 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Learning to Compose with Professional Photographs on the Web
Jul 18, 2017

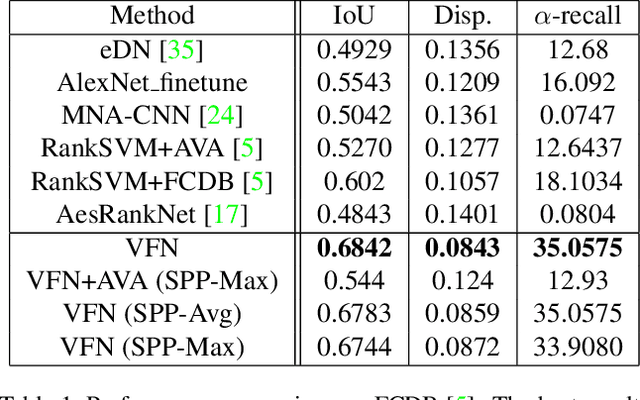

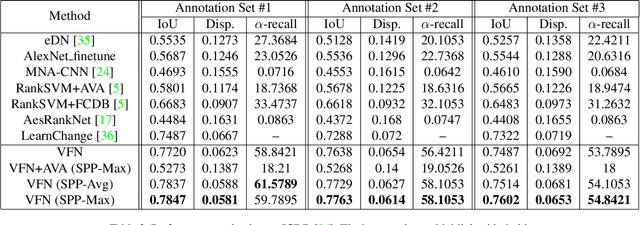
Photo composition is an important factor affecting the aesthetics in photography. However, it is a highly challenging task to model the aesthetic properties of good compositions due to the lack of globally applicable rules to the wide variety of photographic styles. Inspired by the thinking process of photo taking, we formulate the photo composition problem as a view finding process which successively examines pairs of views and determines their aesthetic preferences. We further exploit the rich professional photographs on the web to mine unlimited high-quality ranking samples and demonstrate that an aesthetics-aware deep ranking network can be trained without explicitly modeling any photographic rules. The resulting model is simple and effective in terms of its architectural design and data sampling method. It is also generic since it naturally learns any photographic rules implicitly encoded in professional photographs. The experiments show that the proposed view finding network achieves state-of-the-art performance with sliding window search strategy on two image cropping datasets.
An A* Curriculum Approach to Reinforcement Learning for RGBD Indoor Robot Navigation
Jan 05, 2021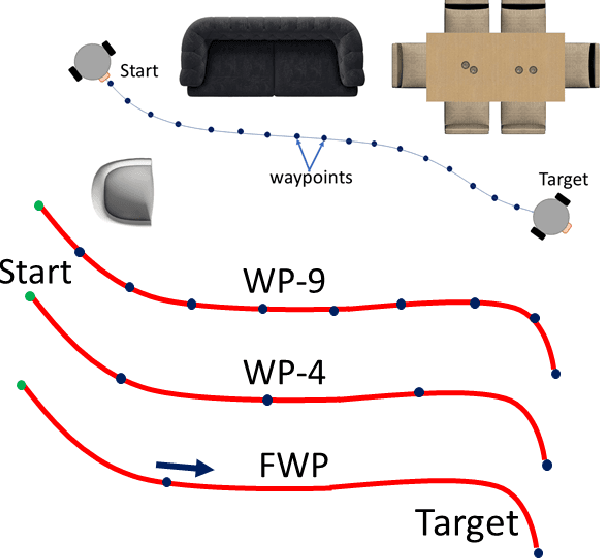
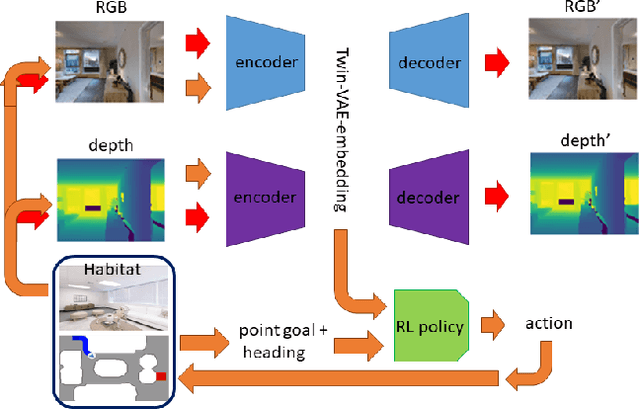
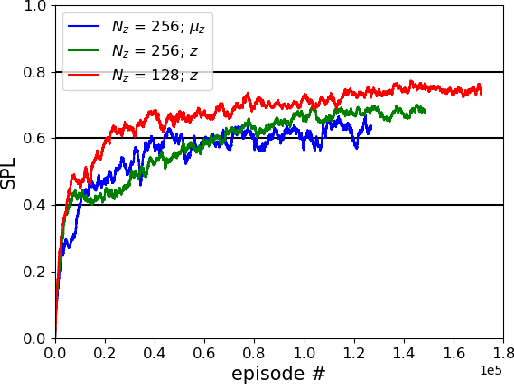
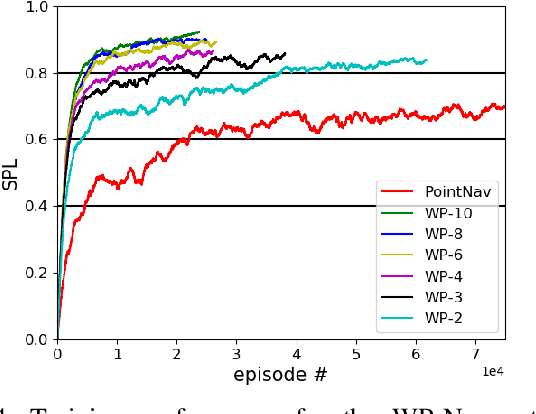
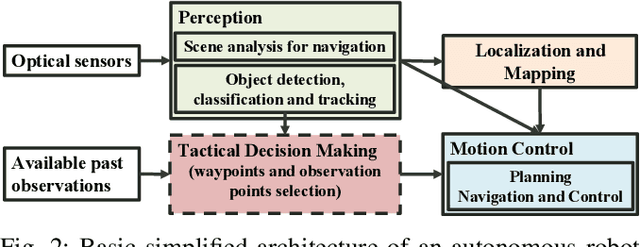
Training robots to navigate diverse environments is a challenging problem as it involves the confluence of several different perception tasks such as mapping and localization, followed by optimal path-planning and control. Recently released photo-realistic simulators such as Habitat allow for the training of networks that output control actions directly from perception: agents use Deep Reinforcement Learning (DRL) to regress directly from the camera image to a control output in an end-to-end fashion. This is data-inefficient and can take several days to train on a GPU. Our paper tries to overcome this problem by separating the training of the perception and control neural nets and increasing the path complexity gradually using a curriculum approach. Specifically, a pre-trained twin Variational AutoEncoder (VAE) is used to compress RGBD (RGB & depth) sensing from an environment into a latent embedding, which is then used to train a DRL-based control policy. A*, a traditional path-planner is used as a guide for the policy and the distance between start and target locations is incrementally increased along the A* route, as training progresses. We demonstrate the efficacy of the proposed approach, both in terms of increased performance and decreased training times for the PointNav task in the Habitat simulation environment. This strategy of improving the training of direct-perception based DRL navigation policies is expected to hasten the deployment of robots of particular interest to industry such as co-bots on the factory floor and last-mile delivery robots.
Extract and Merge: Merging extracted humans from different images utilizing Mask R-CNN
Aug 01, 2019

