 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"photo": models, code, and papers
Learning to Caricature via Semantic Shape Transform
Aug 12, 2020


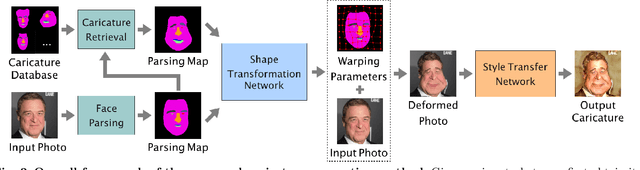
Caricature is an artistic drawing created to abstract or exaggerate facial features of a person. Rendering visually pleasing caricatures is a difficult task that requires professional skills, and thus it is of great interest to design a method to automatically generate such drawings. To deal with large shape changes, we propose an algorithm based on a semantic shape transform to produce diverse and plausible shape exaggerations. Specifically, we predict pixel-wise semantic correspondences and perform image warping on the input photo to achieve dense shape transformation. We show that the proposed framework is able to render visually pleasing shape exaggerations while maintaining their facial structures. In addition, our model allows users to manipulate the shape via the semantic map. We demonstrate the effectiveness of our approach on a large photograph-caricature benchmark dataset with comparisons to the state-of-the-art methods.
Deep Image Compositing
Nov 04, 2020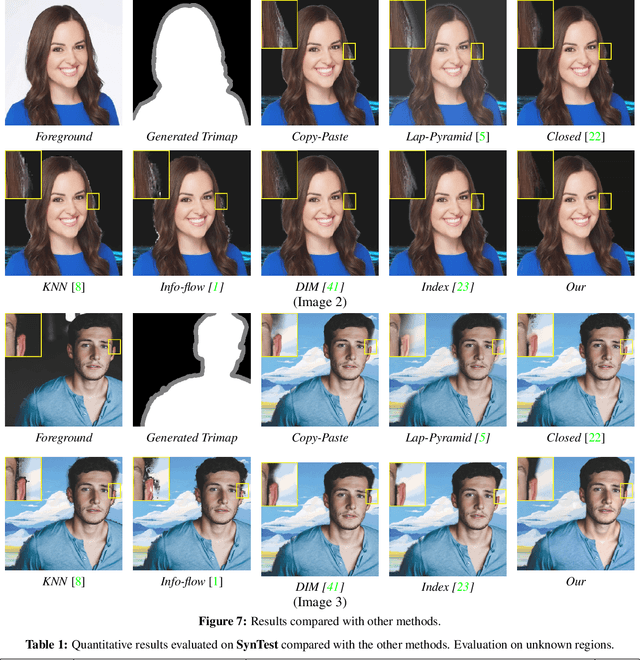

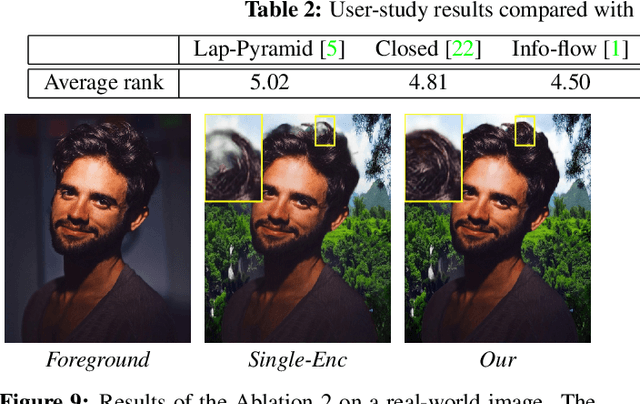
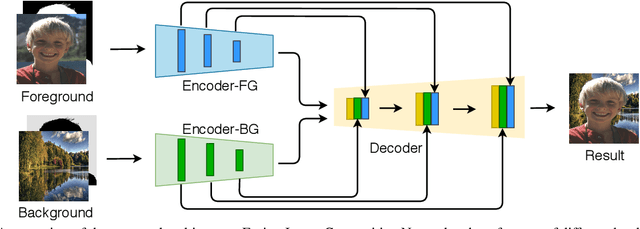
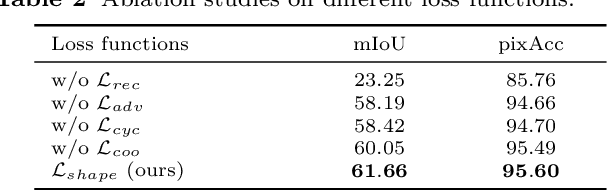
Image compositing is a task of combining regions from different images to compose a new image. A common use case is background replacement of portrait images. To obtain high quality composites, professionals typically manually perform multiple editing steps such as segmentation, matting and foreground color decontamination, which is very time consuming even with sophisticated photo editing tools. In this paper, we propose a new method which can automatically generate high-quality image compositing without any user input. Our method can be trained end-to-end to optimize exploitation of contextual and color information of both foreground and background images, where the compositing quality is considered in the optimization. Specifically, inspired by Laplacian pyramid blending, a dense-connected multi-stream fusion network is proposed to effectively fuse the information from the foreground and background images at different scales. In addition, we introduce a self-taught strategy to progressively train from easy to complex cases to mitigate the lack of training data. Experiments show that the proposed method can automatically generate high-quality composites and outperforms existing methods both qualitatively and quantitatively.
