 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Human-Imperceptible Identification with Learnable Lensless Imaging
Feb 04, 2023
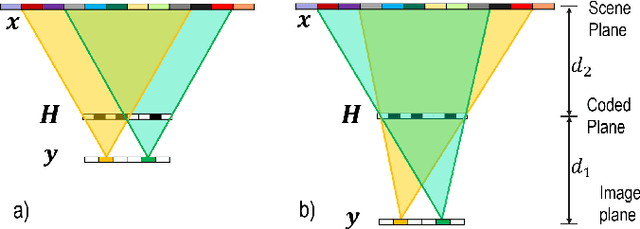



Lensless imaging protects visual privacy by capturing heavily blurred images that are imperceptible for humans to recognize the subject but contain enough information for machines to infer information. Unfortunately, protecting visual privacy comes with a reduction in recognition accuracy and vice versa. We propose a learnable lensless imaging framework that protects visual privacy while maintaining recognition accuracy. To make captured images imperceptible to humans, we designed several loss functions based on total variation, invertibility, and the restricted isometry property. We studied the effect of privacy protection with blurriness on the identification of personal identity via a quantitative method based on a subjective evaluation. Moreover, we validate our simulation by implementing a hardware realization of lensless imaging with photo-lithographically printed masks.
CLIP for All Things Zero-Shot Sketch-Based Image Retrieval, Fine-Grained or Not
Mar 28, 2023
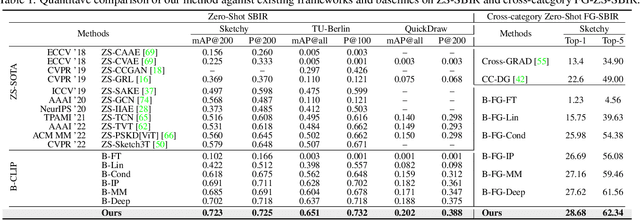

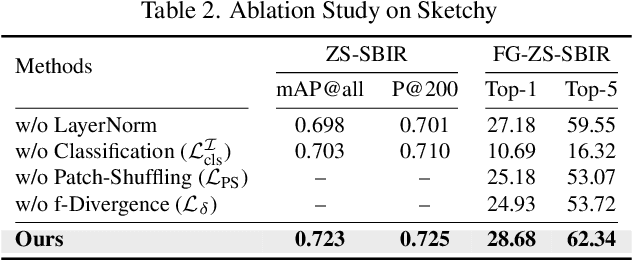
In this paper, we leverage CLIP for zero-shot sketch based image retrieval (ZS-SBIR). We are largely inspired by recent advances on foundation models and the unparalleled generalisation ability they seem to offer, but for the first time tailor it to benefit the sketch community. We put forward novel designs on how best to achieve this synergy, for both the category setting and the fine-grained setting ("all"). At the very core of our solution is a prompt learning setup. First we show just via factoring in sketch-specific prompts, we already have a category-level ZS-SBIR system that overshoots all prior arts, by a large margin (24.8%) - a great testimony on studying the CLIP and ZS-SBIR synergy. Moving onto the fine-grained setup is however trickier, and requires a deeper dive into this synergy. For that, we come up with two specific designs to tackle the fine-grained matching nature of the problem: (i) an additional regularisation loss to ensure the relative separation between