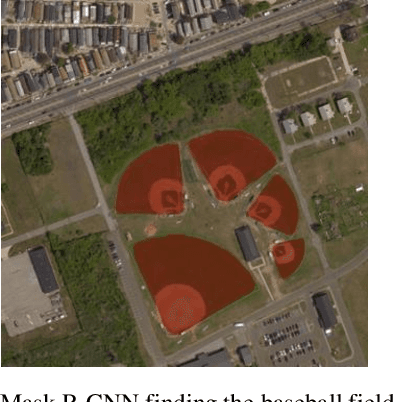

Selecting human objects out of the various type of objects in images and merging them with other scenes is manual and day-to-day work for photo editors. Although recently Adobe photoshop released "select subject" tool which automatically selects the foreground object in an image, but still requires fine manual tweaking separately. In this work, we proposed an application utilizing Mask R-CNN (for object detection and mask segmentation) that can extract human instances from multiple images and merge them with a new background. This application does not add any overhead to Mask R-CNN, running at 5 frames per second. It can extract human instances from any number of images or videos from merging them together. We also structured the code to accept videos of different lengths as input and length of the output-video will be equal to the longest input-video. We wanted to create a simple yet effective application that can serve as a base for photo editing and do most time-consuming work automatically, so, editors can focus more on the design part. Other application could be to group people together in a single picture with a new background from different images which could not be physically together. We are showing single-person and multi-person extraction and placement in two different backgrounds. Also, we are showing a video example with single-person extraction.
Learning to map source code to software vulnerability using code-as-a-graph
Jun 15, 2020

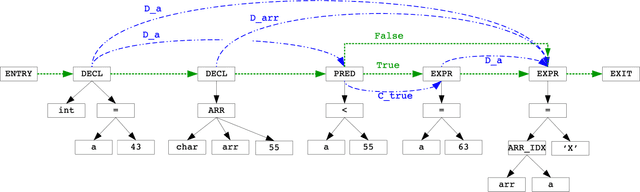
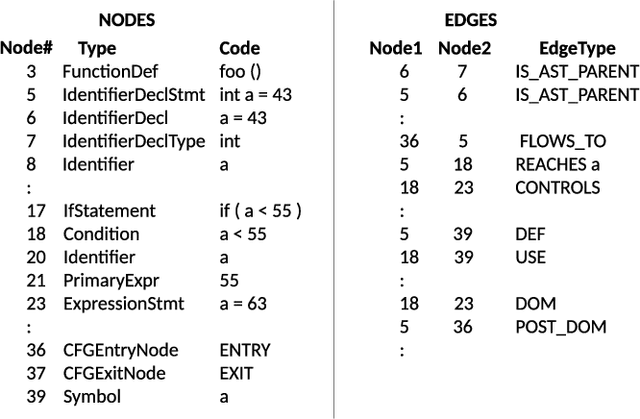
We explore the applicability of Graph Neural Networks in learning the nuances of source code from a security perspective. Specifically, whether signatures of vulnerabilities in source code can be learned from its graph representation, in terms of relationships between nodes and edges. We create a pipeline we call AI4VA, which first encodes a sample source code into a Code Property Graph. The extracted graph is then vectorized in a manner which preserves its semantic information. A Gated Graph Neural Network is then trained using several such graphs to automatically extract templates differentiating the graph of a vulnerable sample from a healthy one. Our model outperforms static analyzers, classic machine learning, as well as CNN and RNN-based deep learning models on two of the three datasets we experiment with. We thus show that a code-as-graph encoding is more meaningful for vulnerability detection than existing code-as-photo and linear sequence encoding approaches. (Submitted Oct 2019, Paper #28, ICST)
High-Fidelity 3D Digital Human Creation from RGB-D Selfies
Oct 12, 2020
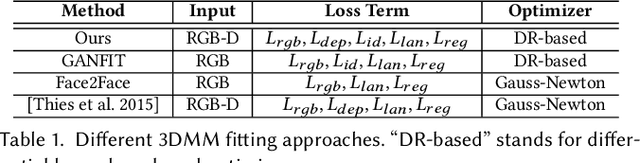
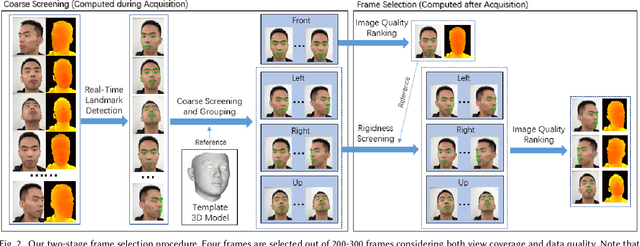