PVA: Pixel-aligned Volumetric Avatars
Jan 07, 2021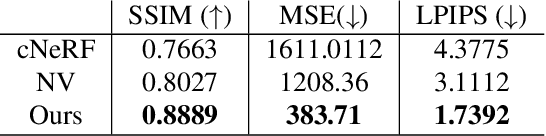
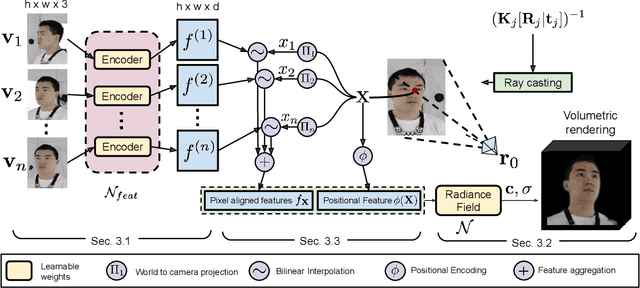


Acquisition and rendering of photo-realistic human heads is a highly challenging research problem of particular importance for virtual telepresence. Currently, the highest quality is achieved by volumetric approaches trained in a person specific manner on multi-view data. These models better represent fine structure, such as hair, compared to simpler mesh-based models. Volumetric models typically employ a global code to represent facial expressions, such that they can be driven by a small set of animation parameters. While such architectures achieve impressive rendering quality, they can not easily be extended to the multi-identity setting. In this paper, we devise a novel approach for predicting volumetric avatars of the human head given just a small number of inputs. We enable generalization across identities by a novel parameterization that combines neural radiance fields with local, pixel-aligned features extracted directly from the inputs, thus sidestepping the need for very deep or complex networks. Our approach is trained in an end-to-end manner solely based on a photometric re-rendering loss without requiring explicit 3D supervision.We demonstrate that our approach outperforms the existing state of the art in terms of quality and is able to generate faithful facial expressions in a multi-identity setting.
Learning a Deep Reinforcement Learning Policy Over the Latent Space of a Pre-trained GAN for Semantic Age Manipulation
Nov 02, 2020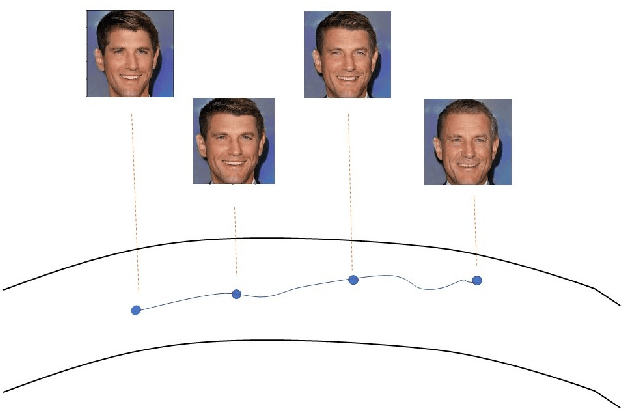


Learning a disentangled representation of the latent space has become one of the most fundamental problems studied in computer vision. Recently, many generative adversarial networks (GANs) have shown promising results in generating high fidelity images. However, studies to understand the semantic layout of the latent space of pre-trained models are still limited. Several works train conditional GANs to generate faces with required semantic attributes. Unfortunately, in these attempts often the generated output is not as photo-realistic as the state of the art models. Besides, they also require large computational resources and specific datasets to generate high fidelity images. In our work, we have formulated a Markov Decision Process (MDP) over the rich latent space of a pre-trained GAN model to learn a conditional policy for semantic manipulation along specific attributes under defined identity bounds. Further, we have defined a semantic age manipulation scheme using a locally linear approximation over the latent space. Results show that our learned policy can sample high fidelity images with required age variations, while at the same time preserve the identity of the person.
