 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
Music ControlNet: Multiple Time-varying Controls for Music Generation
Nov 13, 2023
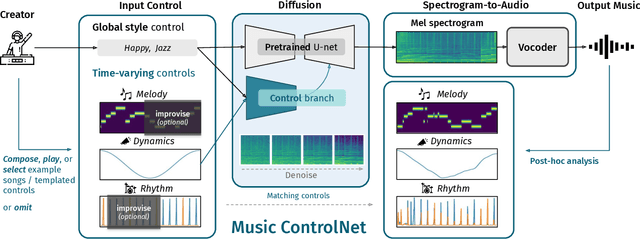
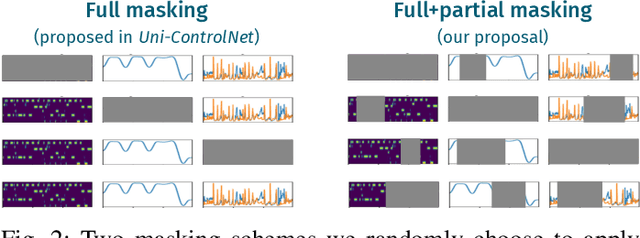
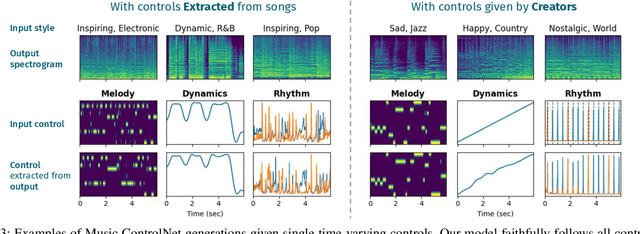
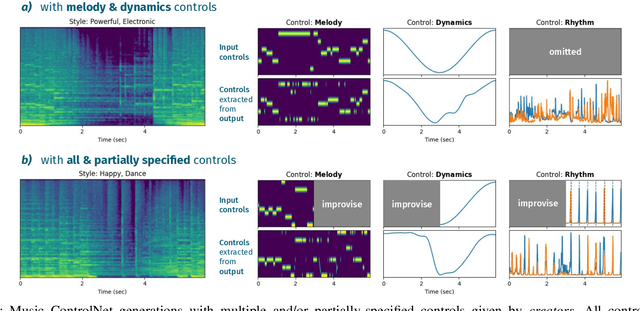
Text-to-music generation models are now capable of generating high-quality music audio in broad styles. However, text control is primarily suitable for the manipulation of global musical attributes like genre, mood, and tempo, and is less suitable for precise control over time-varying attributes such as the positions of beats in time or the changing dynamics of the music. We propose Music ControlNet, a diffusion-based music generation model that offers multiple precise, time-varying controls over generated audio. To imbue text-to-music models with time-varying control, we propose an approach analogous to pixel-wise control of the image-domain ControlNet method. Specifically, we extract controls from training audio yielding paired data, and fine-tune a diffusion-based conditional generative model over audio spectrograms given melody, dynamics, and rhythm controls. While the image-domain Uni-ControlNet method already allows generation with any subset of controls, we devise a new strategy to allow creators to input controls that are only partially specified in time. We evaluate both on controls extracted from audio and controls we expect creators to provide, demonstrating that we can generate realistic music that corresponds to control inputs in both settings. While few comparable music generation models exist, we benchmark against MusicGen, a recent model that accepts text and melody input, and show that our model generates music that is 49% more faithful to input melodies despite having 35x fewer parameters, training on 11x less data, and enabling two additional forms of time-varying control. Sound examples can be found at https://MusicControlNet.github.io/web/.
Exploring Multi-Modal Control in Music-Driven Dance Generation
Jan 01, 2024Existing music-driven 3D dance generation methods mainly concentrate on high-quality dance generation, but lack sufficient control during the generation process. To address these issues, we propose a unified framework capable of generating high-quality dance movements and supporting multi-modal control, including genre control, semantic control, and spatial control. First, we decouple the dance generation network from the dance control network, thereby avoiding the degradation in dance quality when adding additional control information. Second, we design specific control strategies for different control information and integrate them into a unified framework. Experimental results show that the proposed dance generation framework outperforms state-of-the-art methods in terms of motion quality and controllability.
PBSCSR: The Piano Bootleg Score Composer Style Recognition Dataset
Jan 30, 2024This article motivates, describes, and presents the PBSCSR dataset for studying composer style recognition of piano sheet music. Our overarching goal was to create a dataset for studying composer style recognition that is "as accessible as MNIST and as challenging as ImageNet." To achieve this goal, we sample fixed-length bootleg score fragments from piano sheet music images on IMSLP. The dataset itself contains 40,000 62x64 bootleg score images for a 9-way classification task, 100,000 62x64 bootleg score images for a 100-way classification task, and 29,310 unlabeled variable-length bootleg score images for pretraining. The labeled data is presented in a form that mirrors MNIST images, in order to make it extremely easy to visualize, manipulate, and train models in an efficient manner. Additionally, we include relevant metadata to allow access to the underlying raw sheet music images and other related data on IMSLP. We describe several research tasks that could be studied with the dataset, including variations of composer style recognition in a few-shot or zero-shot setting. For tasks that have previously proposed models, we release code and baseline results for future works to compare against. We also discuss open research questions that the PBSCSR data is especially well suited to facilitate research on and areas of fruitful exploration in future work.