We present a fully automatic system that can produce high-fidelity, photo-realistic 3D digital human characters with a consumer RGB-D selfie camera. The system only needs the user to take a short selfie RGB-D video while rotating his/her head, and can produce a high quality reconstruction in less than 30 seconds. Our main contribution is a new facial geometry modeling and reflectance synthesis procedure that significantly improves the state-of-the-art. Specifically, given the input video a two-stage frame selection algorithm is first employed to select a few high-quality frames for reconstruction. A novel, differentiable renderer based 3D Morphable Model (3DMM) fitting method is then applied to recover facial geometries from multiview RGB-D data, which takes advantages of extensive data generation and perturbation. Our 3DMM has much larger expressive capacities than conventional 3DMM, allowing us to recover more accurate facial geometry using merely linear bases. For reflectance synthesis, we present a hybrid approach that combines parametric fitting and CNNs to synthesize high-resolution albedo/normal maps with realistic hair/pore/wrinkle details. Results show that our system can produce faithful 3D characters with extremely realistic details. Code and the constructed 3DMM is publicly available.
Unselfie: Translating Selfies to Neutral-pose Portraits in the Wild
Jul 29, 2020

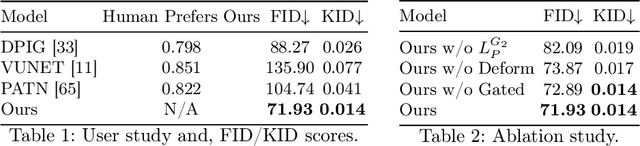
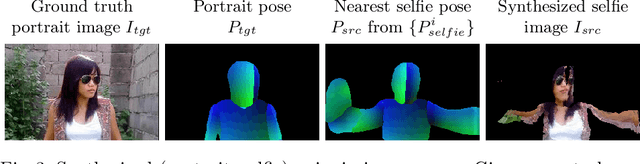
Due to the ubiquity of smartphones, it is popular to take photos of one's self, or "selfies." Such photos are convenient to take, because they do not require specialized equipment or a third-party photographer. However, in selfies, constraints such as human arm length often make the body pose look unnatural. To address this issue, we introduce $\textit{unselfie}$, a novel photographic transformation that automatically translates a selfie into a neutral-pose portrait. To achieve this, we first collect an unpaired dataset, and introduce a way to synthesize paired training data for self-supervised learning. Then, to $\textit{unselfie}$ a photo, we propose a new three-stage pipeline, where we first find a target neutral pose, inpaint the body