 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Combining Spectral and Self-Supervised Features for Low Resource Speech Recognition and Translation
Apr 18, 2022
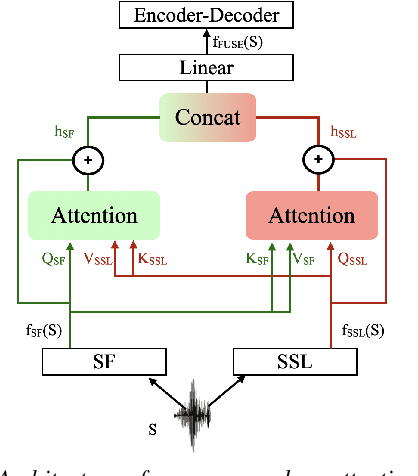
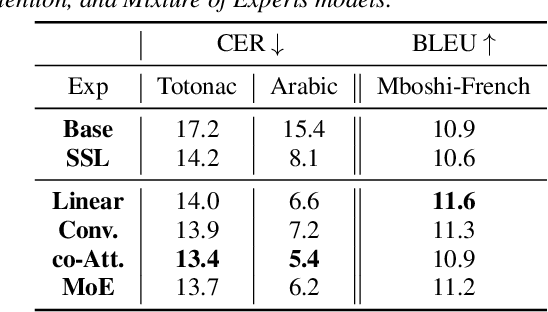
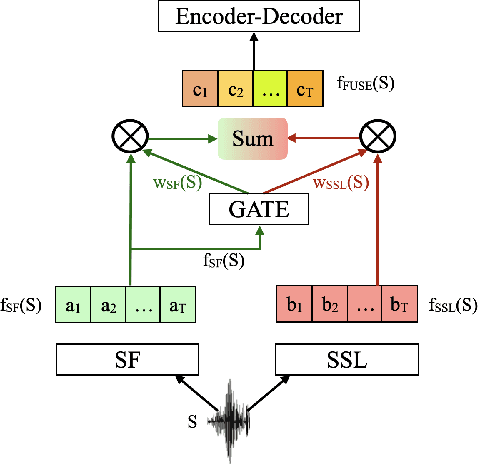

Self-Supervised Learning (SSL) models have been successfully applied in various deep learning-based speech tasks, particularly those with a limited amount of data. However, the quality of SSL representations depends highly on the relatedness between the SSL training domain(s) and the target data domain. On the contrary, spectral feature (SF) extractors such as log Mel-filterbanks are hand-crafted non-learnable components, and could be more robust to domain shifts. The present work examines the assumption that combining non-learnable SF extractors to SSL models is an effective approach to low resource speech tasks. We propose a learnable and interpretable framework to combine SF and SSL representations. The proposed framework outperforms significantly both baseline and SSL models on Automatic Speech Recognition (ASR) and Speech Translation (ST) tasks on three low resource datasets. We additionally design a mixture of experts based combination model. This last model reveals that the relative contribution of SSL models over conventional SF extractors is very small in case of domain mismatch between SSL training set and the target language data.
