 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Applying wav2vec2 for Speech Recognition on Bengali Common Voices Dataset
Sep 11, 2022
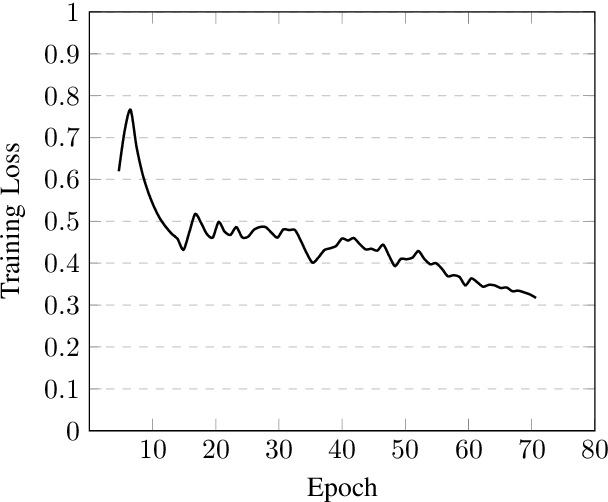
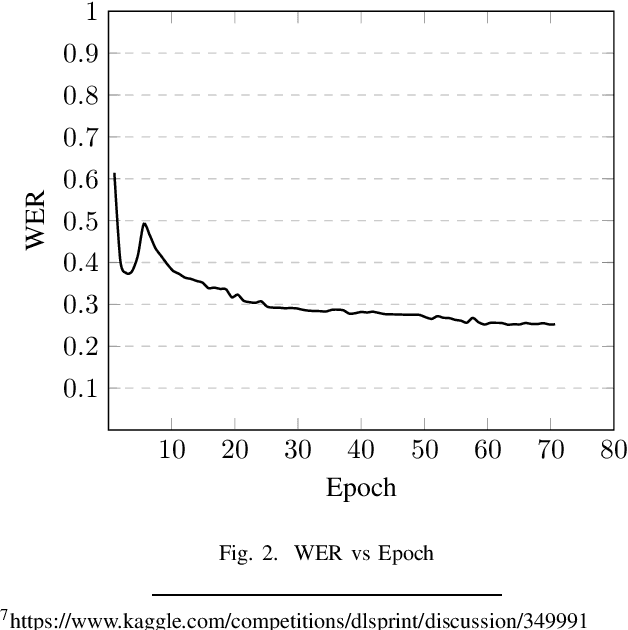

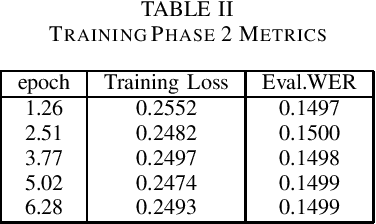
Speech is inherently continuous, where discrete words, phonemes and other units are not clearly segmented, and so speech recognition has been an active research problem for decades. In this work we have fine-tuned wav2vec 2.0 to recognize and transcribe Bengali speech -- training it on the Bengali Common Voice Speech Dataset. After training for 71 epochs, on a training set consisting of 36919 mp3 files, we achieved a training loss of 0.3172 and WER of 0.2524 on a validation set of size 7,747. Using a 5-gram language model, the Levenshtein Distance was 2.6446 on a test set of size 7,747. Then the training set and validation set were combined, shuffled and split into 85-15 ratio. Training for 7 more epochs on this combined dataset yielded an improved Levenshtein Distance of 2.60753 on the test set. Our model was the best performing one, achieving a Levenshtein Distance of 6.234 on a hidden dataset, which was 1.1049 units lower than other competing submissions.