sketches and photos is uniform across categories, which is not the case for the gold standard standalone triplet loss, and (ii) a clever patch shuffling technique to help establishing instance-level structural correspondences between sketch-photo pairs. With these designs, we again observe significant performance gains in the region of 26.9% over previous state-of-the-art. The take-home message, if any, is the proposed CLIP and prompt learning paradigm carries great promise in tackling other sketch-related tasks (not limited to ZS-SBIR) where data scarcity remains a great challenge. Project page: https://aneeshan95.github.io/Sketch_LVM/
Spawrious: A Benchmark for Fine Control of Spurious Correlation Biases
Mar 09, 2023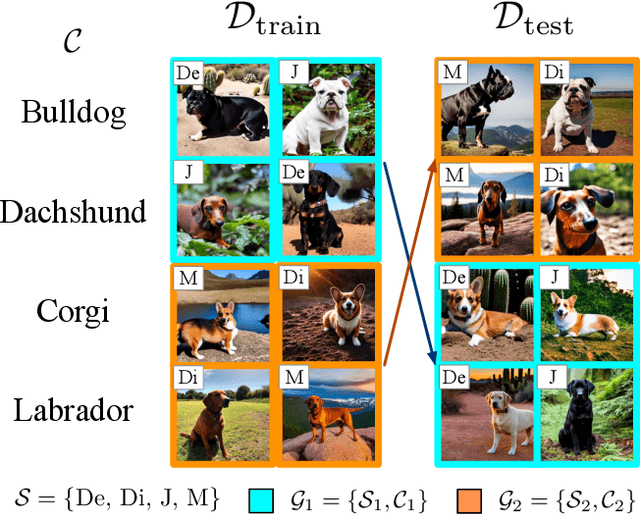
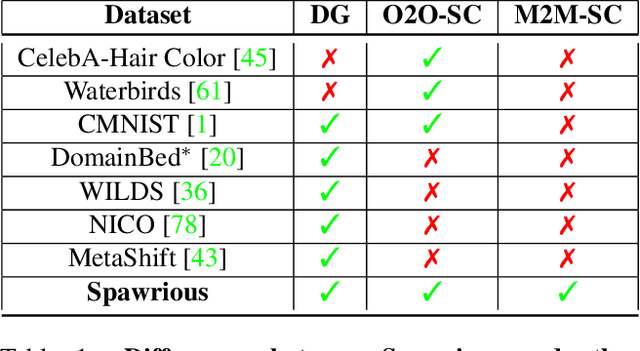

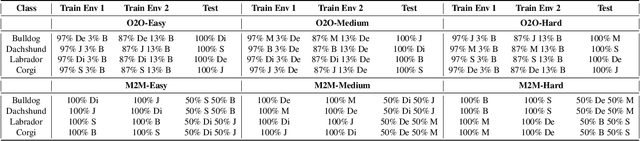
The problem of spurious correlations (SCs) arises when a classifier relies on non-predictive features that happen to be correlated with the labels in the training data. For example, a classifier may misclassify dog breeds based on the background of dog images. This happens when the backgrounds are correlated with other breeds in the training data, leading to misclassifications during test time. Previous SC benchmark datasets suffer from varying issues, e.g., over-saturation or only containing one-to-one (O2O) SCs, but no many-to-many (M2M) SCs arising between groups of spurious attributes and classes. In this paper, we present Spawrious-{O2O, M2M}-{Easy, Medium, Hard}, an image classification benchmark suite containing spurious correlations among different dog breeds and background locations. To create this dataset, we employ a text-to-image model to generate photo-realistic images, and an image captioning model to filter out unsuitable ones. The resulting dataset is of high quality, containing approximately 152,000 images. Our experimental results demonstrate that state-of-the-art group robustness methods struggle with Spawrious, most notably on the Hard-splits with $<60\%$ accuracy. By examining model misclassifications, we detect reliances on spurious backgrounds, demonstrating that our dataset provides a significant challenge to drive future research.