Fine-tuning Strategies for Faster Inference using Speech Self-Supervised Models: A Comparative Study
Mar 12, 2023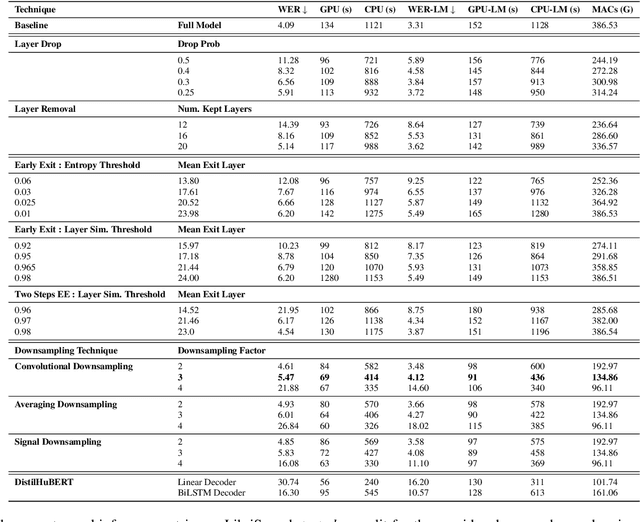
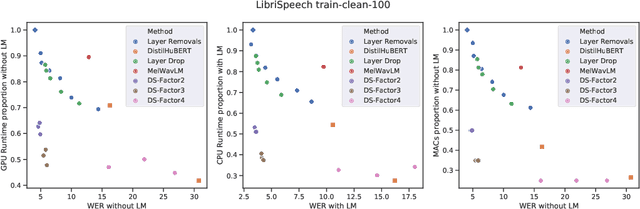
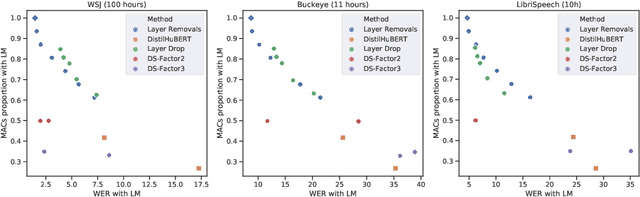
Self-supervised learning (SSL) has allowed substantial progress in Automatic Speech Recognition (ASR) performance in low-resource settings. In this context, it has been demonstrated that larger self-supervised feature extractors are crucial for achieving lower downstream ASR error rates. Thus, better performance might be sanctioned with longer inferences. This article explores different approaches that may be deployed during the fine-tuning to reduce the computations needed in the SSL encoder, leading to faster inferences. We adapt a number of existing techniques to common ASR settings and benchmark them, displaying performance drops and gains in inference times. Interestingly, we found that given enough downstream data, a simple downsampling of the input sequences outperforms the other methods with both low performance drops and high computational savings, reducing computations by 61.3% with an WER increase of only 0.81. Finally, we analyze the robustness of the comparison to changes in dataset conditions, revealing sensitivity to dataset size.
Improving the Intent Classification accuracy in Noisy Environment
Mar 12, 2023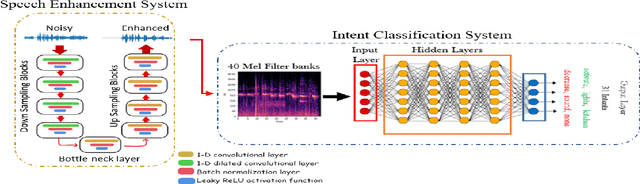

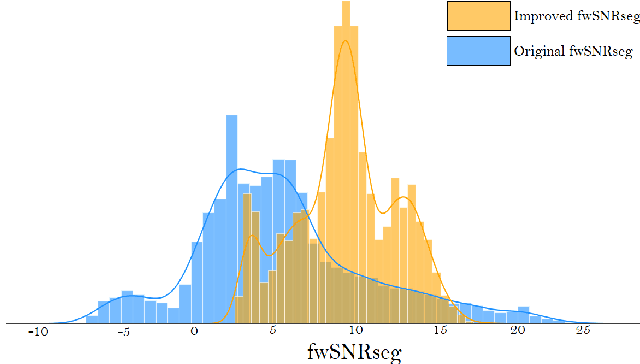
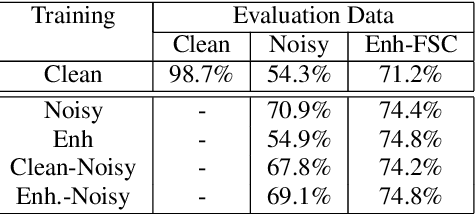
Intent classification is a fundamental task in the spoken language understanding field that has recently gained the attention of the scientific community, mainly because of the feasibility of approaching it with end-to-end neural models. In this way, avoiding using intermediate steps, i.e. automatic speech recognition, is possible, thus the propagation of errors due to background noise, spontaneous speech, speaking styles of users, etc. Towards the development of solutions applicable in real scenarios, it is interesting to investigate how environmental noise and related noise reduction techniques to address the intent classification task with end-to-end neural models. In this paper, we experiment with a noisy version of the fluent speech command data set, combining the intent classifier with a time-domain speech enhancement solution based on Wave-U-Net and considering different training strategies. Experimental results reveal that, for this task, the use of speech enhancement greatly improves the classification accuracy in noisy conditions, in particular when the classification model is trained on enhanced signals.