texture, and finally refine and composite the person on the background. To obtain a suitable target neutral pose, we propose a novel nearest pose search module that makes the reposing task easier and enables the generation of multiple neutral-pose results among which users can choose the best one they like. Qualitative and quantitative evaluations show the superiority of our pipeline over alternatives.
Multi-Agent Active Search using Realistic Depth-Aware Noise Model
Nov 09, 2020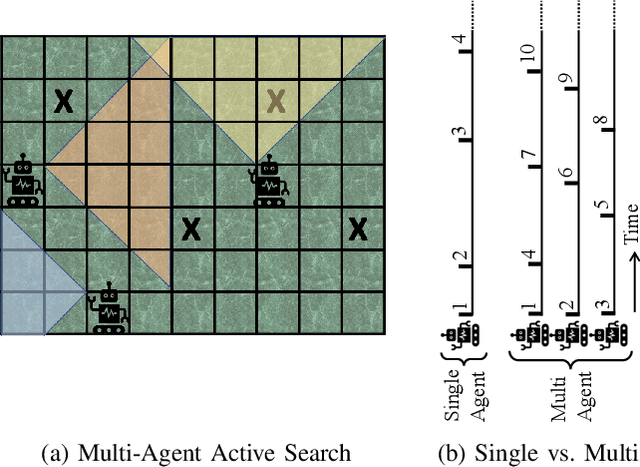
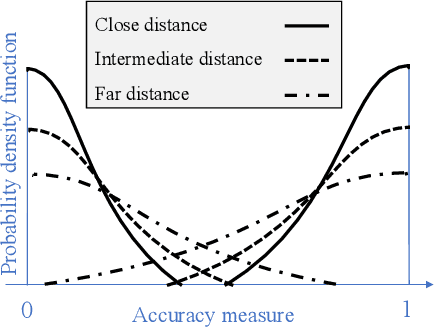
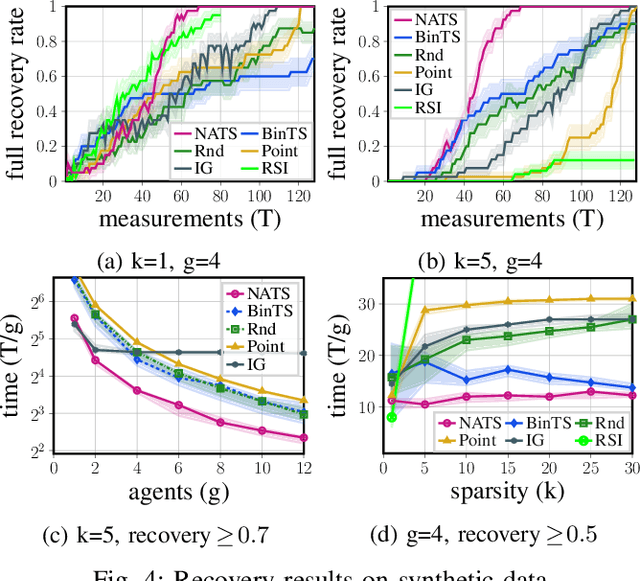
The search for objects of interest in an unknown environment by making data-collection decisions (i.e., active search or active sensing) has robotics applications in many fields, including the search and rescue of human survivors following disasters, detecting gas leaks or locating and preventing animal poachers. Existing algorithms often prioritize the location accuracy of objects of interest while other practical issues such as the reliability of object detection as a function of distance and lines of sight remain largely ignored. An additional challenge is that in many active search scenarios, communication infrastructure may be damaged, unreliable, or unestablished, making centralized control of multiple search agents impractical. We present an algorithm called Noise-Aware Thompson Sampling (NATS) that addresses these issues for multiple ground-based robot agents performing active search considering two sources of sensory information from monocular optical imagery and sonar tracking. NATS utilizes communications between robot agents in a decentralized manner that is robust to intermittent loss of communication links. Additionally, it takes into account object detection uncertainty from depth as well as environmental occlusions. Using simulation results, we show that NATS significantly outperforms existing methods such as information-greedy policies or exhaustive search. We demonstrate the real-world viability of NATS using a photo-realistic environment created in the Unreal Engine 4 game development platform with the AirSim plugin.
Composition-Aware Image Aesthetics Assessment
Jul 25, 2019