Investigating the Impact of Cross-lingual Acoustic-Phonetic Similarities on Multilingual Speech Recognition
Jul 07, 2022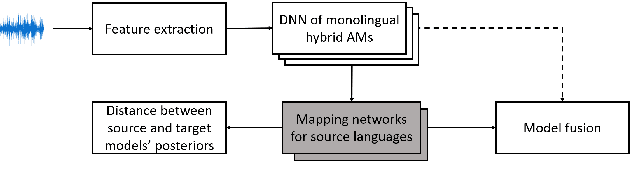
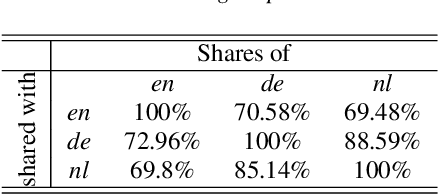

Multilingual automatic speech recognition (ASR) systems mostly benefit low resource languages but suffer degradation in performance across several languages relative to their monolingual counterparts. Limited studies have focused on understanding the languages behaviour in the multilingual speech recognition setups. In this paper, a novel data-driven approach is proposed to investigate the cross-lingual acoustic-phonetic similarities. This technique measures the similarities between posterior distributions from various monolingual acoustic models against a target speech signal. Deep neural networks are trained as mapping networks to transform the distributions from different acoustic models into a directly comparable form. The analysis observes that the languages closeness can not be truly estimated by the volume of overlapping phonemes set. Entropy analysis of the proposed mapping networks exhibits that a language with lesser overlap can be more amenable to cross-lingual transfer, and hence more beneficial in the multilingual setup. Finally, the proposed posterior transformation approach is leveraged to fuse monolingual models for a target language. A relative improvement of ~8% over monolingual counterpart is achieved.
Robustness of Multi-Source MT to Transcription Errors
May 26, 2023
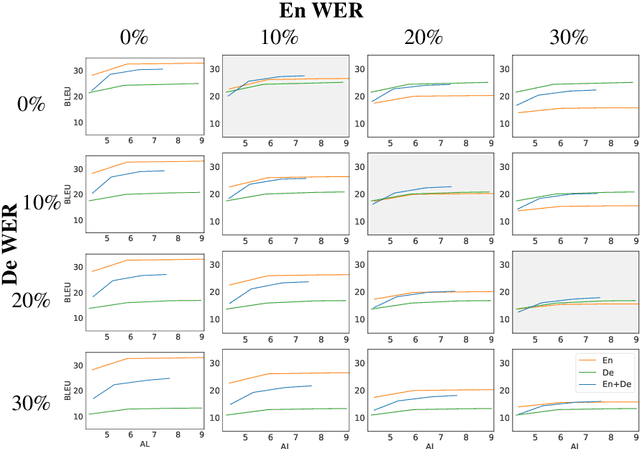

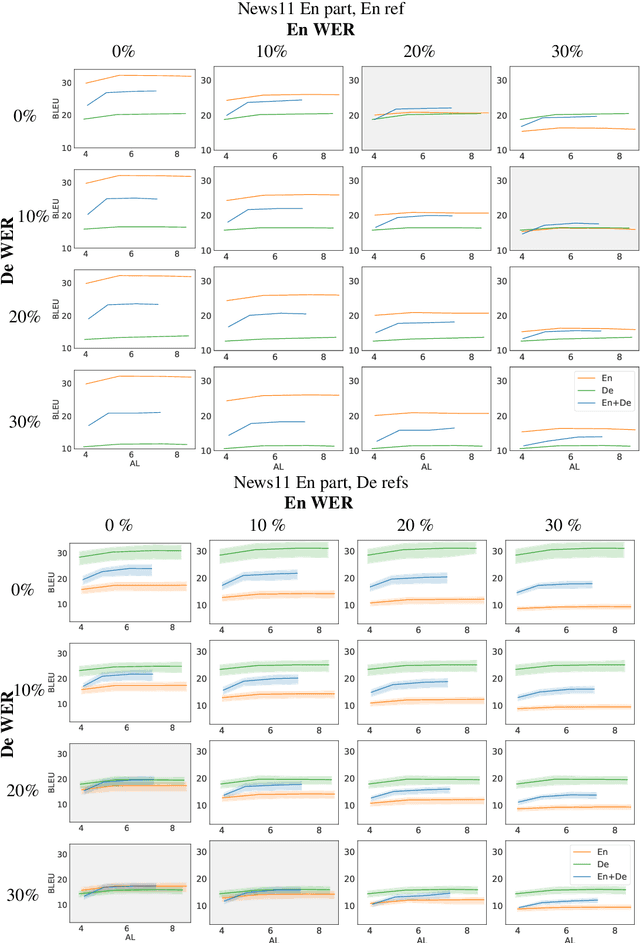
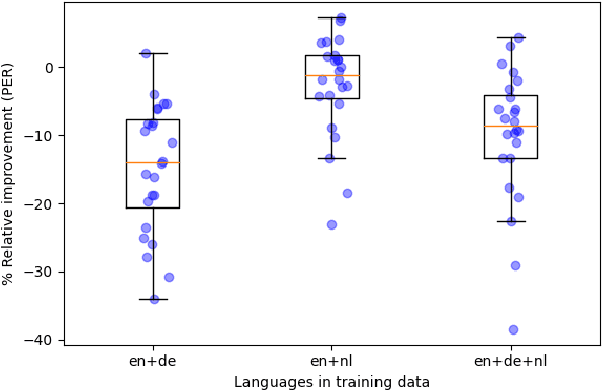
Automatic speech translation is sensitive to speech recognition errors, but in a multilingual scenario, the same content may be available in various languages via simultaneous interpreting, dubbing or subtitling. In this paper, we hypothesize that leveraging multiple sources will improve translation quality if the sources complement one another in terms of correct information they contain. To this end, we first show that on a 10-hour ESIC corpus, the ASR errors in the original English speech and its simultaneous interpreting into German and Czech are mutually