Private Language Model Adaptation for Speech Recognition
Sep 28, 2021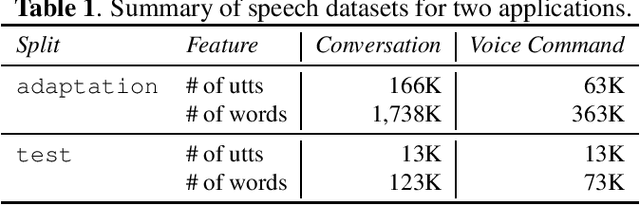
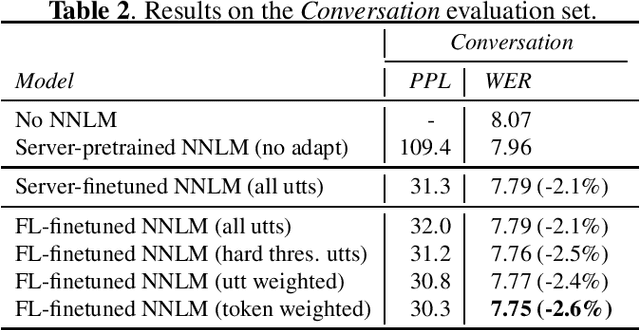
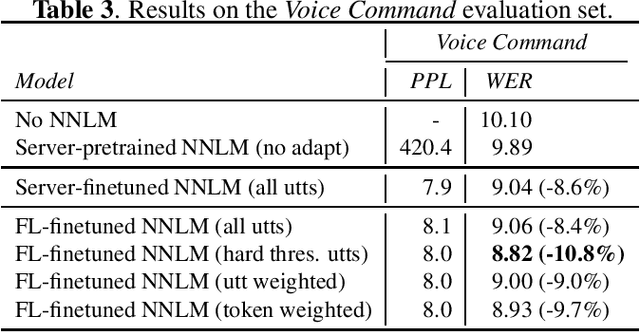
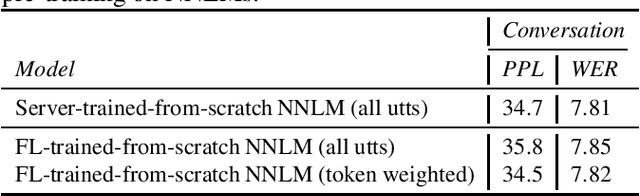
Speech model adaptation is crucial to handle the discrepancy between server-side proxy training data and actual data received on users' local devices. With the use of federated learning (FL), we introduce an efficient approach on continuously adapting neural network language models (NNLMs) on private devices with applications on automatic speech recognition (ASR). To address the potential speech transcription errors in the on-device training corpus, we perform empirical studies on comparing various strategies of leveraging token-level confidence scores to improve the NNLM quality in the FL settings. Experiments show that compared with no model adaptation, the proposed method achieves relative 2.6% and 10.8% word error rate (WER) reductions on two speech evaluation datasets, respectively. We also provide analysis in evaluating privacy guarantees of our presented procedure.
