 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Towards Contrastive Learning in Music Video Domain
Sep 01, 2023
Contrastive learning is a powerful way of learning multimodal representations across various domains such as image-caption retrieval and audio-visual representation learning. In this work, we investigate if these findings generalize to the domain of music videos. Specifically, we create a dual en-coder for the audio and video modalities and train it using a bidirectional contrastive loss. For the experiments, we use an industry dataset containing 550 000 music videos as well as the public Million Song Dataset, and evaluate the quality of learned representations on the downstream tasks of music tagging and genre classification. Our results indicate that pre-trained networks without contrastive fine-tuning outperform our contrastive learning approach when evaluated on both tasks. To gain a better understanding of the reasons contrastive learning was not successful for music videos, we perform a qualitative analysis of the learned representations, revealing why contrastive learning might have difficulties uniting embeddings from two modalities. Based on these findings, we outline possible directions for future work. To facilitate the reproducibility of our results, we share our code and the pre-trained model.
Improving Emotional Expression and Cohesion in Image-Based Playlist Description and Music Topics: A Continuous Parameterization Approach
Oct 12, 2023Text generation in image-based platforms, particularly for music-related content, requires precise control over text styles and the incorporation of emotional expression. However, existing approaches often need help to control the proportion of external factors in generated text and rely on discrete inputs, lacking continuous control conditions for desired text generation. This study proposes Continuous Parameterization for Controlled Text Generation (CPCTG) to overcome these limitations. Our approach leverages a Language Model (LM) as a style learner, integrating Semantic Cohesion (SC) and Emotional Expression Proportion (EEP) considerations. By enhancing the reward method and manipulating the CPCTG level, our experiments on playlist description and music topic generation tasks demonstrate significant improvements in ROUGE scores, indicating enhanced relevance and coherence in the generated text.
Symbolic Music Representations for Classification Tasks: A Systematic Evaluation
Sep 05, 2023
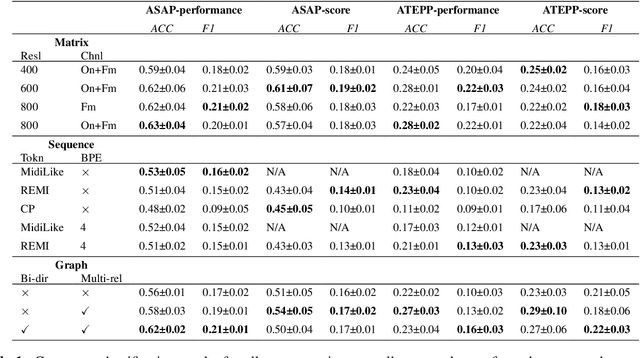
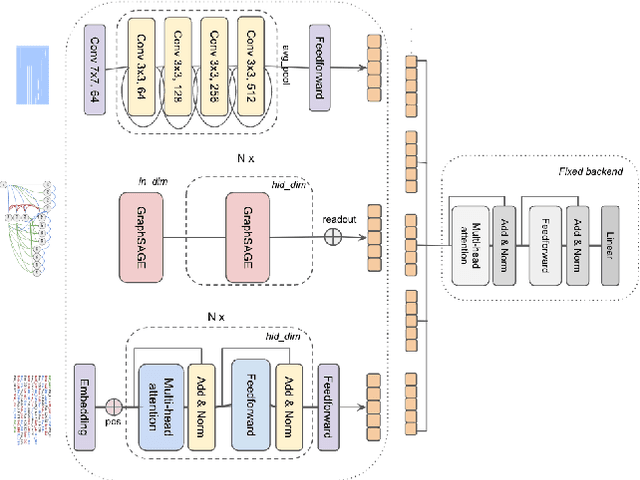
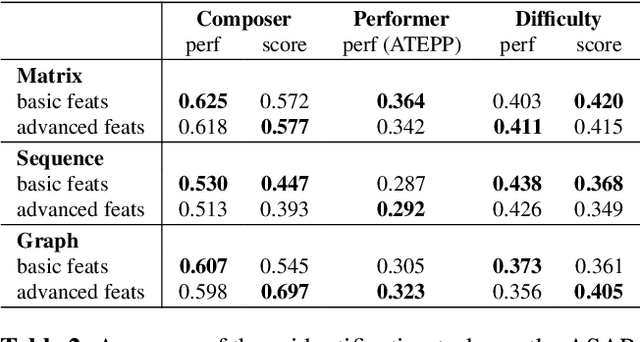
Music Information Retrieval (MIR) has seen a recent surge in deep learning-based approaches, which often involve encoding symbolic music (i.e., music represented in terms of discrete note events) in an image-like or language like fashion. However, symbolic music is neither an image nor a sentence, and research in the symbolic domain lacks a comprehensive overview of the different available representations. In this paper, we investigate matrix (piano roll), sequence, and graph representations and their corresponding neural architectures, in combination with symbolic scores and performances on three piece-level classification tasks. We also introduce a novel graph representation for symbolic performances and explore the capability of graph representations in global classification tasks. Our systematic evaluation shows advantages and limitations of each input representation. Our results suggest that the graph representation, as the newest and least explored among the three approaches, exhibits promising performance, while being more light-weight in training.
