 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Explaining the Attention Mechanism of End-to-End Speech Recognition Using Decision Trees
Oct 08, 2021
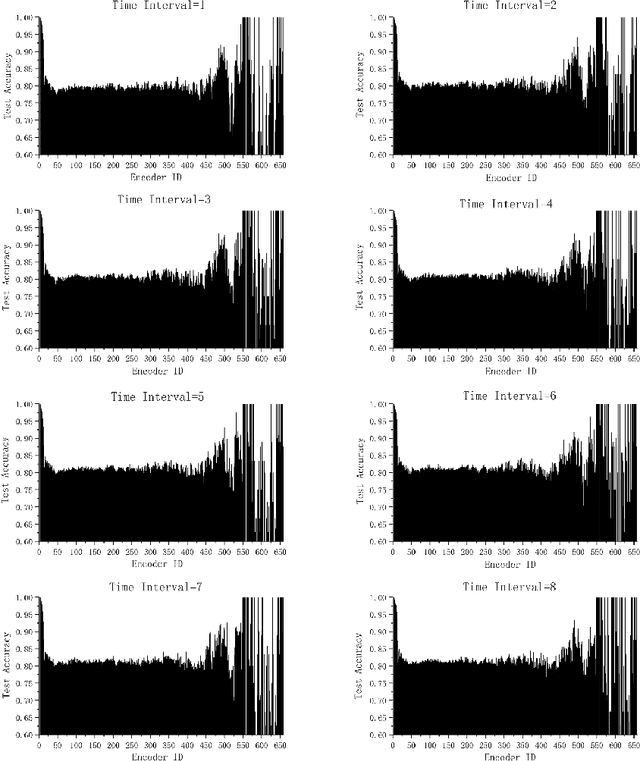
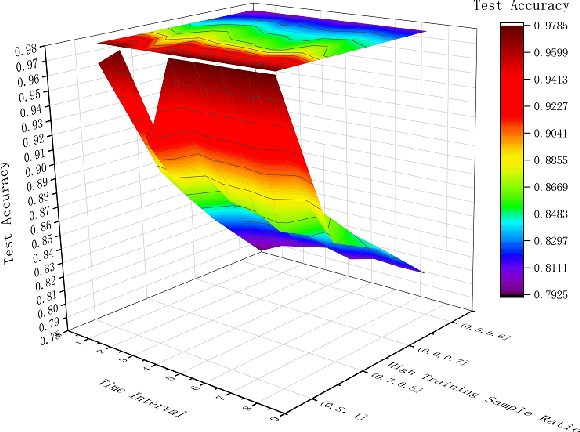
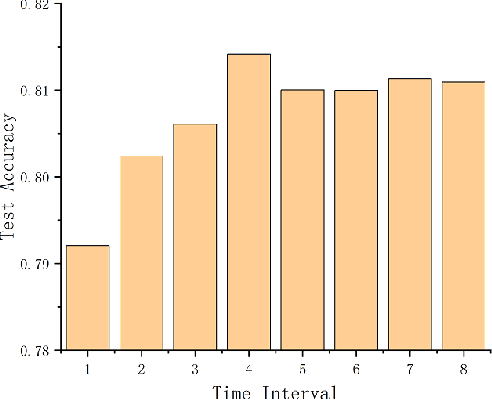
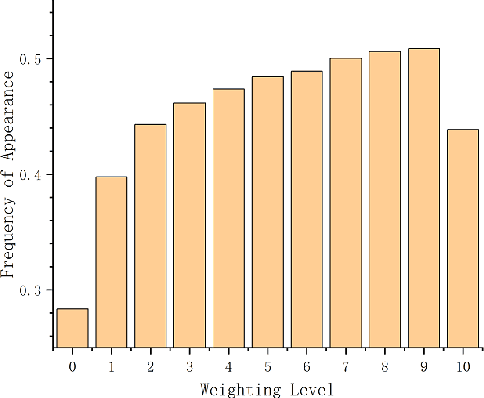
The attention mechanism has largely improved the performance of end-to-end speech recognition systems. However, the underlying behaviours of attention is not yet clearer. In this study, we use decision trees to explain how the attention mechanism impact itself in speech recognition. The results indicate that attention levels are largely impacted by their previous states rather than the encoder and decoder patterns. Additionally, the default attention mechanism seems to put more weights on closer states, but behaves poorly on modelling long-term dependencies of attention states.