Multilingual and crosslingual speech recognition using phonological-vector based phone embeddings
Jul 11, 2021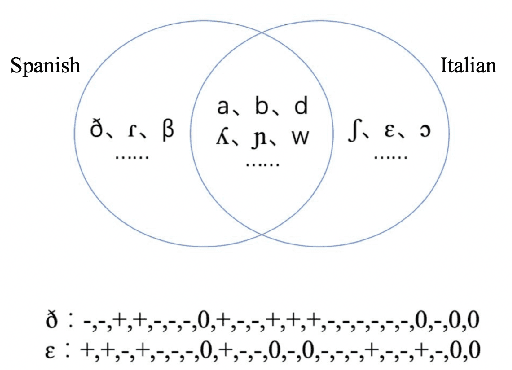
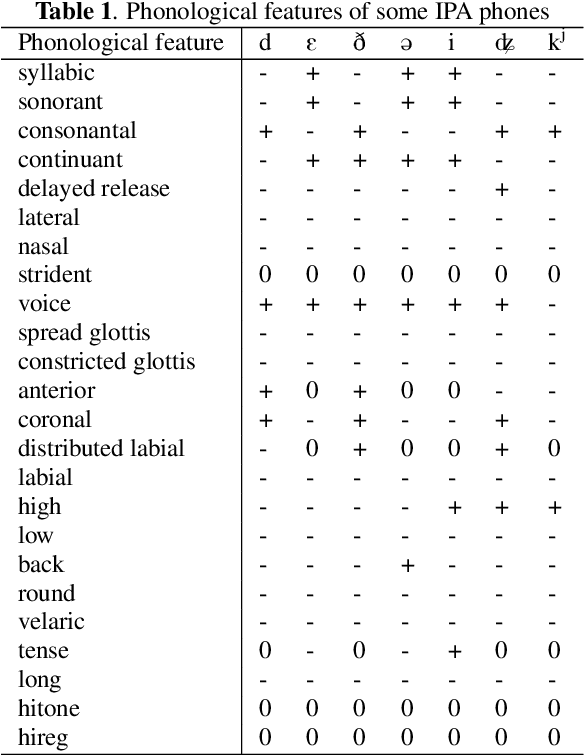
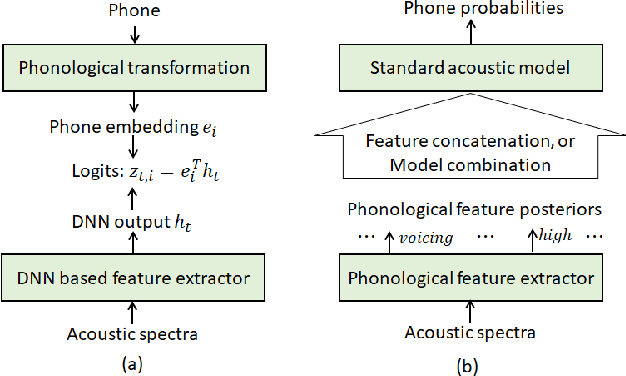
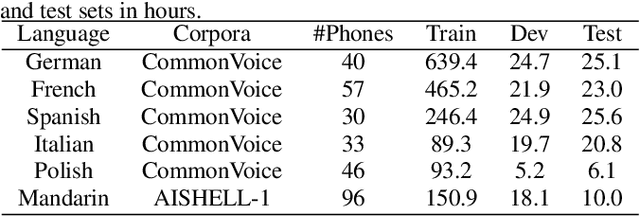
The use of phonological features (PFs) potentially allows language-specific phones to remain linked in training, which is highly desirable for information sharing for multilingual and crosslingual speech recognition methods for low-resourced languages. A drawback suffered by previous methods in using phonological features is that the acoustic-to-PF extraction in a bottom-up way is itself difficult. In this paper, we propose to join phonology driven phone embedding (top-down) and deep neural network (DNN) based acoustic feature extraction (bottom-up) to calculate phone probabilities. The new method is called JoinAP (Joining of Acoustics and Phonology). Remarkably, no inversion from acoustics to phonological features is required for speech recognition. For each phone in the IPA (International Phonetic Alphabet) table, we encode its phonological features to a phonological-vector, and then apply linear or nonlinear transformation of the phonological-vector to obtain the phone embedding. A series of multilingual and crosslingual (both zero-shot and few-shot) speech recognition experiments are conducted on the CommonVoice dataset (German, French, Spanish and Italian) and the AISHLL-1 dataset (Mandarin), and demonstrate the superiority of JoinAP with nonlinear phone embeddings over both JoinAP with linear phone embeddings and the traditional method with flat phone embeddings.