Spring: A High-Resolution High-Detail Dataset and Benchmark for Scene Flow, Optical Flow and Stereo
Mar 03, 2023
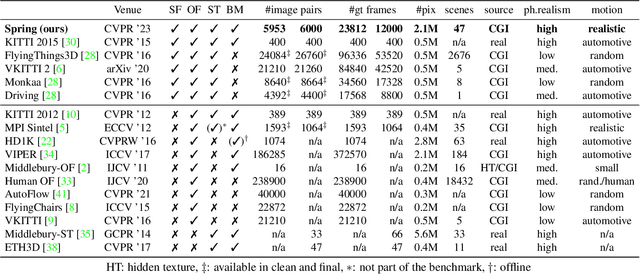

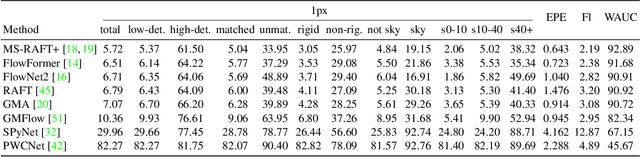
While recent methods for motion and stereo estimation recover an unprecedented amount of details, such highly detailed structures are neither adequately reflected in the data of existing benchmarks nor their evaluation methodology. Hence, we introduce Spring $-$ a large, high-resolution, high-detail, computer-generated benchmark for scene flow, optical flow, and stereo. Based on rendered scenes from the open-source Blender movie "Spring", it provides photo-realistic HD datasets with state-of-the-art visual effects and ground truth training data. Furthermore, we provide a website to upload, analyze and compare results. Using a novel evaluation methodology based on a super-resolved UHD ground truth, our Spring benchmark can assess the quality of fine structures and provides further detailed performance statistics on different image regions. Regarding the number of ground truth frames, Spring is 60$\times$ larger than the only scene flow benchmark, KITTI 2015, and 15$\times$ larger than the well-established MPI Sintel optical flow benchmark. Initial results for recent methods on our benchmark show that estimating fine details is indeed challenging, as their accuracy leaves significant room for improvement. The Spring benchmark and the corresponding datasets are available at http://spring-benchmark.org.
DINet: Deformation Inpainting Network for Realistic Face Visually Dubbing on High Resolution Video
Mar 07, 2023
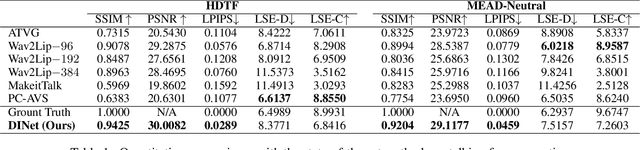
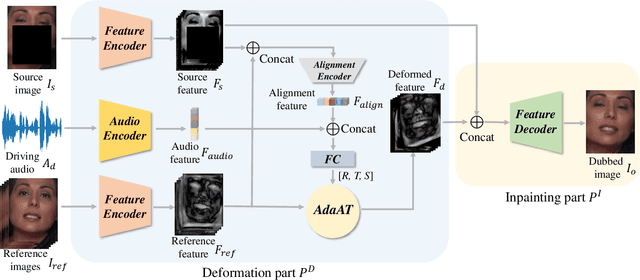
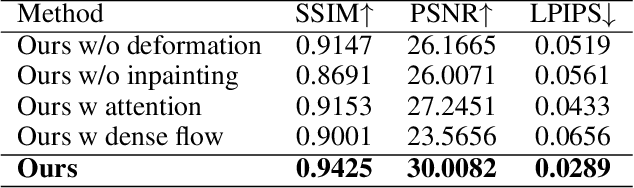
For few-shot learning, it is still a critical challenge to realize photo-realistic face visually dubbing on high-resolution videos. Previous works fail to generate high-fidelity dubbing results. To address the above problem, this paper proposes a Deformation Inpainting Network (DINet) for high-resolution face visually dubbing. Different from previous works relying on multiple up-sample layers to directly generate pixels from latent embeddings, DINet performs spatial deformation on feature maps of reference images to better preserve high-frequency textural details. Specifically, DINet consists of one deformation part and one inpainting part. In the first part, five reference facial images adaptively perform spatial deformation to create deformed feature maps encoding mouth shapes at each frame, in order to align with the input driving audio and also the head poses of the input source images. In the second part, to produce face visually dubbing, a feature decoder is responsible for adaptively incorporating mouth movements from the deformed feature maps and other attributes (i.e., head pose and upper facial expression) from the source feature maps together. Finally, DINet achieves face visually dubbing with rich textural details. We conduct qualitative and quantitative comparisons to validate our DINet on high-resolution videos. The experimental results show that our method outperforms state-of-the-art works.
