 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
SpotAgent: Grounding Visual Geo-localization in Large Vision-Language Models through Agentic Reasoning
Feb 11, 2026Large Vision-Language Models (LVLMs) have demonstrated strong reasoning capabilities in geo-localization, yet they often struggle in real-world scenarios where visual cues are sparse, long-tailed, and highly ambiguous. Previous approaches, bound by internal knowledge, often fail to provide verifiable results, yielding confident but ungrounded predictions when faced with confounded evidence. To address these challenges, we propose SpotAgent, a framework that formalizes geo-localization into an agentic reasoning process that leverages expert-level reasoning to synergize visual interpretation with tool-assisted verification. SpotAgent actively explores and verifies visual cues by leveraging external tools (e.g., web search, maps) through a ReAct diagram. We introduce a 3-stage post-training pipeline starting with a Supervised Fine-Tuning (SFT) stage for basic alignment, followed by an Agentic Cold Start phase utilizing high-quality trajectories synthesized via a Multi-Agent framework, aiming to instill tool-calling expertise. Subsequently, the model's reasoning capabilities are refined through Reinforcement Learning. We propose a Spatially-Aware Dynamic Filtering strategy to enhance the efficiency of the RL stage by prioritizing learnable samples based on spatial difficulty. Extensive experiments on standard benchmarks demonstrate that SpotAgent achieves state-of-the-art performance, effectively mitigating hallucinations while delivering precise and verifiable geo-localization.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
Step-Audio: Unified Understanding and Generation in Intelligent Speech Interaction
Feb 18, 2025Real-time speech interaction, serving as a fundamental interface for human-machine collaboration, holds immense potential. However, current open-source models face limitations such as high costs in voice data collection, weakness in dynamic control, and limited intelligence. To address these challenges, this paper introduces Step-Audio, the first production-ready open-source solution. Key contributions include: 1) a 130B-parameter unified speech-text multi-modal model that achieves unified understanding and generation, with the Step-Audio-Chat version open-sourced; 2) a generative speech data engine that establishes an affordable voice cloning framework and produces the open-sourced lightweight Step-Audio-TTS-3B model through distillation; 3) an instruction-driven fine control system enabling dynamic adjustments across dialects, emotions, singing, and RAP; 4) an enhanced cognitive architecture augmented with tool calling and role-playing abilities to manage complex tasks effectively. Based on our new StepEval-Audio-360 evaluation benchmark, Step-Audio achieves state-of-the-art performance in human evaluations, especially in terms of instruction following. On open-source benchmarks like LLaMA Question, shows 9.3% average performance improvement, demonstrating our commitment to advancing the development of open-source multi-modal language technologies. Our code and models are available at https://github.com/stepfun-ai/Step-Audio.
MusicFace: Music-driven Expressive Singing Face Synthesis
Mar 24, 2023It is still an interesting and challenging problem to synthesize a vivid and realistic singing face driven by music signal. In this paper, we present a method for this task with natural motions of the lip, facial expression, head pose, and eye states. Due to the coupling of the mixed information of human voice and background music in common signals of music audio, we design a decouple-and-fuse strategy to tackle the challenge. We first decompose the input music audio into human voice stream and background music stream. Due to the implicit and complicated correlation between the two-stream input signals and the dynamics of the facial expressions, head motions and eye states, we model their relationship with an attention scheme, where the effects of the two streams are fused seamlessly. Furthermore, to improve the expressiveness of the generated results, we propose to decompose head movements generation into speed generation and direction generation, and decompose eye states generation into the short-time eye blinking generation and the long-time eye closing generation to model them separately. We also build a novel SingingFace Dataset to support the training and evaluation of this task, and to facilitate future works on this topic. Extensive experiments and user study show that our proposed method is capable of synthesizing vivid singing face, which is better than state-of-the-art methods qualitatively and quantitatively.