Lego-Features: Exporting modular encoder features for streaming and deliberation ASR
Mar 31, 2023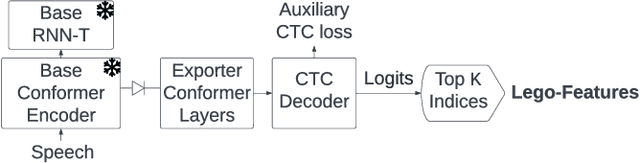
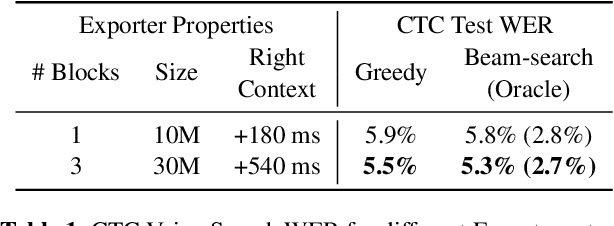
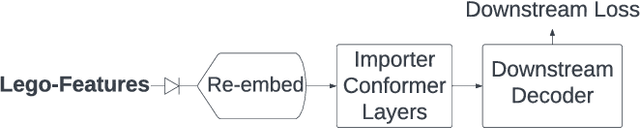

In end-to-end (E2E) speech recognition models, a representational tight-coupling inevitably emerges between the encoder and the decoder. We build upon recent work that has begun to explore building encoders with modular encoded representations, such that encoders and decoders from different models can be stitched together in a zero-shot manner without further fine-tuning. While previous research only addresses full-context speech models, we explore the problem in a streaming setting as well. Our framework builds on top of existing encoded representations, converting them to modular features, dubbed as Lego-Features, without modifying the pre-trained model. The features remain interchangeable when the model is retrained with distinct initializations. Though sparse, we show that the Lego-Features are powerful when tested with RNN-T or LAS decoders, maintaining high-quality downstream performance. They are also rich enough to represent the first-pass prediction during two-pass deliberation. In this scenario, they outperform the N-best hypotheses, since they do not need to be supplemented with acoustic features to deliver the best results. Moreover, generating the Lego-Features does not require beam search or auto-regressive computation. Overall, they present a modular, powerful and cheap alternative to the standard encoder output, as well as the N-best hypotheses.
LiteG2P: A fast, light and high accuracy model for grapheme-to-phoneme conversion
Mar 02, 2023
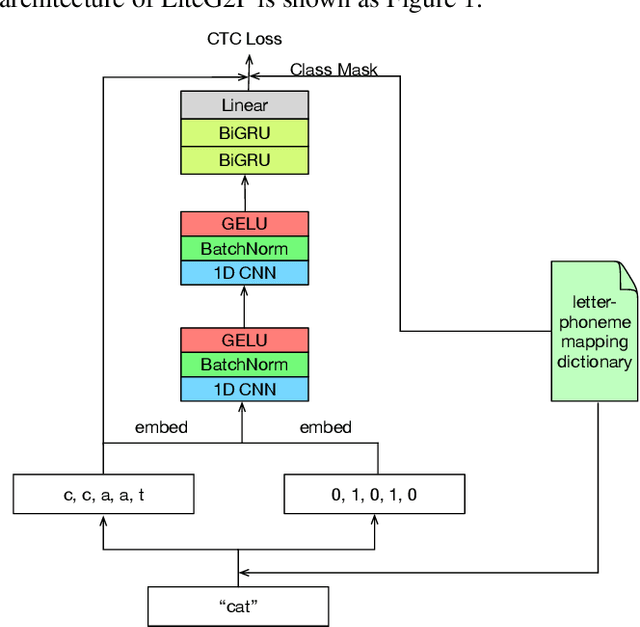
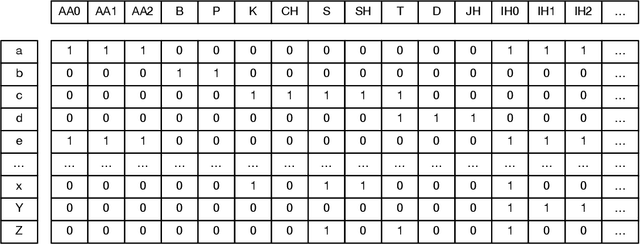
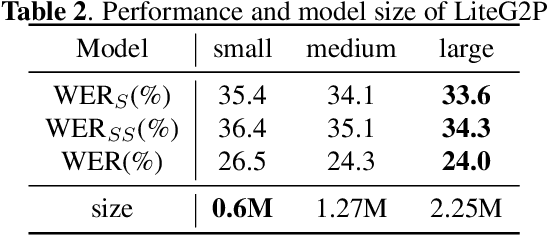
As a key component of automated speech recognition (ASR) and the front-end in text-to-speech (TTS), grapheme-to-phoneme (G2P) plays the role of converting letters to their corresponding pronunciations. Existing methods are either slow or poor in performance, and are limited in application scenarios, particularly in the process of on-device inference. In this paper, we integrate the advantages of both expert knowledge and connectionist temporal classification (CTC) based neural network and propose a novel method named LiteG2P which is fast, light and theoretically parallel. With the carefully leading design, LiteG2P can be applied both on cloud and on device. Experimental results on the CMU dataset show that the performance of the proposed method is superior to the state-of-the-art CTC based method with 10 times fewer parameters, and even comparable to the state-of-the-art Transformer-based sequence-to-sequence model with less parameters and 33 times less computation.
