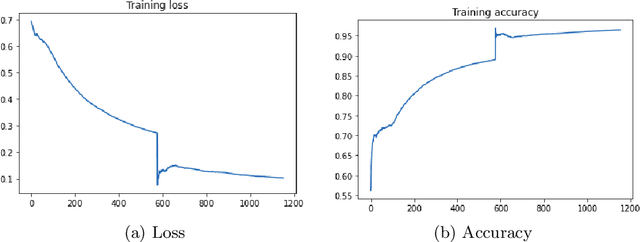
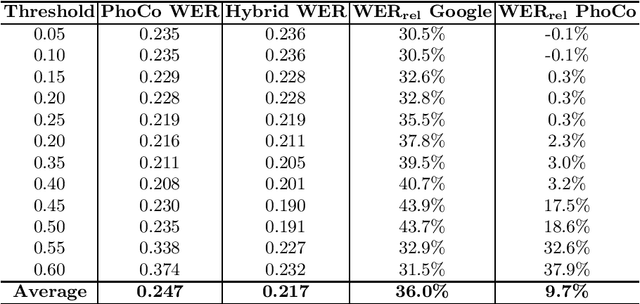
Automatic speech recognition (ASR) is a relevant area in multiple settings because it provides a natural communication mechanism between applications and users. ASRs often fail in environments that use language specific to particular application domains. Some strategies have been explored to reduce errors in closed ASRs through post-processing, particularly automatic spell checking, and deep learning approaches. In this article, we explore using a deep neural network to refine the results of a phonetic correction algorithm applied to a telesales audio database. The results exhibit a reduction in the word error rate (WER), both in the original transcription and in the phonetic correction, which shows the viability of deep learning models together with post-processing correction strategies to reduce errors made by closed ASRs in specific language domains.
Speech-text based multi-modal training with bidirectional attention for improved speech recognition
Nov 01, 2022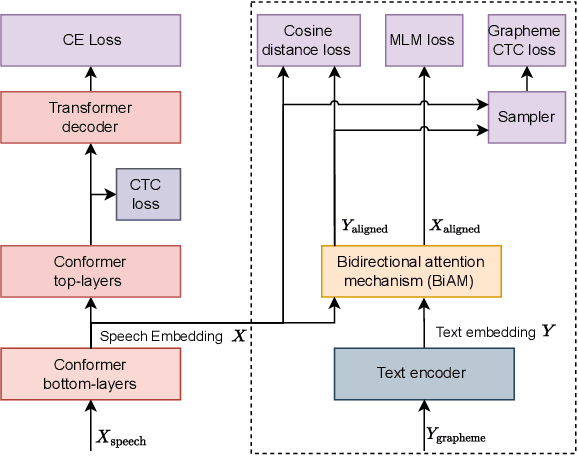
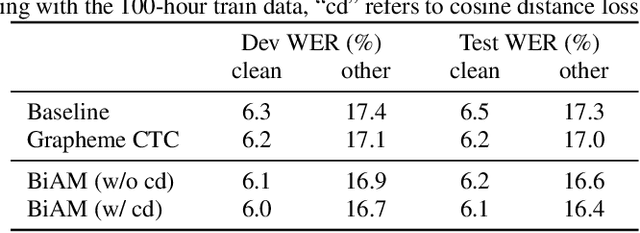
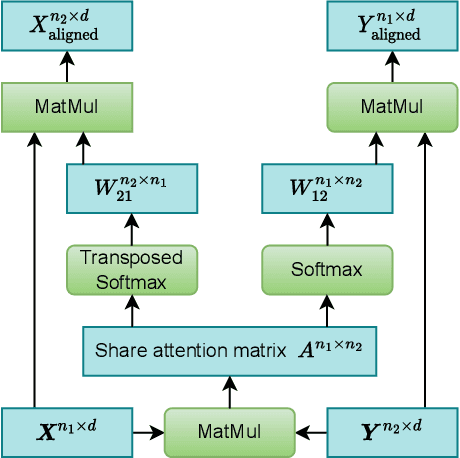
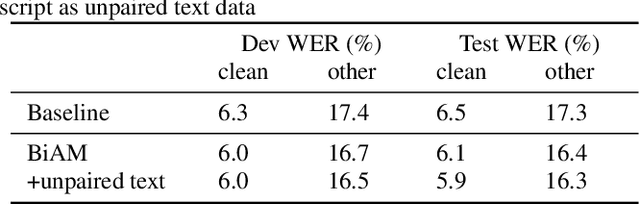
To let the state-of-the-art end-to-end ASR model enjoy data efficiency, as well as much more unpaired text data by multi-modal training, one needs to address two problems: 1) the synchronicity of feature sampling rates between speech and language (aka text data); 2) the homogeneity of the learned representations from two encoders. In this paper we propose to employ a novel bidirectional attention mechanism (BiAM) to jointly learn both ASR encoder (bottom layers) and text encoder with a multi-modal learning method. The BiAM is to facilitate feature sampling rate exchange, realizing the quality of the transformed features for the one kind to be measured in another space, with diversified objective functions. As a result, the speech representations are enriched with more linguistic information, while the representations generated by the text encoder are more similar to corresponding speech ones, and therefore the shared ASR models are more amenable for unpaired text data pretraining. To validate the efficacy of the proposed method, we perform two categories of experiments with or without extra unpaired text data. Experimental results on Librispeech corpus show it can achieve up to 6.15% word error rate reduction (WERR) with only paired data learning, while 9.23% WERR when more unpaired text data is employed.