Lifetime-configurable soft robots via photodegradable silicone elastomer composites
Feb 28, 2023Developing soft robots that can control their own life-cycle and degrade on-demand while maintaining hyper-elasticity is a significant research challenge. On-demand degradable soft robots, which conserve their original functionality during operation and rapidly degrade under specific external stimulation, present the opportunity to self-direct the disappearance of temporary robots. This study proposes soft robots and materials that exhibit excellent mechanical stretchability and can degrade under ultraviolet (UV) light by mixing a fluoride-generating diphenyliodonium hexafluorophosphate (DPI-HFP) with a silicone resin. Spectroscopic analysis revealed the mechanism of Si-O-Si backbone cleavage using fluoride ion (F-), which was generated from UV exposed DPI-HFP. Furthermore, photo-differential scanning calorimetry (DSC) based thermal analysis indicated increased decomposition kinetics at increased temperatures. Additionally, we demonstrated a robotics application of this composite by fabricating a gaiting robot. The integration of soft electronics, including strain sensors, temperature sensors, and photodetectors, expanded the robotic functionalities. This study provides a simple yet novel strategy for designing lifecycle mimicking soft robotics that can be applied to reduce soft robotics waste, explore hazardous areas where retrieval of robots is impossible, and ensure hardware security with on-demand destructive material platforms.
Make Your Brief Stroke Real and Stereoscopic: 3D-Aware Simplified Sketch to Portrait Generation
Feb 14, 2023
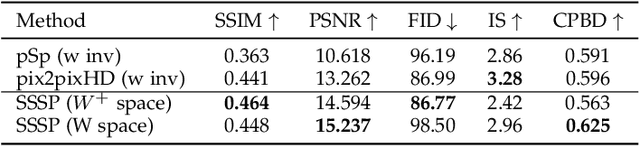
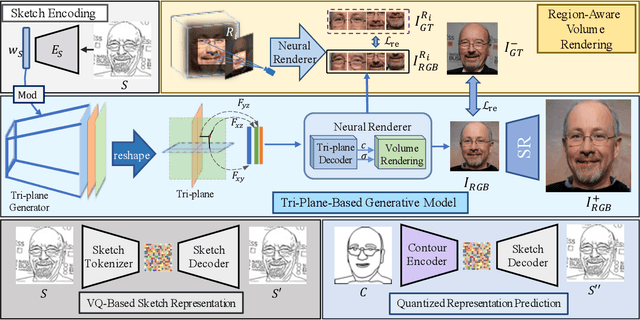

Creating the photo-realistic version of people sketched portraits is useful to various entertainment purposes. Existing studies only generate portraits in the 2D plane with fixed views, making the results less vivid. In this paper, we present Stereoscopic Simplified Sketch-to-Portrait (SSSP), which explores the possibility of creating Stereoscopic 3D-aware portraits from simple contour sketches by involving 3D generative models. Our key insight is to design sketch-aware constraints that can fully exploit the prior knowledge of a tri-plane-based 3D-aware generative model. Specifically, our designed region-aware volume rendering strategy and global consistency constraint further enhance detail correspondences during sketch encoding. Moreover, in order to facilitate the usage of layman users, we propose a Contour-to-Sketch module with vector quantized representations, so that easily drawn contours can directly guide the generation of 3D portraits. Extensive comparisons show that our method generates high-quality results that match the sketch. Our usability study verifies that our system is greatly preferred by user.
Artificial Intelligence Generated Coins for Size Comparison
Jan 11, 2023


Authors of scientific articles use coins in photographs as a size reference for objects. For this purpose, coins are placed next to objects when taking the photo. In this letter we propose a novel method that uses artificial intelligence (AI) generated images of coins to provide a size reference in photos. The newest generation is able to quickly generate realistic high-quality images from textual descriptions. With the proposed method no physical coin is required while taking photos. Coins can be added to photos that contain none. Furthermore, we show how the coin motif can be matched to the object.