Joint unsupervised and supervised learning for context-aware language identification
Mar 29, 2023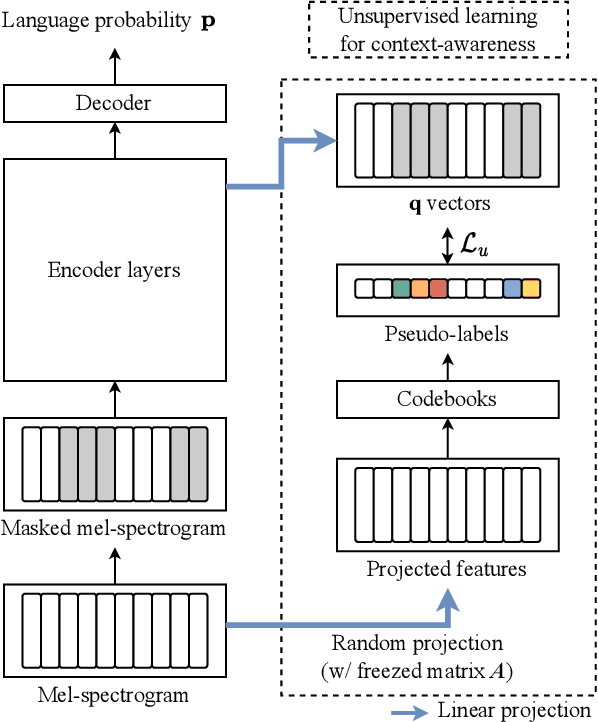
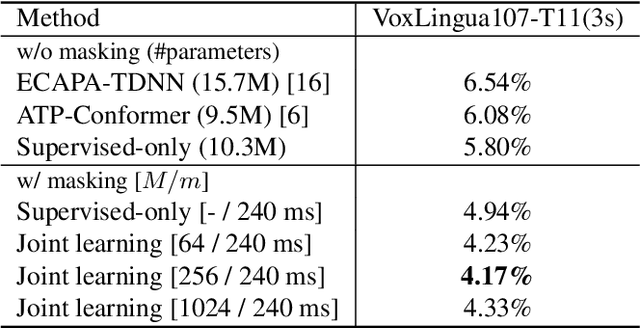
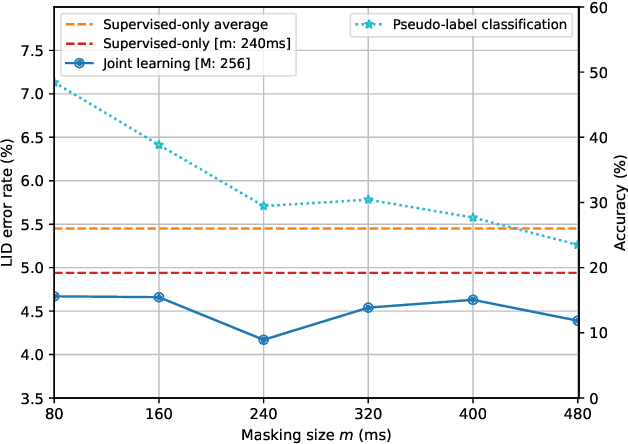
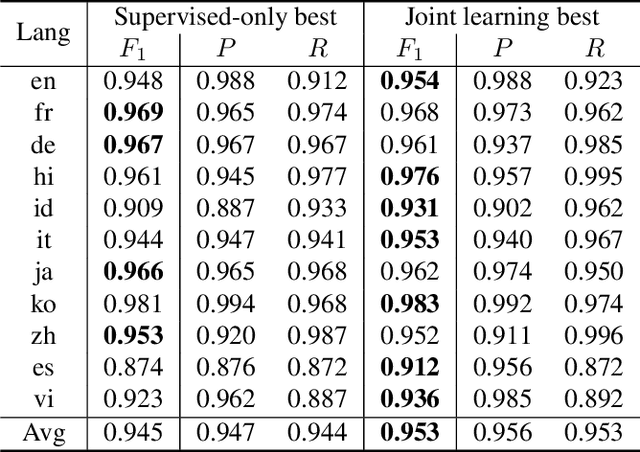
Language identification (LID) recognizes the language of a spoken utterance automatically. According to recent studies, LID models trained with an automatic speech recognition (ASR) task perform better than those trained with a LID task only. However, we need additional text labels to train the model to recognize speech, and acquiring the text labels is a cost high. In order to overcome this problem, we propose context-aware language identification using a combination of unsupervised and supervised learning without any text labels. The proposed method learns the context of speech through masked language modeling (MLM) loss and simultaneously trains to determine the language of the utterance with supervised learning loss. The proposed joint learning was found to reduce the error rate by 15.6% compared to the same structure model trained by supervised-only learning on a subset of the VoxLingua107 dataset consisting of sub-three-second utterances in 11 languages.
