 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtract and Merge: Merging extracted humans from different images utilizing Mask R-CNN
Aug 01, 2019

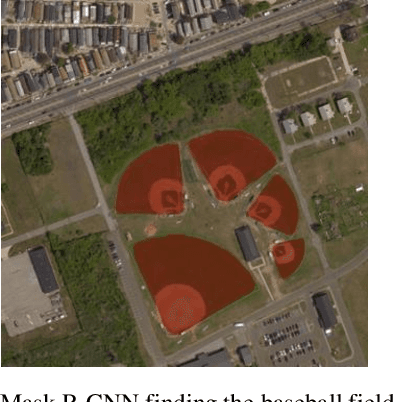

Selecting human objects out of the various type of objects in images and merging them with other scenes is manual and day-to-day work for photo editors. Although recently Adobe photoshop released "select subject" tool which automatically selects the foreground object in an image, but still requires fine manual tweaking separately. In this work, we proposed an application utilizing Mask R-CNN (for object detection and mask segmentation) that can extract human instances from multiple images and merge them with a new background. This application does not add any overhead to Mask R-CNN, running at 5 frames per second. It can extract human instances from any number of images or videos from merging them together. We also structured the code to accept videos of different lengths as input and length of the output-video will be equal to the longest input-video. We wanted to create a simple yet effective application that can serve as a base for photo editing and do most time-consuming work automatically, so, editors can focus more on the design part. Other application could be to group people together in a single picture with a new background from different images which could not be physically together. We are showing single-person and multi-person extraction and placement in two different backgrounds. Also, we are showing a video example with single-person extraction.
Human Extraction and Scene Transition utilizing Mask R-CNN
Jul 20, 2019
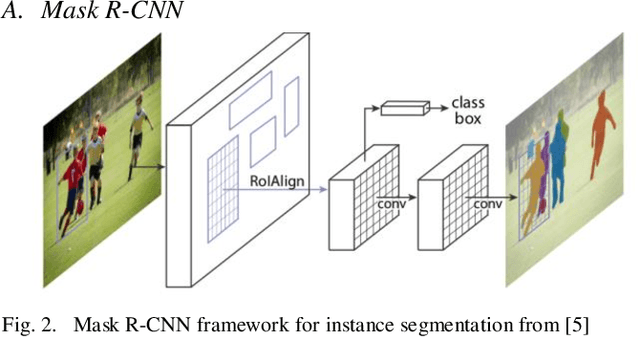

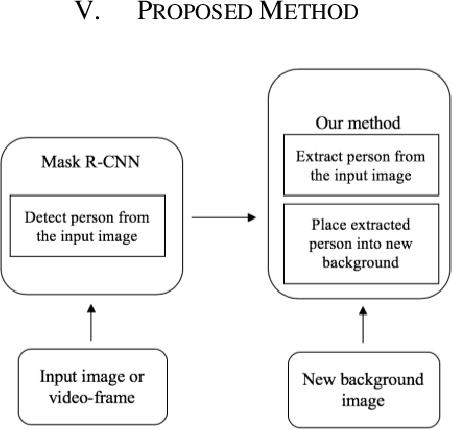
Object detection is a trendy branch of computer vision, especially on human recognition and pedestrian detection. Recognizing the complete body of a person has always been a difficult problem. Over the years, researchers proposed various methods, and recently, a breakthrough came into the light as Mask R-CNN. Based on Faster R-CNN, Mask R-CNN was able to generate a segmentation mask for each instance. We propose an application to extract multiple persons and put them into a new background image utilizing Mask R-CNN. Mask R-CNN detects all type of object mask from images. Then our algorithm considers only the target person and extracts a person only without obstacles, such as dogs in front of the person, and the user also can select multiple persons as their expectations. Our algorithm is effective for both an image and a video irrespective of the length of it. Also, extract those persons and place them into the new background. Our algorithm does not add any overhead to Mask R-CNN, running at 5 fps. We show examples of yoga-person in an image and a dancer in a dance-video frame. We hope our simple and effective approach would serve as a baseline for replacing the image background and help ease future research.