Structured Pruning of Self-Supervised Pre-trained Models for Speech Recognition and Understanding
Feb 27, 2023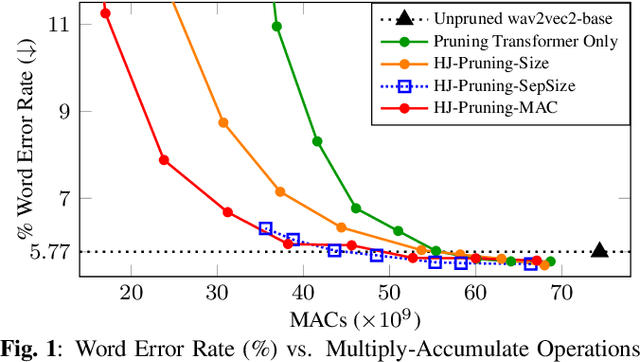
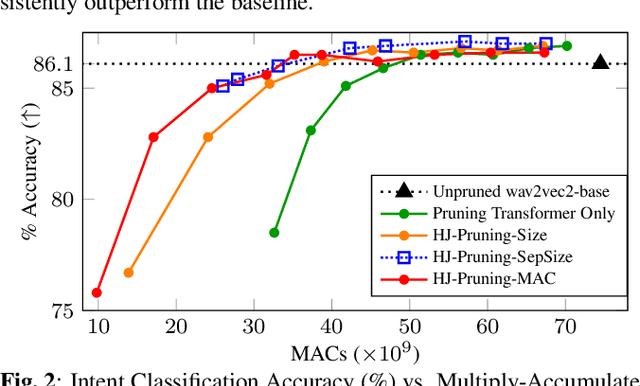
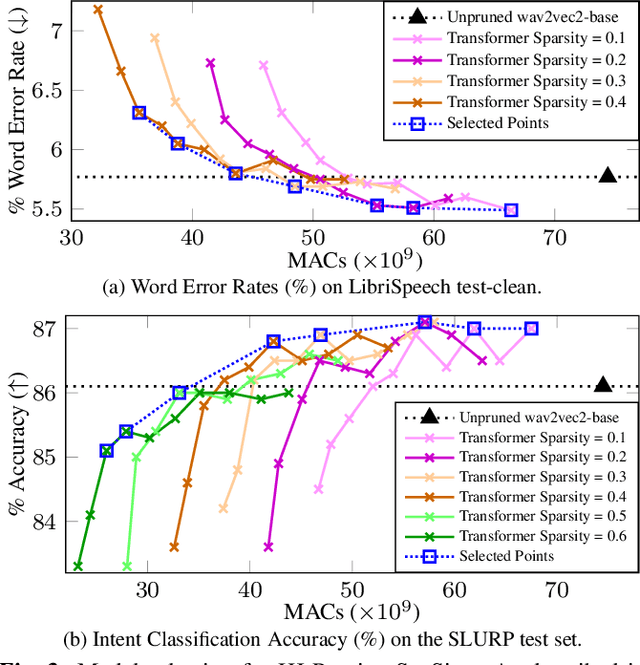
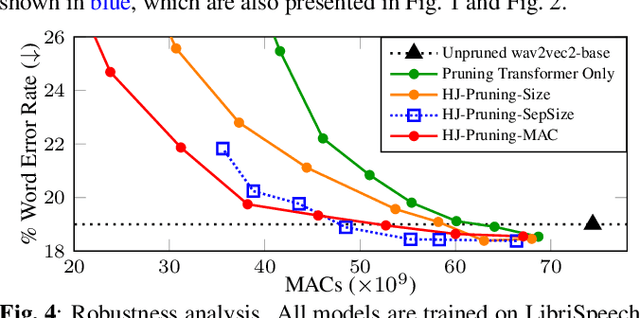
Self-supervised speech representation learning (SSL) has shown to be effective in various downstream tasks, but SSL models are usually large and slow. Model compression techniques such as pruning aim to reduce the model size and computation without degradation in accuracy. Prior studies focus on the pruning of Transformers; however, speech models not only utilize a stack of Transformer blocks, but also combine a frontend network based on multiple convolutional layers for low-level feature representation learning. This frontend has a small size but a heavy computational cost. In this work, we propose three task-specific structured pruning methods to deal with such heterogeneous networks. Experiments on LibriSpeech and SLURP show that the proposed method is more accurate than the original wav2vec2-base with 10% to 30% less computation, and is able to reduce the computation by 40% to 50% without any degradation.