Interactive Feature Fusion for End-to-End Noise-Robust Speech Recognition
Oct 11, 2021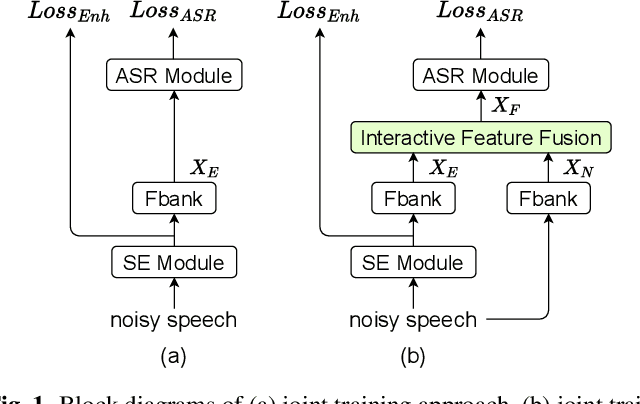
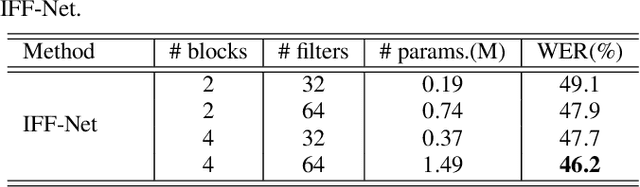
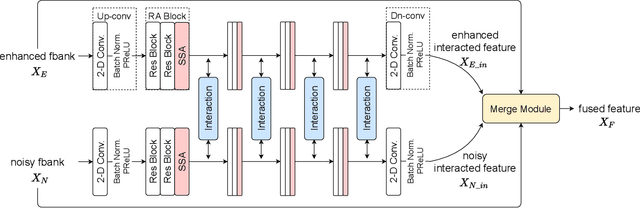
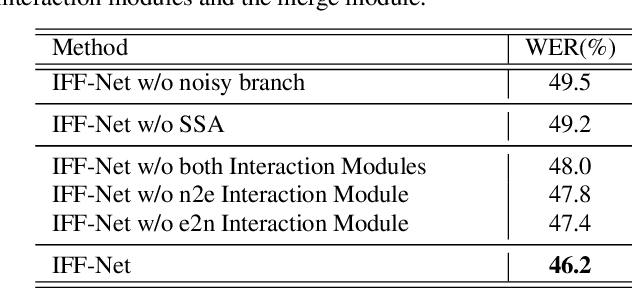
Speech enhancement (SE) aims to suppress the additive noise from a noisy speech signal to improve the speech's perceptual quality and intelligibility. However, the over-suppression phenomenon in the enhanced speech might degrade the performance of downstream automatic speech recognition (ASR) task due to the missing latent information. To alleviate such problem, we propose an interactive feature fusion network (IFF-Net) for noise-robust speech recognition to learn complementary information from the enhanced feature and original noisy feature. Experimental results show that the proposed method achieves absolute word error rate (WER) reduction of 4.1% over the best baseline on RATS Channel-A corpus. Our further analysis indicates that the proposed IFF-Net can complement some missing information in the over-suppressed enhanced feature.