independent. We then use two sources, English and German, in a multi-source setting for translation into Czech to establish its robustness to ASR errors. Furthermore, we observe this robustness when translating both noisy sources together in a simultaneous translation setting. Our results show that multi-source neural machine translation has the potential to be useful in a real-time simultaneous translation setting, thereby motivating further investigation in this area.
FusionFormer: Fusing Operations in Transformer for Efficient Streaming Speech Recognition
Oct 31, 2022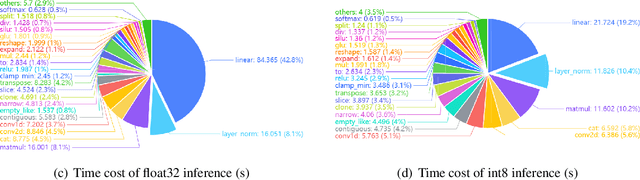

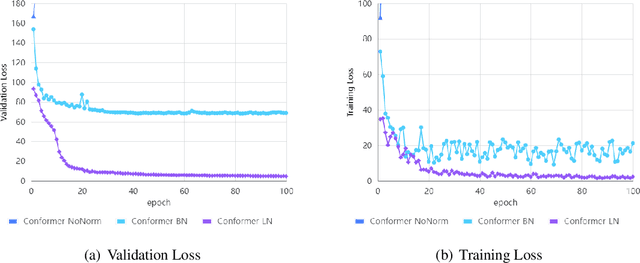
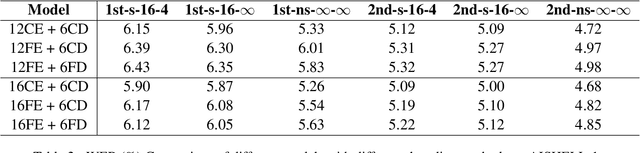
The recently proposed Conformer architecture which combines convolution with attention to capture both local and global dependencies has become the \textit{de facto} backbone model for Automatic Speech Recognition~(ASR). Inherited from the Natural Language Processing (NLP) tasks, the architecture takes Layer Normalization~(LN) as a default normalization technique. However, through a series of systematic studies, we find that LN might take 10\% of the inference time despite that it only contributes to 0.1\% of the FLOPs. This motivates us to replace LN with other normalization techniques, e.g., Batch Normalization~(BN), to speed up inference with the help of operator fusion methods and the avoidance of calculating the mean and variance statistics during inference. After examining several plain attempts which directly remove all LN layers or replace them with BN in the same place, we find that the divergence issue is mainly caused by the unstable layer output. We therefore propose to append a BN layer to each linear or convolution layer where stabilized training results are observed. We also propose to simplify the activations in Conformer, such as Swish and GLU, by replacing them with ReLU. All these exchanged modules can be fused into the weights of the adjacent linear/convolution layers and hence have zero inference cost. Therefore, we name it FusionFormer. Our experiments indicate that FusionFormer is as effective as the LN-based Conformer and is about 10\% faster.