Leveraging Negative Signals with Self-Attention for Sequential Music Recommendation
Sep 20, 2023
Music streaming services heavily rely on their recommendation engines to continuously provide content to their consumers. Sequential recommendation consequently has seen considerable attention in current literature, where state of the art approaches focus on self-attentive models leveraging contextual information such as long and short-term user history and item features; however, most of these studies focus on long-form content domains (retail, movie, etc.) rather than short-form, such as music. Additionally, many do not explore incorporating negative session-level feedback during training. In this study, we investigate the use of transformer-based self-attentive architectures to learn implicit session-level information for sequential music recommendation. We additionally propose a contrastive learning task to incorporate negative feedback (e.g skipped tracks) to promote positive hits and penalize negative hits. This task is formulated as a simple loss term that can be incorporated into a variety of deep learning architectures for sequential recommendation. Our experiments show that this results in consistent performance gains over the baseline architectures ignoring negative user feedback.
InstructME: An Instruction Guided Music Edit And Remix Framework with Latent Diffusion Models
Sep 06, 2023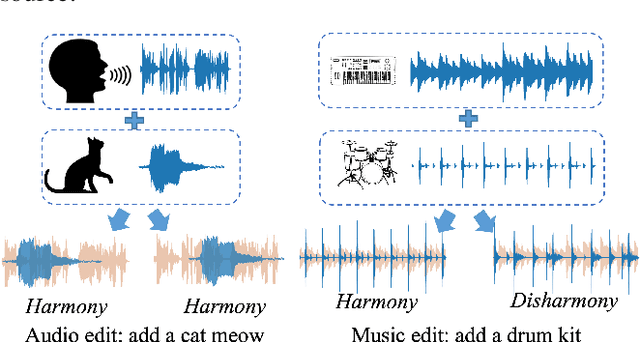
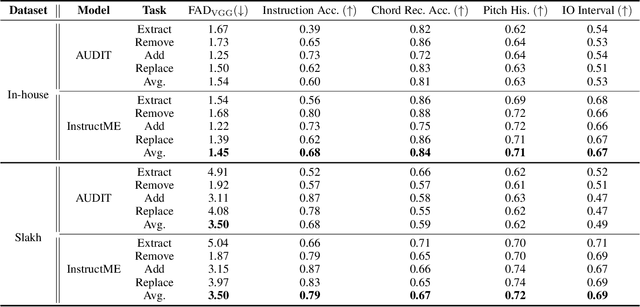
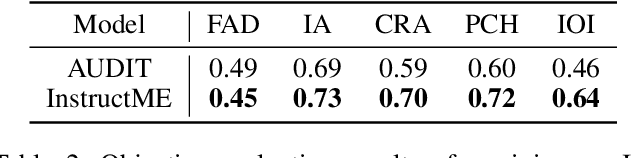
Music editing primarily entails the modification of instrument tracks or remixing in the whole, which offers a novel reinterpretation of the original piece through a series of operations. These music processing methods hold immense potential across various applications but demand substantial expertise. Prior methodologies, although effective for image and audio modifications, falter when directly applied to music. This is attributed to music's distinctive data nature, where such methods can inadvertently compromise the intrinsic harmony and coherence of music. In this paper, we develop InstructME, an Instruction guided Music Editing and remixing framework based on latent diffusion models. Our framework fortifies the U-Net with multi-scale aggregation in order to maintain consistency before and after editing. In addition, we introduce chord progression matrix as condition information and incorporate it in the semantic space to improve melodic harmony while editing. For accommodating extended musical pieces, InstructME employs a chunk transformer, enabling it to discern long-term temporal dependencies within music sequences. We tested InstructME in instrument-editing, remixing, and multi-round editing. Both subjective and objective evaluations indicate that our proposed method significantly surpasses preceding systems in music quality, text relevance and harmony. Demo samples are available at https://musicedit.github.io/