Deformable TDNN with adaptive receptive fields for speech recognition
Apr 30, 2021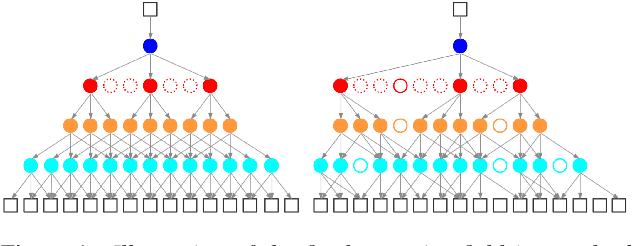
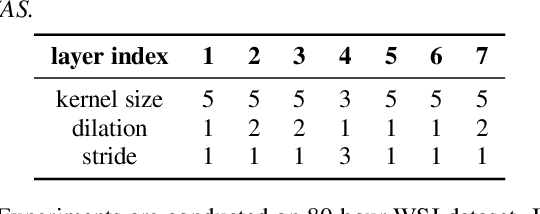
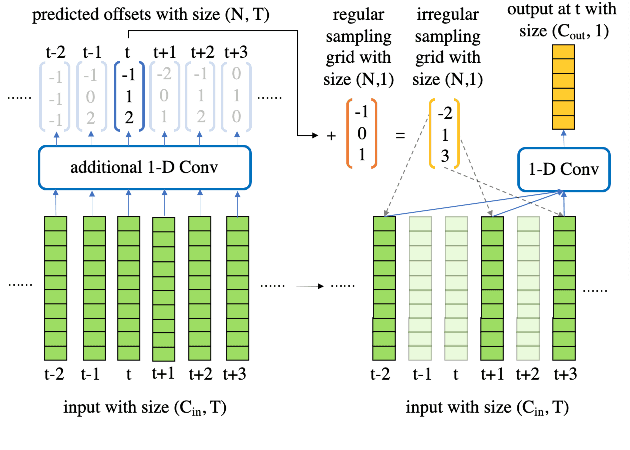
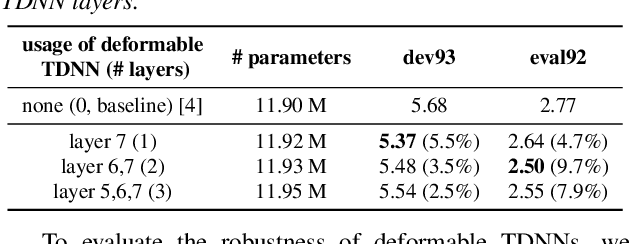
Time Delay Neural Networks (TDNNs) are widely used in both DNN-HMM based hybrid speech recognition systems and recent end-to-end systems. Nevertheless, the receptive fields of TDNNs are limited and fixed, which is not desirable for tasks like speech recognition, where the temporal dynamics of speech are varied and affected by many factors. This paper proposes to use deformable TDNNs for adaptive temporal dynamics modeling in end-to-end speech recognition. Inspired by deformable ConvNets, deformable TDNNs augment the temporal sampling locations with additional offsets and learn the offsets automatically based on the ASR criterion, without additional supervision. Experiments show that deformable TDNNs obtain state-of-the-art results on WSJ benchmarks (1.42\%/3.45\% WER on WSJ eval92/dev93 respectively), outperforming standard TDNNs significantly. Furthermore, we propose the latency control mechanism for deformable TDNNs, which enables deformable TDNNs to do streaming ASR without accuracy degradation.
Tandem Multitask Training of Speaker Diarisation and Speech Recognition for Meeting Transcription
Jul 08, 2022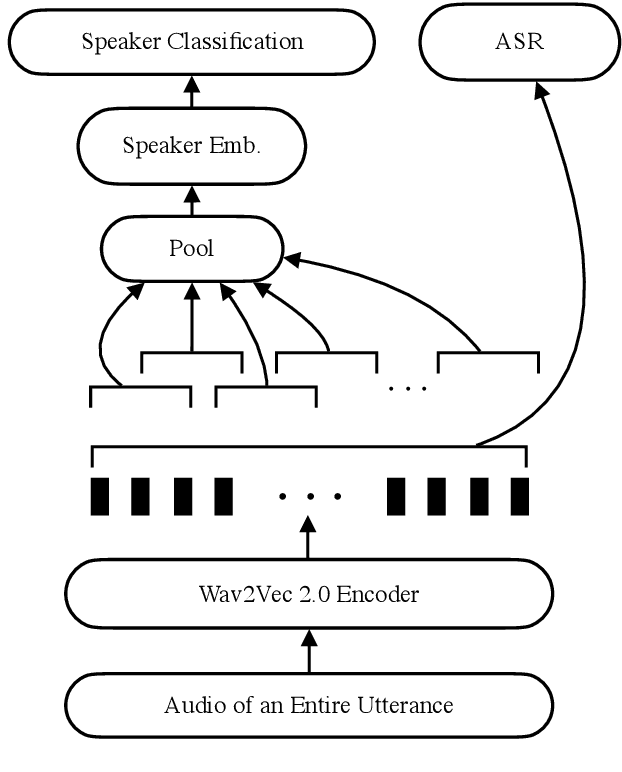
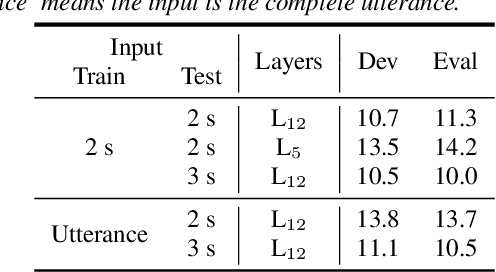
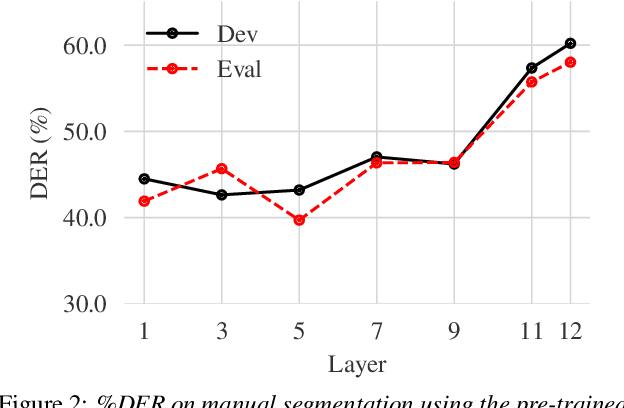
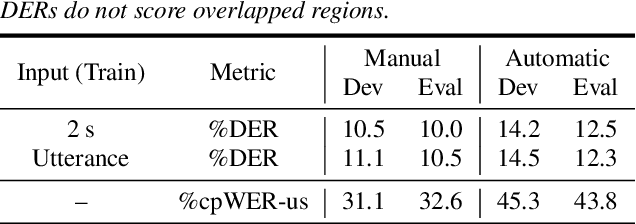
Self-supervised-learning-based pre-trained models for speech data, such as Wav2Vec 2.0 (W2V2), have become the backbone of many speech tasks. In this paper, to achieve speaker diarisation and speech recognition using a single model, a tandem multitask training (TMT) method is proposed to fine-tune W2V2. For speaker diarisation, the tasks of voice activity detection (VAD) and speaker classification (SC) are required, and connectionist temporal classification (CTC) is used for ASR. The multitask