WarpGAN: Automatic Caricature Generation
Nov 28, 2018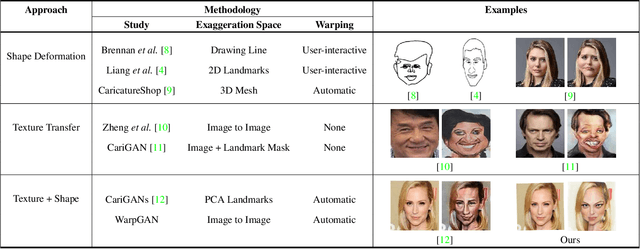
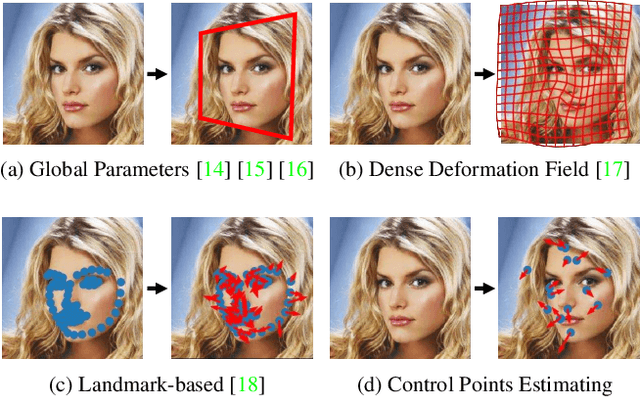
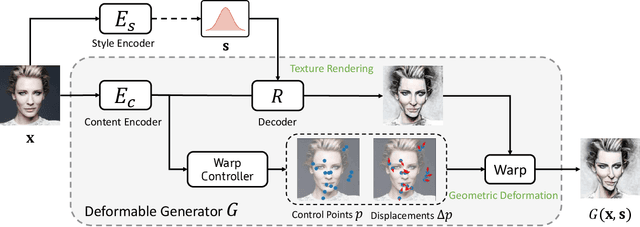
We propose, WarpGAN, a fully automatic network that can generate caricatures given an input face photo. Besides transferring rich texture styles, WarpGAN learns to automatically predict a set of control points that can warp the photo into a caricature, while preserving identity. We introduce an identity-preserving adversarial loss that aids the discriminator to distinguish between different subjects. Moreover, WarpGAN allows customization of the generated caricatures by controlling the exaggeration extent and the visual styles. Experimental results on a public domain dataset, WebCaricature, show that WarpGAN is capable of generating a diverse set of caricatures while preserving the identities. Five caricature experts suggest that caricatures generated by WarpGAN are visually similar to hand-drawn ones and only prominent facial features are exaggerated.
Synthesizing Coupled 3D Face Modalities by Trunk-Branch Generative Adversarial Networks
Sep 05, 2019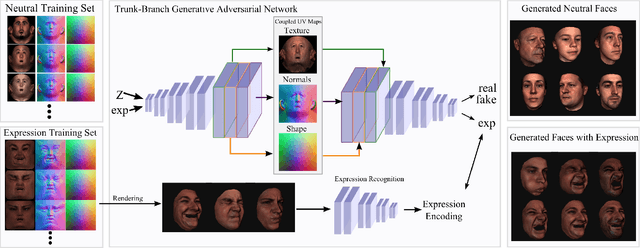
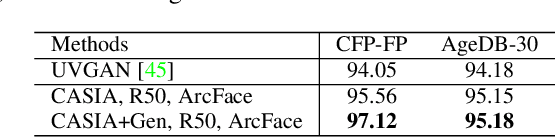


Generating realistic 3D faces is of high importance for computer graphics and computer vision applications. Generally, research on 3D face generation revolves around linear statistical models of the facial surface. Nevertheless, these models cannot represent faithfully either the facial texture or the normals of the face, which are very crucial for photo-realistic face synthesis. Recently, it was demonstrated that Generative Adversarial Networks (GANs) can be used for generating high-quality textures of faces. Nevertheless, the generation process either omits the geometry and normals, or independent processes are used to produce 3D shape information. In this paper, we present the first methodology that generates high-quality texture, shape, and normals jointly, which can be used for photo-realistic synthesis. To do so, we propose a novel GAN that can generate data from different modalities while exploiting their correlations. Furthermore, we demonstrate how we can condition the generation on the expression and create faces with various facial expressions. The qualitative results shown in this pre-print is compressed due to size limitations, full resolution results and the accompanying video can be found at the project page: https://github.com/barisgecer/TBGAN.