Learning to Jointly Transcribe and Subtitle for End-to-End Spontaneous Speech Recognition
Oct 14, 2022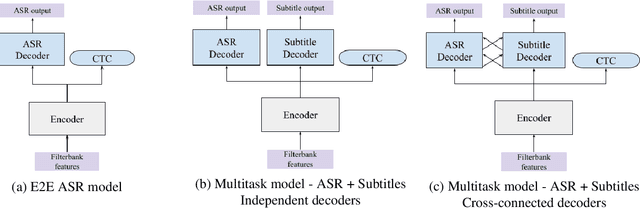
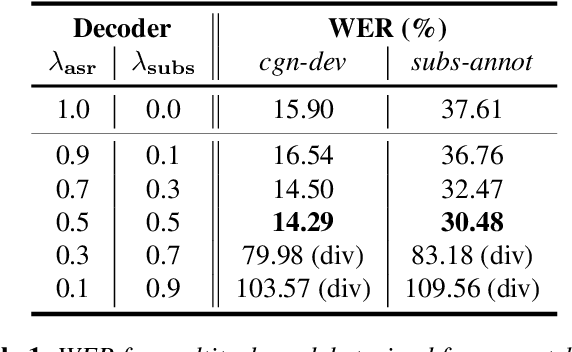

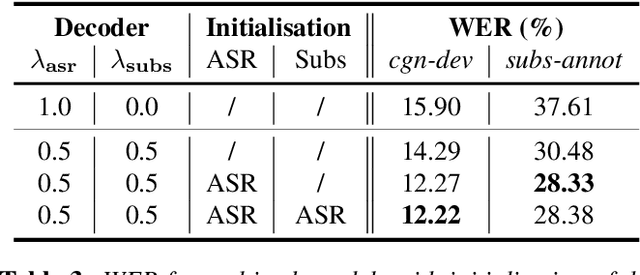
TV subtitles are a rich source of transcriptions of many types of speech, ranging from read speech in news reports to conversational and spontaneous speech in talk shows and soaps. However, subtitles are not verbatim (i.e. exact) transcriptions of speech, so they cannot be used directly to improve an Automatic Speech Recognition (ASR) model. We propose a multitask dual-decoder Transformer model that jointly performs ASR and automatic subtitling. The ASR decoder (possibly pre-trained) predicts the verbatim output and the subtitle decoder generates a subtitle, while sharing the encoder. The two decoders can be independent or connected. The model is trained to perform both tasks jointly, and is able to effectively use subtitle data. We show improvements on regular ASR and on spontaneous and conversational ASR by incorporating the additional subtitle decoder. The method does not require preprocessing (aligning, filtering, pseudo-labeling, ...) of the subtitles.