framework implements VAD, SC, and ASR using an early layer, middle layer, and late layer of W2V2, which coincides with the order of segmenting the audio with VAD, clustering the segments based on speaker embeddings, and transcribing each segment with ASR. Experimental results on the augmented multi-party (AMI) dataset showed that using different W2V2 layers for VAD, SC, and ASR from the earlier to later layers for TMT not only saves computational cost, but also reduces diarisation error rates (DERs). Joint fine-tuning of VAD, SC, and ASR yielded 16%/17% relative reductions of DER with manual/automatic segmentation respectively, and consistent reductions in speaker attributed word error rate, compared to the baseline with separately fine-tuned models.
Efficient Sequence Transduction by Jointly Predicting Tokens and Durations
Apr 13, 2023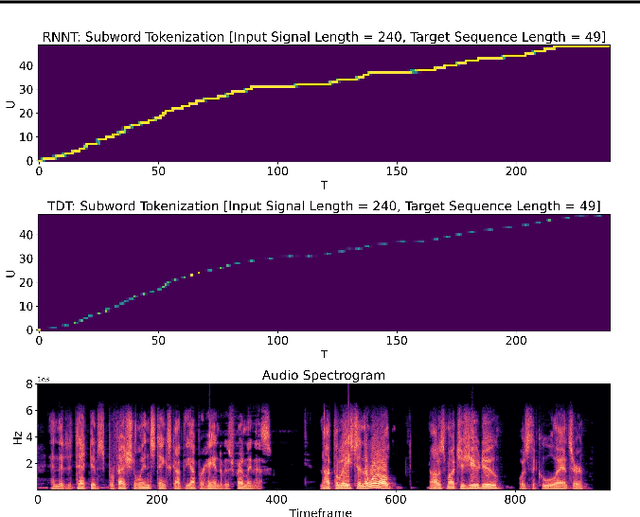
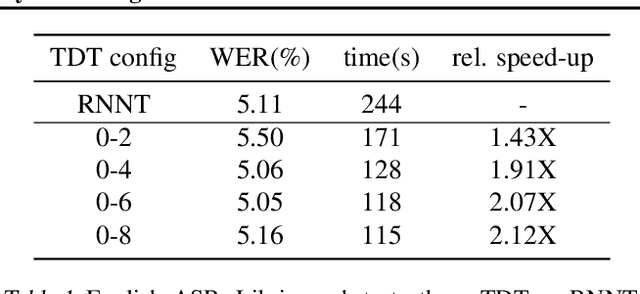
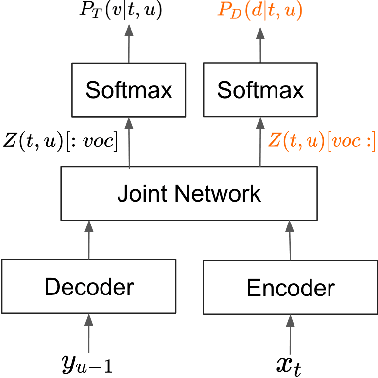
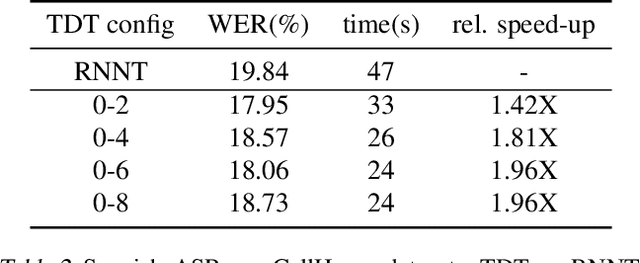
This paper introduces a novel Token-and-Duration Transducer (TDT) architecture for sequence-to-sequence tasks. TDT extends conventional RNN-Transducer architectures by jointly predicting both a token and its duration, i.e. the number of input frames covered by the emitted token. This is achieved by using a joint network with two outputs which are independently normalized to generate distributions over tokens and durations. During inference, TDT models can skip input frames guided by the predicted duration output, which makes them significantly faster than conventional Transducers which process the encoder output frame by frame. TDT models achieve both better accuracy and significantly faster inference than conventional Transducers on different sequence transduction tasks. TDT models for Speech Recognition achieve better accuracy and up to 2.82X faster inference than RNN-Transducers. TDT models for Speech Translation achieve an absolute gain of over 1 BLEU on the MUST-C test compared with conventional Transducers, and its inference is 2.27X faster. In Speech Intent Classification and Slot Filling tasks, TDT models improve the intent accuracy up to over 1% (absolute) over conventional Transducers, while running up to 1.28X faster.