Automatic image aesthetics assessment is important for a wide variety of applications such as on-line photo suggestion, photo album management and image retrieval. Previous methods have focused on mapping the holistic image content to a high or low aesthetics rating. However, the composition information of an image characterizes the harmony of its visual elements according to the principles of art, and provides richer information for learning aesthetics. In this work, we propose to model the image composition information as the mutual dependency of its local regions, and design a novel architecture to leverage such information to boost the performance of aesthetics assessment. To achieve this, we densely partition an image into local regions and compute aesthetics-preserving features over the regions to characterize the aesthetics properties of image content. With the feature representation of local regions, we build a region composition graph in which each node denotes one region and any two nodes are connected by an edge weighted by the similarity of the region features. We perform reasoning on this graph via graph convolution, in which the activation of each node is determined by its highly correlated neighbors. Our method naturally uncovers the mutual dependency of local regions in the network training procedure, and achieves the state-of-the-art performance on the benchmark visual aesthetics datasets.
Swapped Face Detection using Deep Learning and Subjective Assessment
Sep 10, 2019


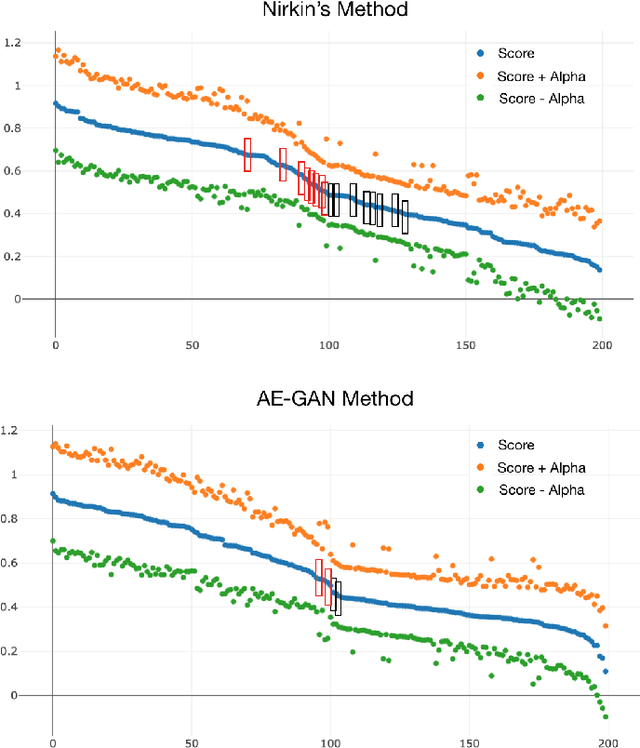
The tremendous success of deep learning for imaging applications has resulted in numerous beneficial advances. Unfortunately, this success has also been a catalyst for malicious uses such as photo-realistic face swapping of parties without consent. Transferring one person's face from a source image to a target image of another person, while keeping the image photo-realistic overall has become increasingly easy and automatic, even for individuals without much knowledge of image processing. In this study, we use deep transfer learning for face swapping detection, showing true positive rates >96% with very few false alarms. Distinguished from existing methods that only provide detection accuracy, we also provide uncertainty for each prediction, which is critical for trust in the deployment of such detection systems. Moreover, we provide a comparison to human subjects. To capture human recognition performance, we build a website to collect pairwise comparisons of images from human subjects. Based on these comparisons, images are ranked from most real to most fake. We compare this ranking to the outputs from our automatic model, showing good, but imperfect, correspondence with linear correlations >0.75. Overall, the results show the effectiveness of our method. As part of this study, we create a novel, publicly available dataset that is, to the best of our knowledge, the largest public swapped face dataset created using still images. Our goal of this study is to inspire more research in the field of image forensics through the creation of a public dataset and initial analysis.
Moiré Photo Restoration Using Multiresolution Convolutional Neural Networks
May 08, 2018

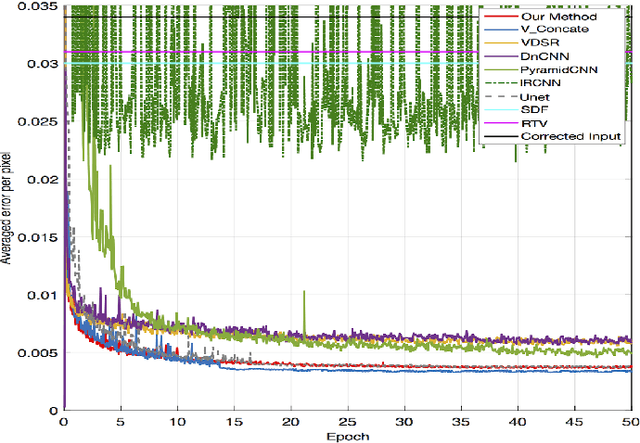

Digital cameras and mobile phones enable us to conveniently record precious moments. While digital image quality is constantly being improved, taking high-quality photos of digital screens still remains challenging because the photos are often contaminated with moir\'{e} patterns, a result of the interference between the pixel grids of the camera sensor and the device screen. Moir\'{e} patterns can severely damage the visual quality of photos. However, few studies have aimed to solve this problem. In this paper, we introduce a novel multiresolution fully convolutional network for automatically removing moir\'{e} patterns from photos. Since a moir\'{e} pattern spans over a wide range of frequencies, our proposed network performs a nonlinear multiresolution analysis of the input image before computing how to cancel moir\'{e} artefacts within every frequency band. We also create a large-scale benchmark dataset with $100,000^+$ image pairs for investigating and evaluating moir\'{e} pattern removal algorithms. Our network achieves state-of-the-art performance on this dataset in comparison to existing learning architectures for image restoration problems.