Bass Accompaniment Generation via Latent Diffusion
Feb 02, 2024The ability to automatically generate music that appropriately matches an arbitrary input track is a challenging task. We present a novel controllable system for generating single stems to accompany musical mixes of arbitrary length. At the core of our method are audio autoencoders that efficiently compress audio waveform samples into invertible latent representations, and a conditional latent diffusion model that takes as input the latent encoding of a mix and generates the latent encoding of a corresponding stem. To provide control over the timbre of generated samples, we introduce a technique to ground the latent space to a user-provided reference style during diffusion sampling. For further improving audio quality, we adapt classifier-free guidance to avoid distortions at high guidance strengths when generating an unbounded latent space. We train our model on a dataset of pairs of mixes and matching bass stems. Quantitative experiments demonstrate that, given an input mix, the proposed system can generate basslines with user-specified timbres. Our controllable conditional audio generation framework represents a significant step forward in creating generative AI tools to assist musicians in music production.
Computational Copyright: Towards A Royalty Model for AI Music Generation Platforms
Dec 11, 2023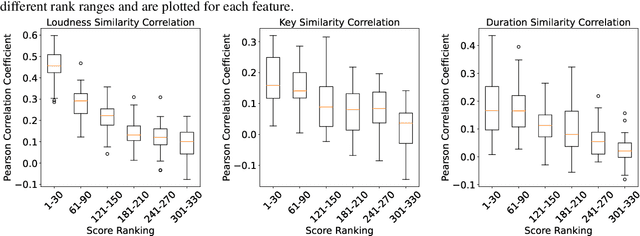
The advancement of generative AI has given rise to pressing copyright challenges, particularly in music industry. This paper focuses on the economic aspects of these challenges, emphasizing that the economic impact constitutes a central issue in the copyright arena. The complexity of the black-box generative AI technologies not only suggests but necessitates algorithmic solutions. However, such solutions have been largely missing, leading to regulatory challenges in this landscape. We aim to bridge the gap in current approaches by proposing potential royalty models for revenue sharing on AI music generation platforms. Our methodology involves a detailed analysis of existing royalty models in platforms like Spotify and YouTube, and adapting these to the unique context of AI-generated music. A significant challenge we address is the attribution of AI-generated music to influential copyrighted content in the training data. To this end, we present algorithmic solutions employing data attribution techniques. Our experimental results verify the effectiveness of these solutions. This research represents a pioneering effort in integrating technical advancements with economic and legal considerations in the field of generative AI, offering a computational copyright solution for the challenges posed by the opaque nature of AI technologies.
Diffusion Models for Audio Restoration
Feb 15, 2024With the development of audio playback devices and fast data transmission, the demand for high sound quality is rising, for both entertainment and communications. In this quest for better sound quality, challenges emerge from distortions and interferences originating at the recording side or caused by an imperfect transmission pipeline. To address this problem, audio restoration methods aim to recover clean sound signals from the corrupted input data. We present here audio restoration algorithms based on diffusion models, with a focus on speech enhancement and music restoration tasks. Traditional approaches, often grounded in handcrafted rules and statistical heuristics, have shaped our understanding of audio signals. In the past decades, there has been a notable shift towards data-driven methods that exploit the modeling capabilities of deep neural networks (DNNs). Deep generative models, and among them diffusion models, have emerged as powerful techniques for learning complex data distributions. However, relying solely on DNN-based learning approaches carries the risk of reducing interpretability, particularly when employing end-to-end models. Nonetheless, data-driven approaches allow more flexibility in comparison to statistical model-based frameworks whose performance depends on distributional and statistical assumptions that can be difficult to guarantee. Here, we aim to show that diffusion models can combine the best of both worlds and offer the opportunity to design audio restoration algorithms with a good degree of interpretability and a remarkable performance in terms of sound quality.
Mustango: Toward Controllable Text-to-Music Generation
Nov 14, 2023With recent advancements in text-to-audio and text-to-music based on latent diffusion models, the quality of generated content has been reaching new heights. The controllability of musical aspects, however, has not been explicitly explored in text-to-music systems yet. In this paper, we present Mustango, a music-domain-knowledge-inspired text-to-music system based on diffusion, that expands the Tango text-to-audio model. Mustango aims to control the generated music, not only with general text captions, but from more rich captions that could include specific instructions related to chords, beats, tempo, and key. As part of Mustango, we propose MuNet, a Music-Domain-Knowledge-Informed UNet sub-module to integrate these music-specific features, which we predict from the text prompt, as well as the general text embedding, into the diffusion denoising process. To overcome the limited availability of open datasets of music with text captions, we propose a novel data augmentation method that includes altering the harmonic, rhythmic, and dynamic aspects of music audio and using state-of-the-art Music Information Retrieval methods to extract the music features which will then be appended to the existing descriptions in text format. We release the resulting MusicBench dataset which contains over 52K instances and includes music-theory-based descriptions in the caption text. Through extensive experiments, we show that the quality of the music generated by Mustango is state-of-the-art, and the controllability through music-specific text prompts greatly outperforms other models in terms of desired chords, beat, key, and tempo, on multiple datasets.