FonMTL: Towards Multitask Learning for the Fon Language
Aug 28, 2023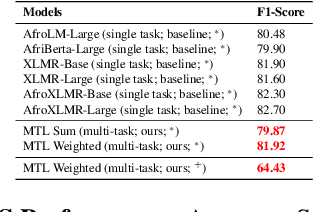
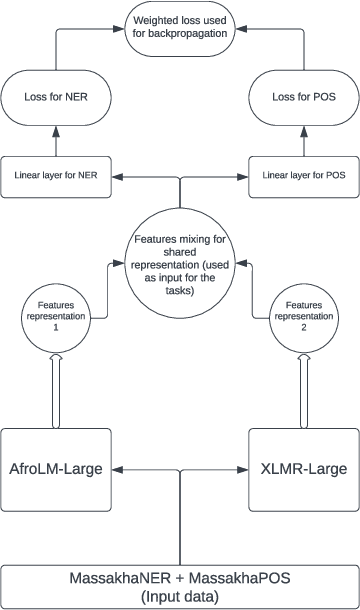
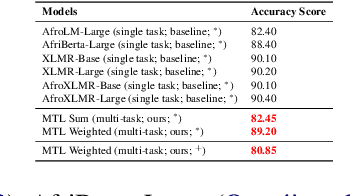
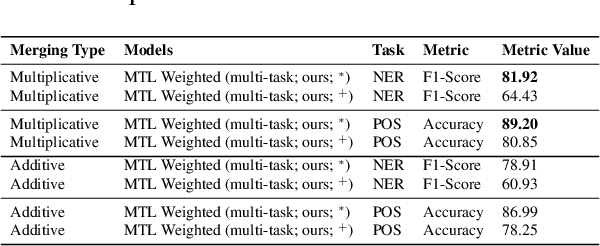
The Fon language, spoken by an average 2 million of people, is a truly low-resourced African language, with a limited online presence, and existing datasets (just to name but a few). Multitask learning is a learning paradigm that aims to improve the generalization capacity of a model by sharing knowledge across different but related tasks: this could be prevalent in very data-scarce scenarios. In this paper, we present the first explorative approach to multitask learning, for model capabilities enhancement in Natural Language Processing for the Fon language. Specifically, we explore the tasks of Named Entity Recognition (NER) and Part of Speech Tagging (POS) for Fon. We leverage two language model heads as encoders to build shared representations for the inputs, and we use linear layers blocks for classification relative to each task. Our results on the NER and POS tasks for Fon, show competitive (or better) performances compared to several multilingual pretrained language models finetuned on single tasks. Additionally, we perform a few ablation studies to leverage the efficiency of two different loss combination strategies and find out that the equal loss weighting approach works best in our case. Our code is open-sourced at https://github.com/bonaventuredossou/multitask_fon.
Approximate Nearest Neighbour Phrase Mining for Contextual Speech Recognition
Apr 18, 2023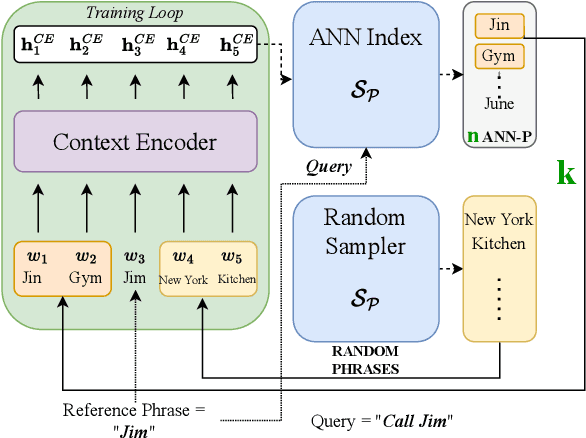
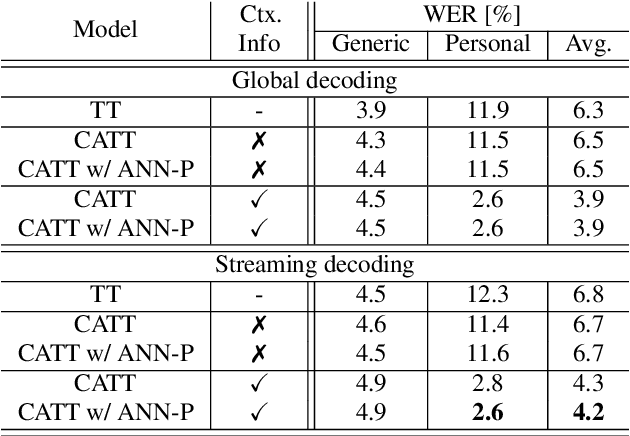
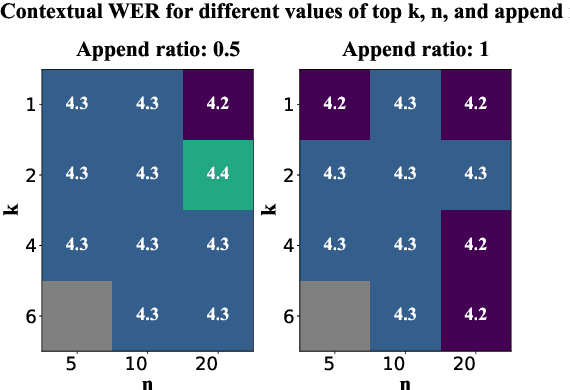

This paper presents an extension to train end-to-end Context-Aware Transformer Transducer ( CATT ) models by using a simple, yet efficient method of mining hard negative phrases from the latent space of the context encoder. During training, given a reference query, we mine a number of similar phrases using approximate nearest neighbour search. These sampled phrases are then used as negative examples in the context list alongside random and ground truth contextual information. By including approximate nearest neighbour phrases (ANN-P) in the context list, we encourage the learned representation to disambiguate between similar, but not identical, biasing phrases. This improves biasing accuracy when there are several similar phrases in the biasing inventory. We carry out experiments in a large-scale data regime obtaining up to 7% relative word error rate reductions for the contextual portion of test data. We also extend and evaluate CATT approach in streaming applications.
