 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolutionary optimization of contexts for phonetic correction in speech recognition systems
Feb 23, 2021
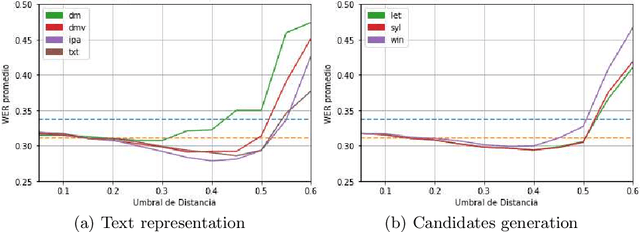
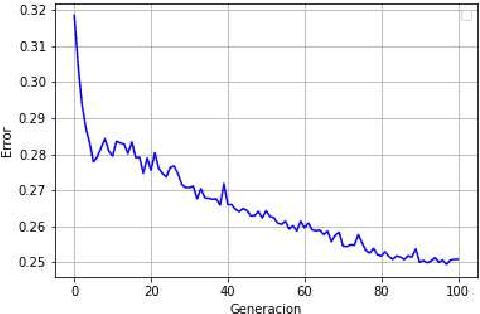
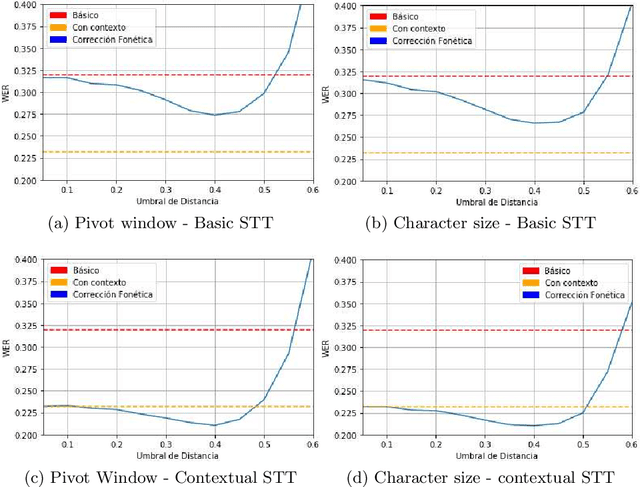
Automatic Speech Recognition (ASR) is an area of growing academic and commercial interest due to the high demand for applications that use it to provide a natural communication method. It is common for general purpose ASR systems to fail in applications that use a domain-specific language. Various strategies have been used to reduce the error, such as providing a context that modifies the language model and post-processing correction methods. This article explores the use of an evolutionary process to generate an optimized context for a specific application domain, as well as different correction techniques based on phonetic distance metrics. The results show the viability of a genetic algorithm as a tool for context optimization, which, added to a post-processing correction based on phonetic representations, can reduce the errors on the recognized speech.
* 13 pages, 4 figures, This article is a translation of the paper "Optimizaci\'on evolutiva de contextos para la correcci\'on fon\'etica en sistemas de reconocimiento del habla" presented in COMIA 2019
Hybrid phonetic-neural model for correction in speech recognition systems
Feb 12, 2021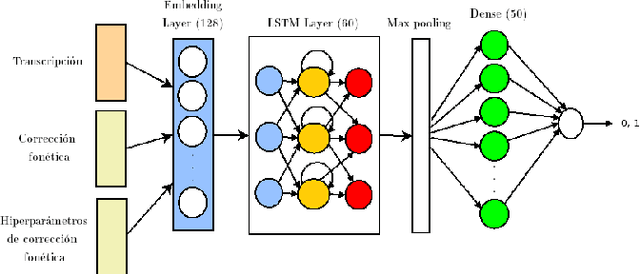
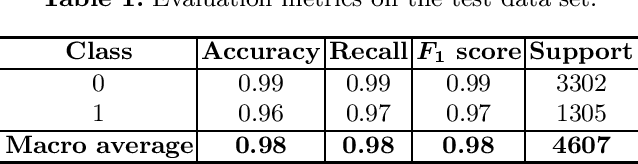
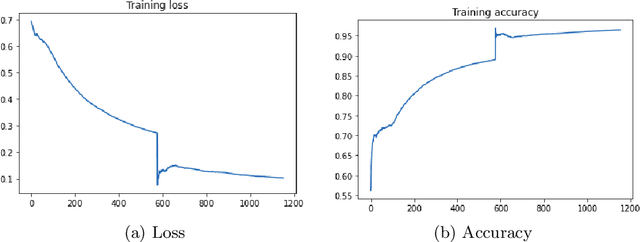
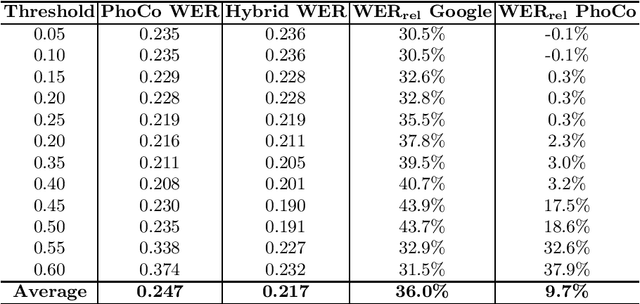
Automatic speech recognition (ASR) is a relevant area in multiple settings because it provides a natural communication mechanism between applications and users. ASRs often fail in environments that use language specific to particular application domains. Some strategies have been explored to reduce errors in closed ASRs through post-processing, particularly automatic spell checking, and deep learning approaches. In this article, we explore using a deep neural network to refine the results of a phonetic correction algorithm applied to a telesales audio database. The results exhibit a reduction in the word error rate (WER), both in the original transcription and in the phonetic correction, which shows the viability of deep learning models together with post-processing correction strategies to reduce errors made by closed ASRs in specific language domains.