Towards Better Domain Adaptation for Self-supervised Models: A Case Study of Child ASR
Apr 28, 2023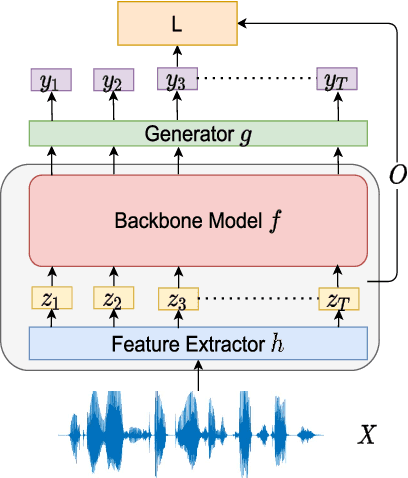
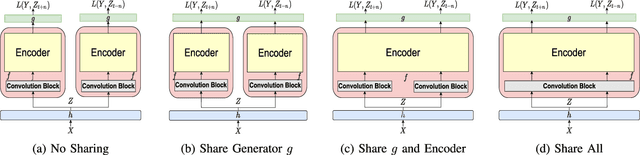
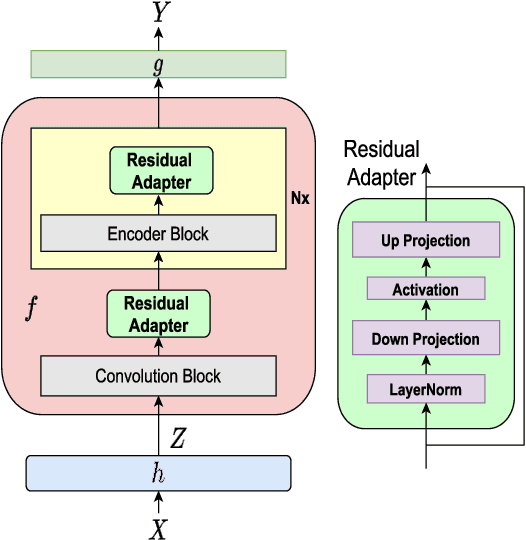
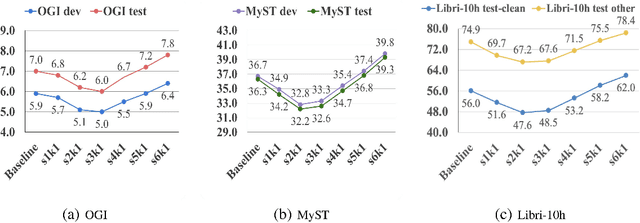
Recently, self-supervised learning (SSL) from unlabelled speech data has gained increased attention in the automatic speech recognition (ASR) community. Typical SSL methods include autoregressive predictive coding (APC), Wav2vec2.0, and hidden unit BERT (HuBERT). However, SSL models are biased to the pretraining data. When SSL models are finetuned with data from another domain, domain shifting occurs and might cause limited knowledge transfer for downstream tasks. In this paper, we propose a novel framework, domain responsible adaptation and finetuning (DRAFT), to reduce domain shifting in pretrained speech models, and evaluate it for a causal and non-causal transformer. For the causal transformer, an extension of APC (E-APC) is proposed to learn richer information from unlabelled data by using multiple temporally-shifted sequences to perform prediction. For the non-causal transformer, various solutions for using the bidirectional APC (Bi-APC) are investigated. In addition, the DRAFT framework is examined for Wav2vec2.0 and HuBERT methods, which use non-causal transformers as the backbone. The experiments are conducted on child ASR (using the OGI and MyST databases) using SSL models trained with unlabelled adult speech data from Librispeech. The relative WER improvements of up to 19.7% on the two child tasks are observed when compared to the pretrained models without adaptation. With the proposed methods (E-APC and DRAFT), the relative WER improvements are even larger (30% and 19% on the OGI and MyST data, respectively) when compared to the models without using pretraining methods.