Face Sketch Synthesis with Style Transfer using Pyramid Column Feature
Sep 18, 2020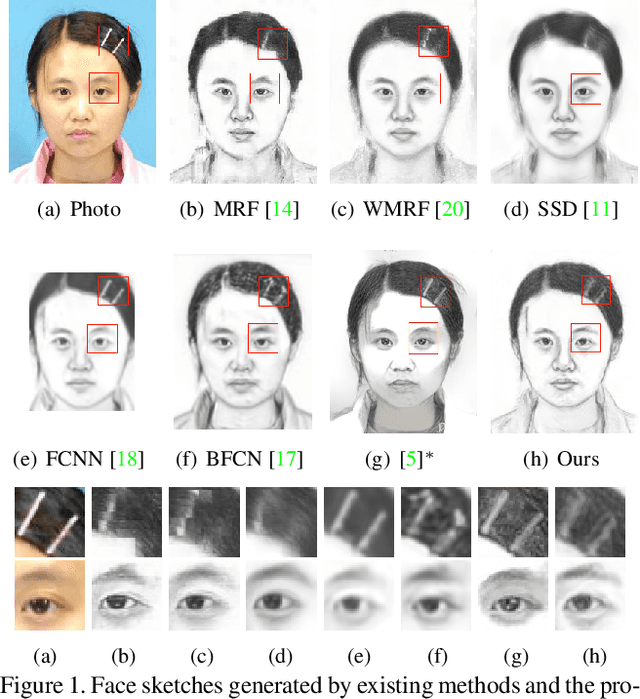
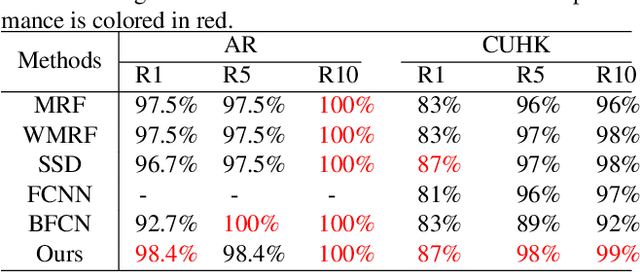
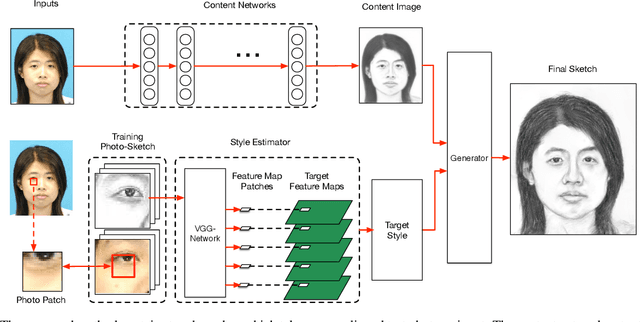
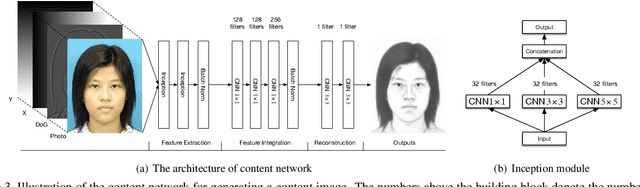
In this paper, we propose a novel framework based on deep neural networks for face sketch synthesis from a photo. Imitating the process of how artists draw sketches, our framework synthesizes face sketches in a cascaded manner. A content image is first generated that outlines the shape of the face and the key facial features. Textures and shadings are then added to enrich the details of the sketch. We utilize a fully convolutional neural network (FCNN) to create the content image, and propose a style transfer approach to introduce textures and shadings based on a newly proposed pyramid column feature. We demonstrate that our style transfer approach based on the pyramid column feature can not only preserve more sketch details than the common style transfer method, but also surpasses traditional patch based methods. Quantitative and qualitative evaluations suggest that our framework outperforms other state-of-the-arts methods, and can also generalize well to different test images. Codes are available at https://github.com/chaofengc/Face-Sketch
Animating Pictures with Eulerian Motion Fields
Nov 30, 2020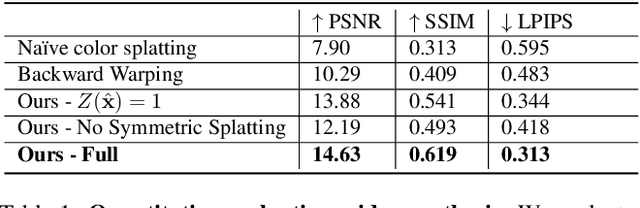
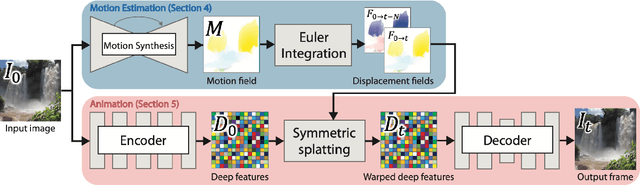
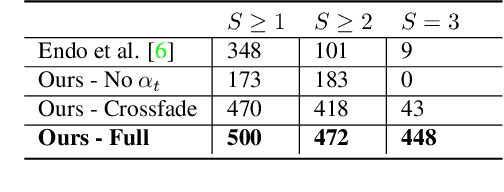

In this paper, we demonstrate a fully automatic method for converting a still image into a realistic animated looping video. We target scenes with continuous fluid motion, such as flowing water and billowing smoke. Our method relies on the observation that this type of natural motion can be convincingly reproduced from a static Eulerian motion description, i.e. a single, temporally constant flow field that defines the