Chain-based Discriminative Autoencoders for Speech Recognition
Mar 28, 2022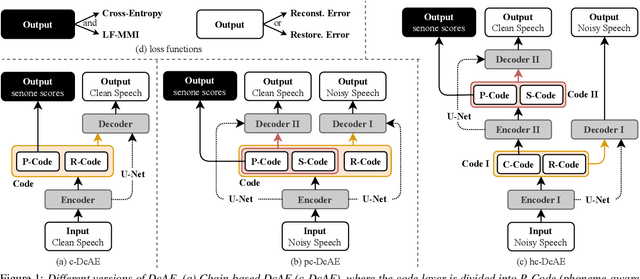
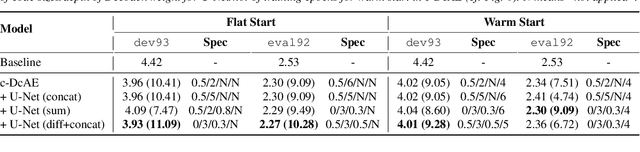
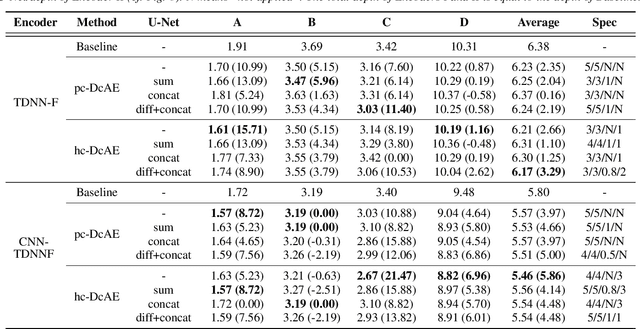
In our previous work, we proposed a discriminative autoencoder (DcAE) for speech recognition. DcAE combines two training schemes into one. First, since DcAE aims to learn encoder-decoder mappings, the squared error between the reconstructed speech and the input speech is minimized. Second, in the code layer, frame-based phonetic embeddings are obtained by minimizing the categorical cross-entropy between ground truth labels and predicted triphone-state scores. DcAE is developed based on the Kaldi toolkit by treating various TDNN models as encoders. In this paper, we further propose three new versions of DcAE. First, a new objective function that considers both categorical cross-entropy and mutual information between ground truth and predicted triphone-state sequences is used. The resulting DcAE is called a chain-based DcAE (c-DcAE). For application to robust speech recognition, we further extend c-DcAE to hierarchical and parallel structures, resulting in hc-DcAE and pc-DcAE. In these two models, both the error between the reconstructed noisy speech and the input noisy speech and the error between the enhanced speech and the reference clean speech are taken into the objective function. Experimental results on the WSJ and Aurora-4 corpora show that our DcAE models outperform baseline systems.