Scaling Up Music Information Retrieval Training with Semi-Supervised Learning
Oct 02, 2023In the era of data-driven Music Information Retrieval (MIR), the scarcity of labeled data has been one of the major concerns to the success of an MIR task. In this work, we leverage the semi-supervised teacher-student training approach to improve MIR tasks. For training, we scale up the unlabeled music data to 240k hours, which is much larger than any public MIR datasets. We iteratively create and refine the pseudo-labels in the noisy teacher-student training process. Knowledge expansion is also explored to iteratively scale up the model sizes from as small as less than 3M to almost 100M parameters. We study the performance correlation between data size and model size in the experiments. By scaling up both model size and training data, our models achieve state-of-the-art results on several MIR tasks compared to models that are either trained in a supervised manner or based on a self-supervised pretrained model. To our knowledge, this is the first attempt to study the effects of scaling up both model and training data for a variety of MIR tasks.
MUSE: Music Recommender System with Shuffle Play Recommendation Enhancement
Aug 26, 2023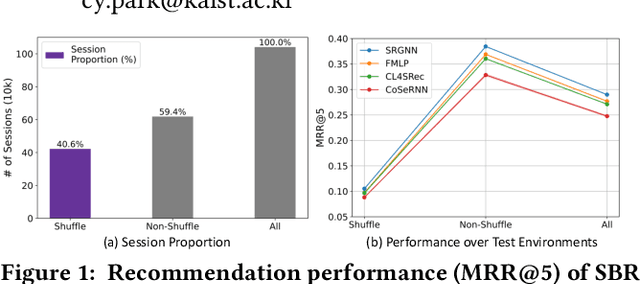
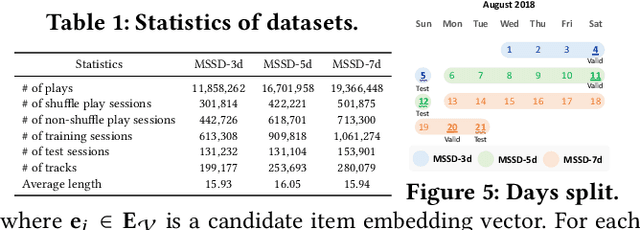
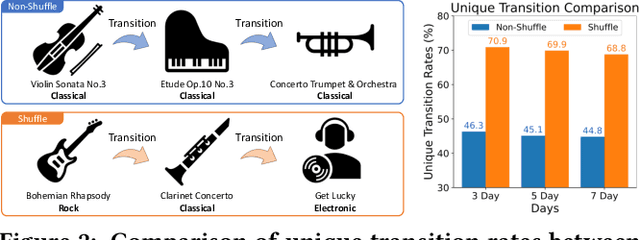
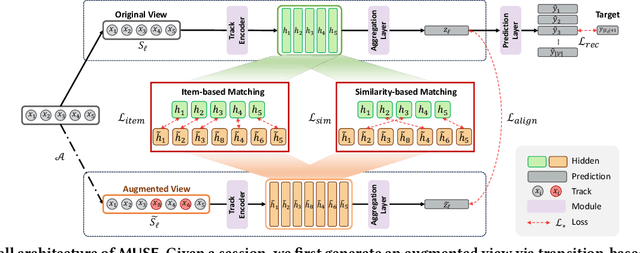
Recommender systems have become indispensable in music streaming services, enhancing user experiences by personalizing playlists and facilitating the serendipitous discovery of new music. However, the existing recommender systems overlook the unique challenges inherent in the music domain, specifically shuffle play, which provides subsequent tracks in a random sequence. Based on our observation that the shuffle play sessions hinder the overall training process of music recommender systems mainly due to the high unique transition rates of shuffle play sessions, we propose a Music Recommender System with Shuffle Play Recommendation Enhancement (MUSE). MUSE employs the self-supervised learning framework that maximizes the agreement between the original session and the augmented session, which is augmented by our novel session augmentation method, called transition-based augmentation. To further facilitate the alignment of the representations between the two views, we devise two fine-grained matching strategies, i.e., item- and similarity-based matching strategies. Through rigorous experiments conducted across diverse environments, we demonstrate MUSE's efficacy over 12 baseline models on a large-scale Music Streaming Sessions Dataset (MSSD) from Spotify. The source code of MUSE is available at \url{https://github.com/yunhak0/MUSE}.