immediate motion of a particle at a given 2D location. We use an image-to-image translation network to encode motion priors of natural scenes collected from online videos, so that for a new photo, we can synthesize a corresponding motion field. The image is then animated using the generated motion through a deep warping technique: pixels are encoded as deep features, those features are warped via Eulerian motion, and the resulting warped feature maps are decoded as images. In order to produce continuous, seamlessly looping video textures, we propose a novel video looping technique that flows features both forward and backward in time and then blends the results. We demonstrate the effectiveness and robustness of our method by applying it to a large collection of examples including beaches, waterfalls, and flowing rivers.
SRGAN: Training Dataset Matters
Mar 24, 2019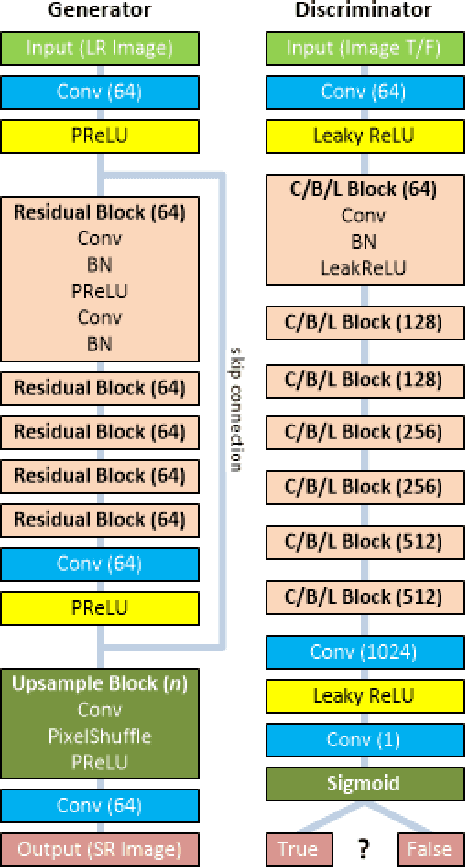

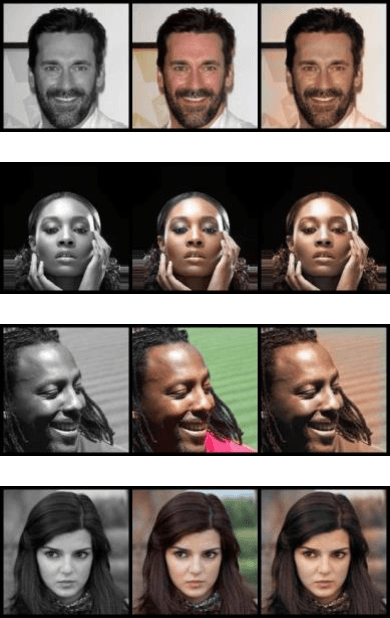

Generative Adversarial Networks (GANs) in supervised settings can generate photo-realistic corresponding output from low-definition input (SRGAN). Using the architecture presented in the SRGAN original paper [2], we explore how selecting a dataset affects the outcome by using three different datasets to see that SRGAN fundamentally learns objects, with their shape, color, and texture, and redraws them in the output rather than merely attempting to sharpen edges. This is further underscored with our demonstration that once the network learns the images of the dataset, it can generate a photo-like image with even a slight hint of what it might look like for the original from a very blurry edged sketch. Given a set of inference images, the network trained with the same dataset results in a better outcome over the one trained with arbitrary set of images, and we report its significance numerically with Frechet Inception Distance score [22].