Knowledge Distillation for Neural Transducer-based Target-Speaker ASR: Exploiting Parallel Mixture/Single-Talker Speech Data
May 25, 2023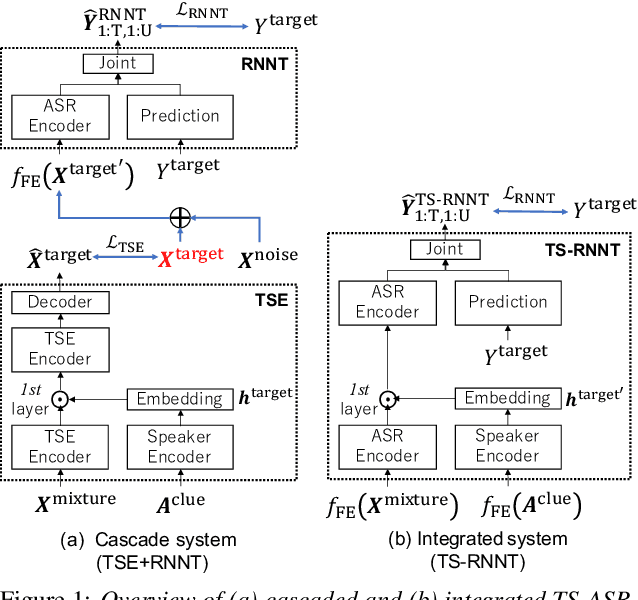

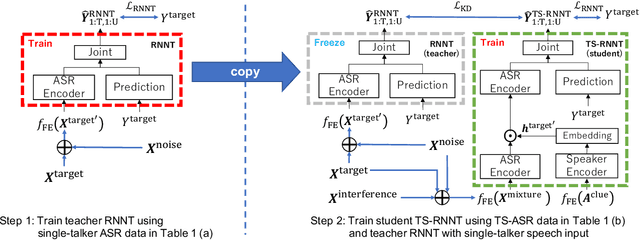
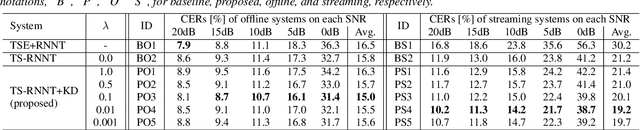
Neural transducer (RNNT)-based target-speaker speech recognition (TS-RNNT) directly transcribes a target speaker's voice from a multi-talker mixture. It is a promising approach for streaming applications because it does not incur the extra computation costs of a target speech extraction frontend, which is a critical barrier to quick response. TS-RNNT is trained end-to-end given the input speech (i.e., mixtures and enrollment speech) and reference transcriptions. The training mixtures are generally simulated by mixing single-talker signals, but conventional TS-RNNT training does not utilize single-speaker signals. This paper proposes using knowledge distillation (KD) to exploit the parallel mixture/single-talker speech data. Our proposed KD scheme uses an RNNT system pretrained with the target single-talker speech input to generate pseudo labels for the TS-RNNT training. Experimental results show that TS-RNNT systems trained with the proposed KD scheme outperform a baseline TS-RNNT.