Audiobox: Unified Audio Generation with Natural Language Prompts
Dec 25, 2023Audio is an essential part of our life, but creating it often requires expertise and is time-consuming. Research communities have made great progress over the past year advancing the performance of large scale audio generative models for a single modality (speech, sound, or music) through adopting more powerful generative models and scaling data. However, these models lack controllability in several aspects: speech generation models cannot synthesize novel styles based on text description and are limited on domain coverage such as outdoor environments; sound generation models only provide coarse-grained control based on descriptions like "a person speaking" and would only generate mumbling human voices. This paper presents Audiobox, a unified model based on flow-matching that is capable of generating various audio modalities. We design description-based and example-based prompting to enhance controllability and unify speech and sound generation paradigms. We allow transcript, vocal, and other audio styles to be controlled independently when generating speech. To improve model generalization with limited labels, we adapt a self-supervised infilling objective to pre-train on large quantities of unlabeled audio. Audiobox sets new benchmarks on speech and sound generation (0.745 similarity on Librispeech for zero-shot TTS; 0.77 FAD on AudioCaps for text-to-sound) and unlocks new methods for generating audio with novel vocal and acoustic styles. We further integrate Bespoke Solvers, which speeds up generation by over 25 times compared to the default ODE solver for flow-matching, without loss of performance on several tasks. Our demo is available at https://audiobox.metademolab.com/
Exploring Popularity Bias in Session-based Recommendation
Dec 13, 2023Existing work has revealed that large-scale offline evaluation of recommender systems for user-item interactions is prone to bias caused by the deployed system itself, as a form of closed loop feedback. Many adopt the \textit{propensity} concept to analyze or mitigate this empirical issue. In this work, we extend the analysis to session-based setup and adapted propensity calculation to the unique characteristics of session-based recommendation tasks. Our experiments incorporate neural models and KNN-based models, and cover both the music and the e-commerce domain. We study the distributions of propensity and different stratification techniques on different datasets and find that propensity-related traits are actually dataset-specific. We then leverage the effect of stratification and achieve promising results compared to the original models.
A Semi-Supervised Deep Learning Approach to Dataset Collection for Query-By-Humming Task
Dec 02, 2023Query-by-Humming (QbH) is a task that involves finding the most relevant song based on a hummed or sung fragment. Despite recent successful commercial solutions, implementing QbH systems remains challenging due to the lack of high-quality datasets for training machine learning models. In this paper, we propose a deep learning data collection technique and introduce Covers and Hummings Aligned Dataset (CHAD), a novel dataset that contains 18 hours of short music fragments, paired with time-aligned hummed versions. To expand our dataset, we employ a semi-supervised model training pipeline that leverages the QbH task as a specialized case of cover song identification (CSI) task. Starting with a model trained on the initial dataset, we iteratively collect groups of fragments of cover versions of the same song and retrain the model on the extended data. Using this pipeline, we collect over 308 hours of additional music fragments, paired with time-aligned cover versions. The final model is successfully applied to the QbH task and achieves competitive results on benchmark datasets. Our study shows that the proposed dataset and training pipeline can effectively facilitate the implementation of QbH systems.