Branchformer: Parallel MLP-Attention Architectures to Capture Local and Global Context for Speech Recognition and Understanding
Jul 06, 2022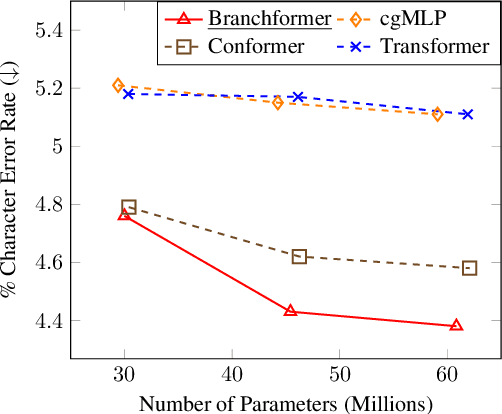
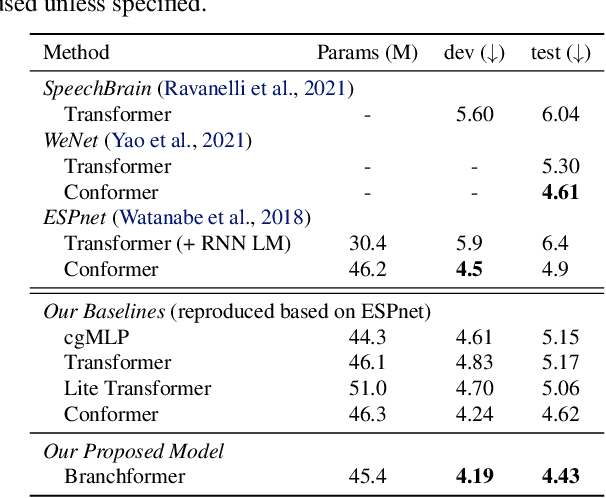
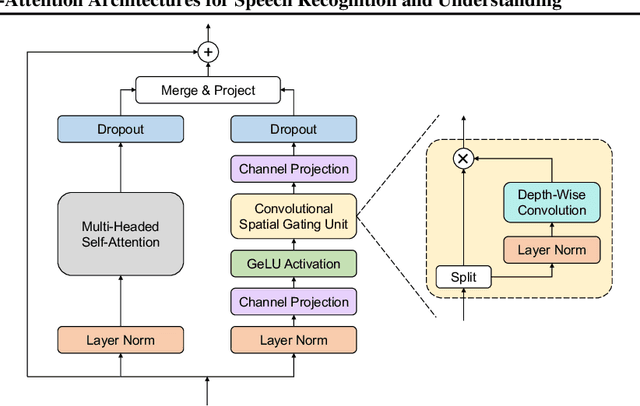
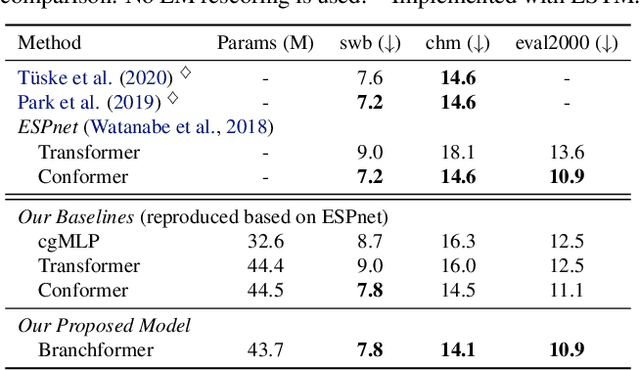
Conformer has proven to be effective in many speech processing tasks. It combines the benefits of extracting local dependencies using convolutions and global dependencies using self-attention. Inspired by this, we propose a more flexible, interpretable and customizable encoder alternative, Branchformer, with parallel branches for modeling various ranged dependencies in end-to-end speech processing. In each encoder layer, one branch employs self-attention or its variant to capture long-range dependencies, while the other branch utilizes an MLP module with convolutional gating (cgMLP) to extract local relationships. We conduct experiments on several speech recognition and spoken language understanding benchmarks. Results show that our model outperforms both Transformer and cgMLP. It also matches with or outperforms state-of-the-art results achieved by Conformer. Furthermore, we show various strategies to reduce computation thanks to the two-branch architecture, including the ability to have variable inference complexity in a single trained model. The weights learned for merging branches indicate how local and global dependencies are utilized in different layers, which benefits model designing.