Svarah: Evaluating English ASR Systems on Indian Accents
May 25, 2023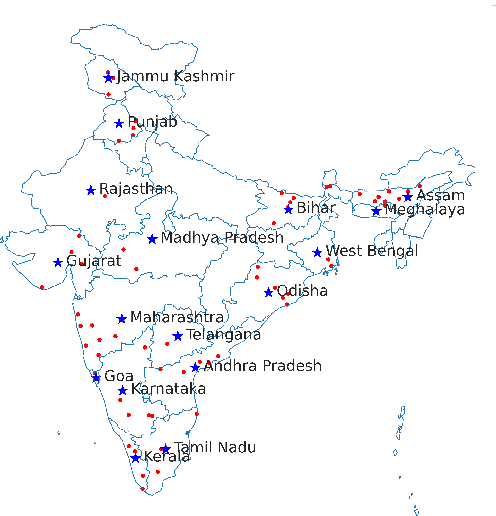
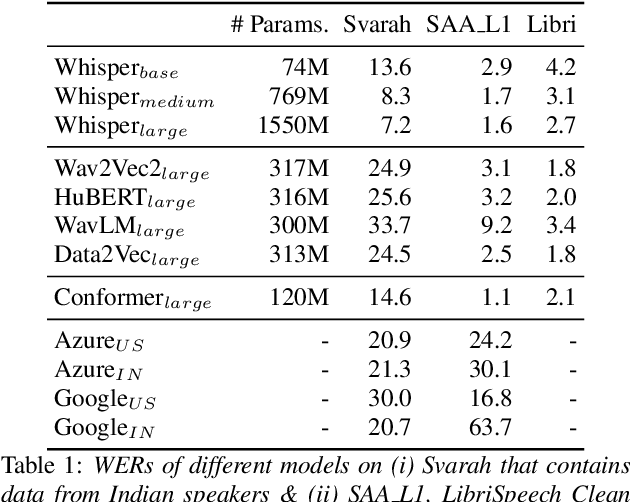
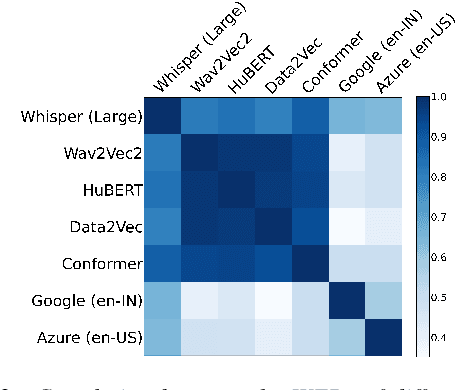
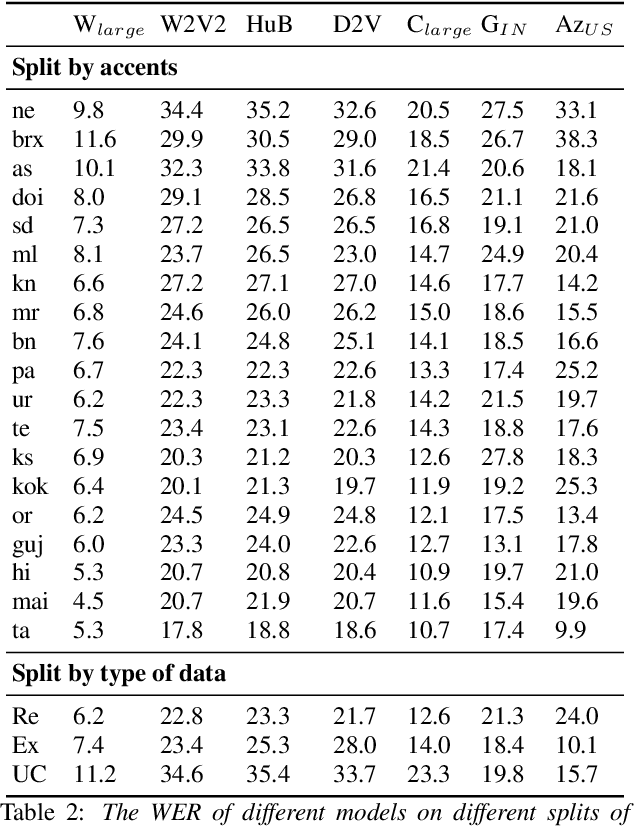
India is the second largest English-speaking country in the world with a speaker base of roughly 130 million. Thus, it is imperative that automatic speech recognition (ASR) systems for English should be evaluated on Indian accents. Unfortunately, Indian speakers find a very poor representation in existing English ASR benchmarks such as LibriSpeech, Switchboard, Speech Accent Archive, etc. In this work, we address this gap by creating Svarah, a benchmark that contains 9.6 hours of transcribed English audio from 117 speakers across 65 geographic locations throughout India, resulting in a diverse range of accents. Svarah comprises both read speech and spontaneous conversational data, covering various domains, such as history, culture, tourism, etc., ensuring a diverse vocabulary. We evaluate 6 open source ASR models and 2 commercial ASR systems on Svarah and show that there is clear scope for improvement on Indian accents. Svarah as well as all our code will be publicly available.