EXIF as Language: Learning Cross-Modal Associations Between Images and Camera Metadata
Jan 11, 2023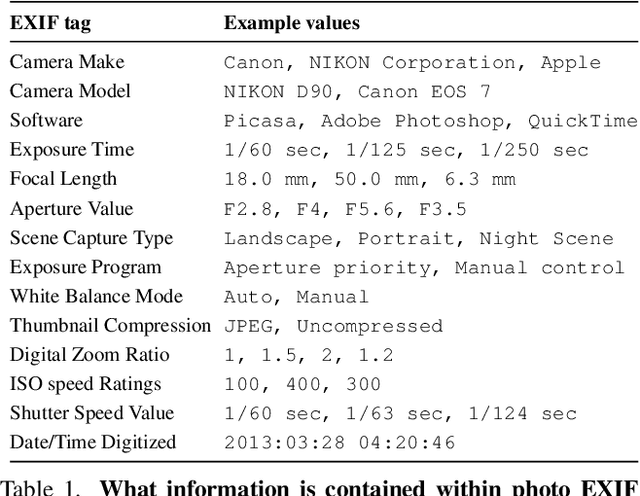
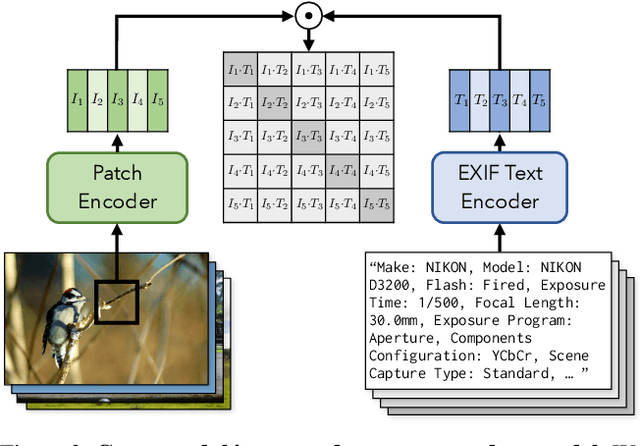
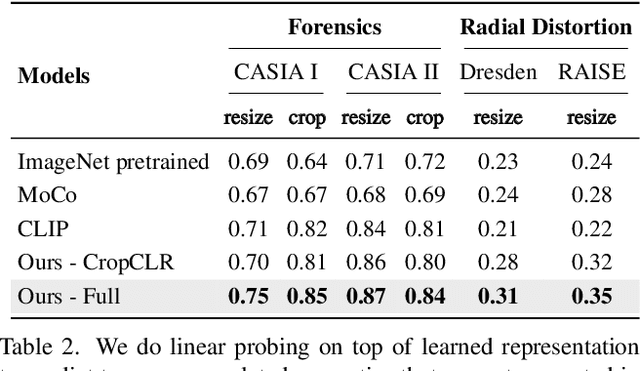
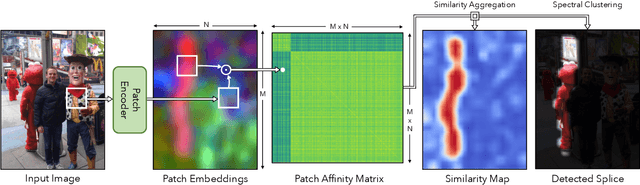
We learn a visual representation that captures information about the camera that recorded a given photo. To do this, we train a multimodal embedding between image patches and the EXIF metadata that cameras automatically insert into image files. Our model represents this metadata by simply converting it to text and then processing it with a transformer. The features that we learn significantly outperform other self-supervised and supervised features on downstream image forensics and calibration tasks. In particular, we successfully localize spliced image regions "zero shot" by clustering the visual embeddings for all of the patches within an image.