DINet: Deformation Inpainting Network for Realistic Face Visually Dubbing on High Resolution Video
Mar 07, 2023



For few-shot learning, it is still a critical challenge to realize photo-realistic face visually dubbing on high-resolution videos. Previous works fail to generate high-fidelity dubbing results. To address the above problem, this paper proposes a Deformation Inpainting Network (DINet) for high-resolution face visually dubbing. Different from previous works relying on multiple up-sample layers to directly generate pixels from latent embeddings, DINet performs spatial deformation on feature maps of reference images to better preserve high-frequency textural details. Specifically, DINet consists of one deformation part and one inpainting part. In the first part, five reference facial images adaptively perform spatial deformation to create deformed feature maps encoding mouth shapes at each frame, in order to align with the input driving audio and also the head poses of the input source images. In the second part, to produce face visually dubbing, a feature decoder is responsible for adaptively incorporating mouth movements from the deformed feature maps and other attributes (i.e., head pose and upper facial expression) from the source feature maps together. Finally, DINet achieves face visually dubbing with rich textural details. We conduct qualitative and quantitative comparisons to validate our DINet on high-resolution videos. The experimental results show that our method outperforms state-of-the-art works.
I^2R-Net: Intra- and Inter-Human Relation Network for Multi-Person Pose Estimation
Jun 27, 2022
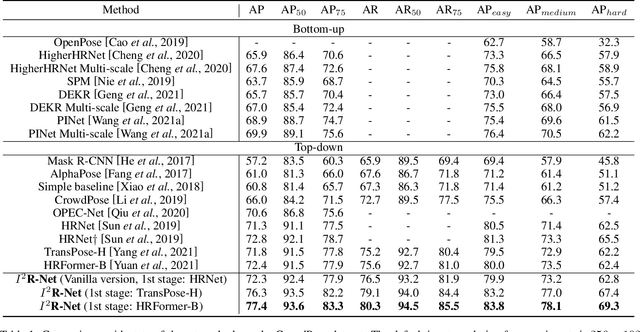
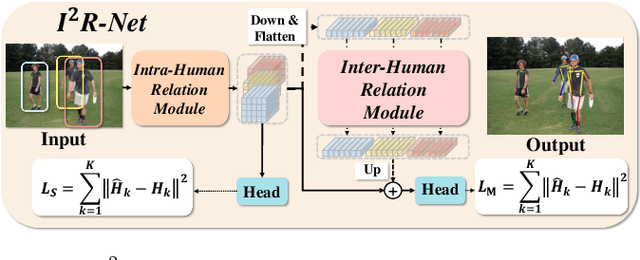
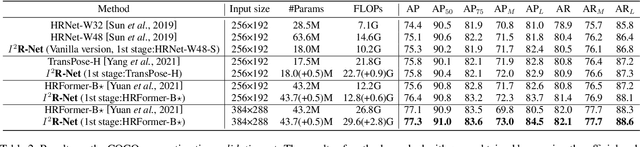
In this paper, we present the Intra- and Inter-Human Relation Networks (I^2R-Net) for Multi-Person Pose Estimation. It involves two basic modules. First, the Intra-Human Relation Module operates on a single person and aims to capture Intra-Human dependencies. Second, the Inter-Human Relation Module considers the relation between multiple instances and focuses on capturing Inter-Human interactions. The Inter-Human Relation Module can be designed very lightweight by reducing the resolution of feature map, yet learn useful relation information to significantly boost the performance of the Intra-Human Relation Module. Even without bells and whistles, our method can compete or outperform current competition winners. We conduct extensive experiments on COCO, CrowdPose, and OCHuman datasets. The results demonstrate that the proposed model surpasses all the state-of-the-art methods. Concretely, the proposed method achieves 77.4% AP on CrowPose dataset and 67.8% AP on OCHuman dataset respectively, outperforming existing methods by a large margin. Additionally, the ablation study and visualization analysis also prove the effectiveness of our model.