Reproducibility is Nothing without Correctness: The Importance of Testing Code in NLP
Mar 31, 2023


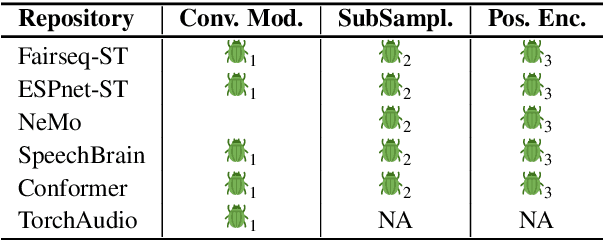
Despite its pivotal role in research experiments, code correctness is often presumed only on the basis of the perceived quality of the results. This comes with the risk of erroneous outcomes and potentially misleading findings. To address this issue, we posit that the current focus on result reproducibility should go hand in hand with the emphasis on coding best practices. We bolster our call to the NLP community by presenting a case study, in which we identify (and correct) three bugs in widely used open-source implementations of the state-of-the-art Conformer architecture. Through comparative experiments on automatic speech recognition and translation in various language settings, we demonstrate that the existence of bugs does not prevent the achievement of good and reproducible results and can lead to incorrect conclusions that potentially misguide future research. In response to this, this study is a call to action toward the adoption of coding best practices aimed at fostering correctness and improving the quality of the developed software.
Mask scalar prediction for improving robust automatic speech recognition
Apr 26, 2022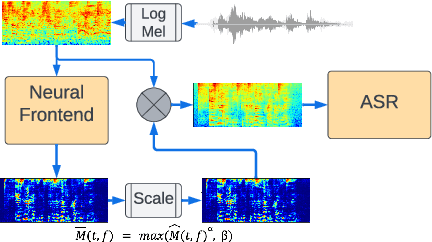
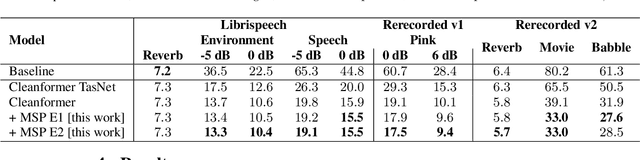
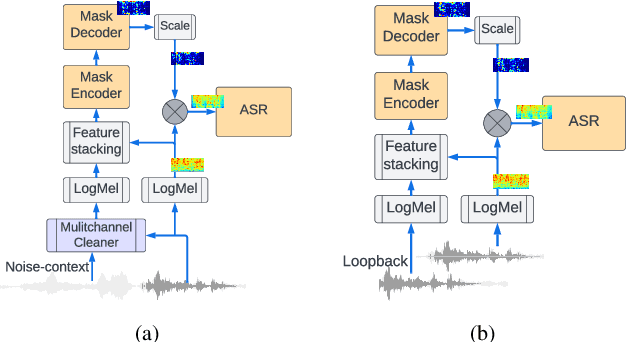
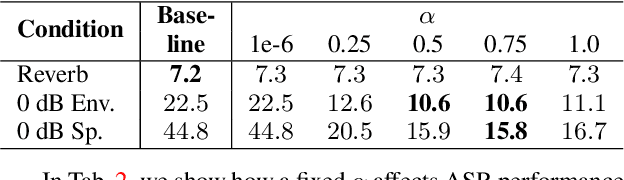
Using neural network based acoustic frontends for improving robustness of streaming automatic speech recognition (ASR) systems is challenging because of the causality constraints and the resulting distortion that the frontend processing introduces in speech. Time-frequency masking based approaches have been shown to work well, but they need additional hyper-parameters to scale the mask to limit speech distortion. Such mask scalars are typically hand-tuned and chosen conservatively. In this work, we present a technique