RescoreBERT: Discriminative Speech Recognition Rescoring with BERT
Feb 07, 2022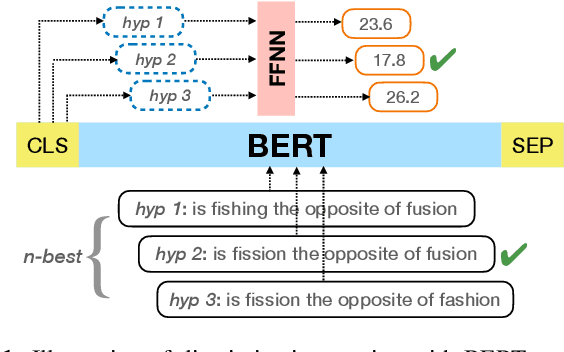
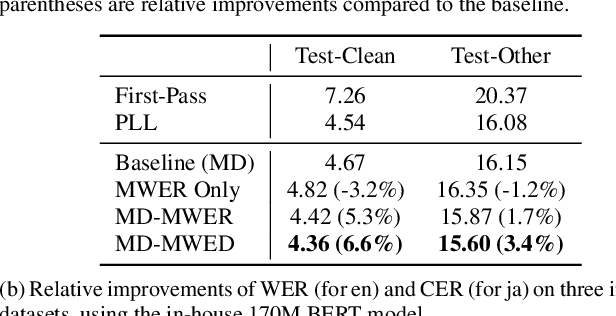

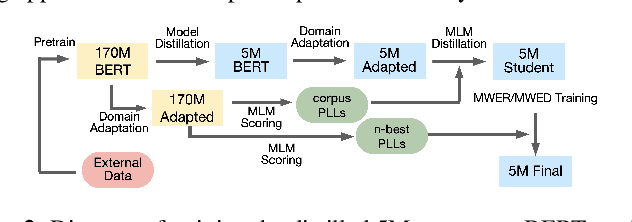
Second-pass rescoring is an important component in automatic speech recognition (ASR) systems that is used to improve the outputs from a first-pass decoder by implementing a lattice rescoring or $n$-best re-ranking. While pretraining with a masked language model (MLM) objective has received great success in various natural language understanding (NLU) tasks, it has not gained traction as a rescoring model for ASR. Specifically, training a bidirectional model like BERT on a discriminative objective such as minimum WER (MWER) has not been explored. Here we show how to train a BERT-based rescoring model with MWER loss, to incorporate the improvements of a discriminative loss into fine-tuning of deep bidirectional pretrained models for ASR. Specifically, we propose a fusion strategy that incorporates the MLM into the discriminative training process to effectively distill knowledge from a pretrained model. We further propose an alternative discriminative loss. We name this approach RescoreBERT. On the LibriSpeech corpus, it reduces WER by 6.6%/3.4% relative on clean/other test sets over a BERT baseline without discriminative objective. We also evaluate our method on an internal dataset from a conversational agent and find that it reduces both latency and WER (by 3 to 8% relative) over an LSTM rescoring model.