Deep 3D-Zoom Net: Unsupervised Learning of Photo-Realistic 3D-Zoom
Oct 02, 2019
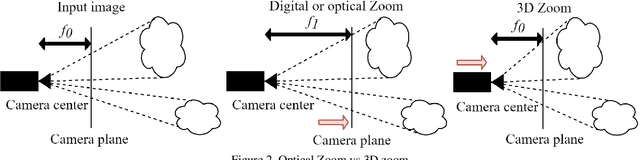
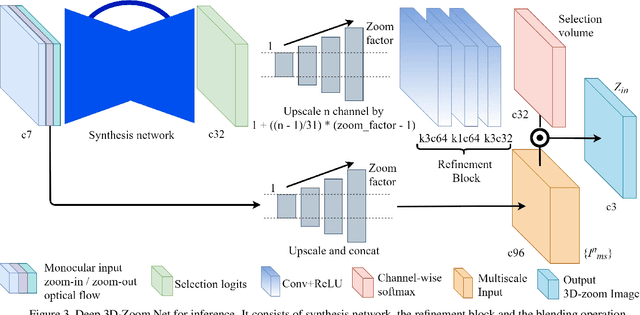
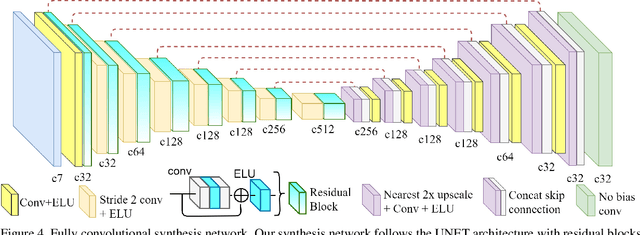
The 3D-zoom operation is the positive translation of the camera in the Z-axis, perpendicular to the image plane. In contrast, the optical zoom changes the focal length and the digital zoom is used to enlarge a certain region of an image to the original image size. In this paper, we are the first to formulate an unsupervised 3D-zoom learning problem where images with an arbitrary zoom factor can be generated from a given single image. An unsupervised framework is convenient, as it is a challenging task to obtain a 3D-zoom dataset of natural scenes due to the need for special equipment to ensure camera movement is restricted to the Z-axis. In addition, the objects in the scenes should not move when being captured, which hinders the construction of a large dataset of outdoor scenes. We present a novel unsupervised framework to learn how to generate arbitrarily 3D-zoomed versions of a single image, not requiring a 3D-zoom ground truth, called the Deep 3D-Zoom Net. The Deep 3D-Zoom Net incorporates the following features: (i) transfer learning from a pre-trained disparity estimation network via a back re-projection reconstruction loss; (ii) a fully convolutional network architecture that models depth-image-based rendering (DIBR), taking into account high-frequency details without the need for estimating the intermediate disparity; and (iii) incorporating a discriminator network that acts as a no-reference penalty for unnaturally rendered areas. Even though there is no baseline to fairly compare our results, our method outperforms previous novel view synthesis research in terms of realistic appearance on large camera baselines. We performed extensive experiments to verify the effectiveness of our method on the KITTI and Cityscapes datasets.