to predict mask scalars using an ASR-based loss in an end-to-end fashion, with minimal increase in the overall model size and complexity. We evaluate the approach on two robust ASR tasks: multichannel enhancement in the presence of speech and non-speech noise, and acoustic echo cancellation (AEC). Results show that the presented algorithm consistently improves word error rate (WER) without the need for any additional tuning over strong baselines that use hand-tuned hyper-parameters: up to 16% for multichannel enhancement in noisy conditions, and up to 7% for AEC.
Unsupervised Speech Enhancement with speech recognition embedding and disentanglement losses
Nov 16, 2021
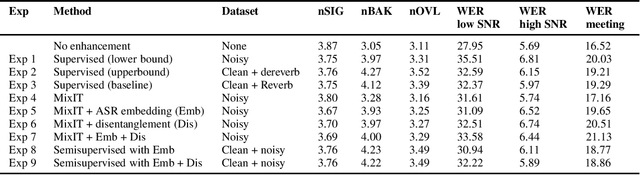
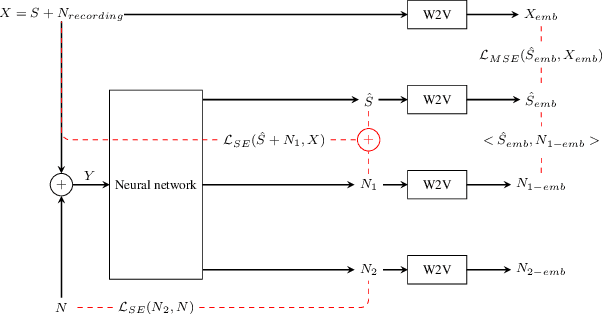
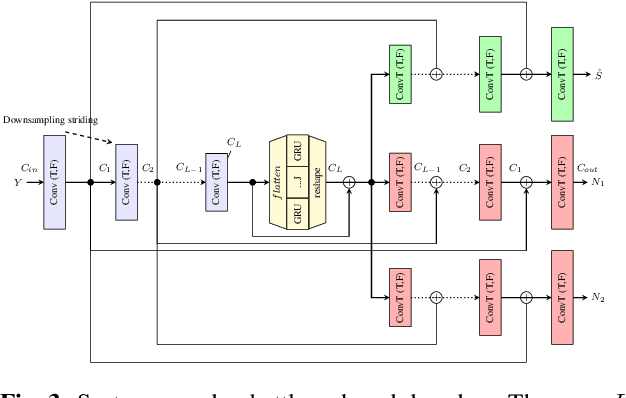
Speech enhancement has recently achieved great success with various deep learning methods. However, most conventional speech enhancement systems are trained with supervised methods that impose two significant challenges. First, a majority of training datasets for speech enhancement systems are synthetic. When mixing clean speech and noisy corpora to create the synthetic datasets, domain mismatches occur between synthetic and real-world recordings of noisy speech or audio. Second, there is a trade-off between increasing speech enhancement performance and degrading speech recognition (ASR) performance. Thus, we propose an unsupervised loss function to tackle those two problems. Our function is developed by extending the MixIT loss function with speech recognition embedding and disentanglement loss. Our results show that the proposed function effectively improves the speech enhancement performance compared to a baseline trained in a supervised way on the noisy VoxCeleb dataset. While fully unsupervised training is unable to exceed the corresponding baseline, with joint super- and unsupervised training, the system is able to achieve similar speech quality and better ASR performance than the best supervised baseline.