GLA-Grad: A Griffin-Lim Extended Waveform Generation Diffusion Model
Feb 09, 2024Diffusion models are receiving a growing interest for a variety of signal generation tasks such as speech or music synthesis. WaveGrad, for example, is a successful diffusion model that conditionally uses the mel spectrogram to guide a diffusion process for the generation of high-fidelity audio. However, such models face important challenges concerning the noise diffusion process for training and inference, and they have difficulty generating high-quality speech for speakers that were not seen during training. With the aim of minimizing the conditioning error and increasing the efficiency of the noise diffusion process, we propose in this paper a new scheme called GLA-Grad, which consists in introducing a phase recovery algorithm such as the Griffin-Lim algorithm (GLA) at each step of the regular diffusion process. Furthermore, it can be directly applied to an already-trained waveform generation model, without additional training or fine-tuning. We show that our algorithm outperforms state-of-the-art diffusion models for speech generation, especially when generating speech for a previously unseen target speaker.
* Accepted at ICASSP 2024
Amphion: An Open-Source Audio, Music and Speech Generation Toolkit
Dec 15, 2023
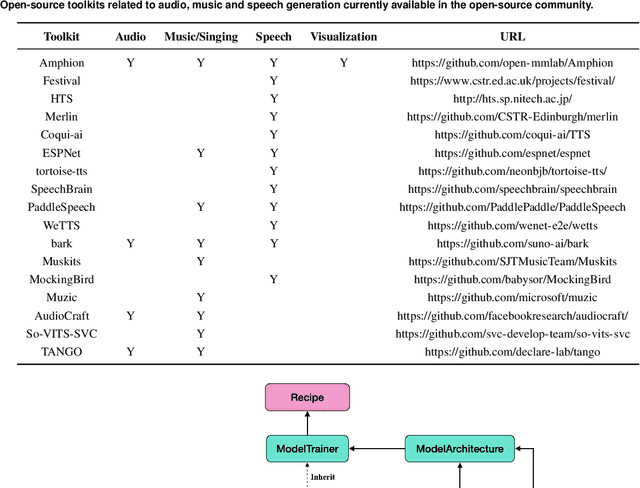
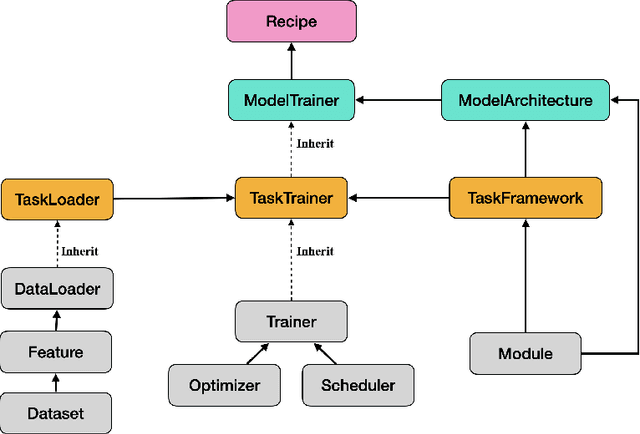
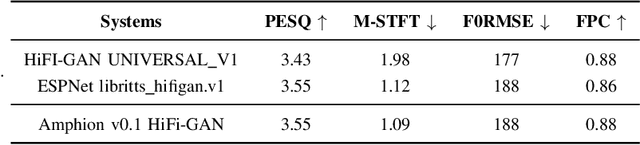
Amphion is a toolkit for Audio, Music, and Speech Generation. Its purpose is to support reproducible research and help junior researchers and engineers get started in the field of audio, music, and speech generation research and development. Amphion offers a unique feature: visualizations of classic models or architectures. We believe that these visualizations are beneficial for junior researchers and engineers who wish to gain a better understanding of the model. The North-Star objective of Amphion is to offer a platform for studying the conversion of any inputs into general audio. Amphion is designed to support individual generation tasks. In addition to the specific generation tasks, Amphion also includes several vocoders and evaluation metrics. A vocoder is an important module for producing high-quality audio signals, while evaluation metrics are critical for ensuring consistent metrics in generation tasks. In this paper, we provide a high-level overview of Amphion.
Interactive singing melody extraction based on active adaptation
Feb 12, 2024Extraction of predominant pitch from polyphonic audio is one of the fundamental tasks in the field of music information retrieval and computational musicology. To accomplish this task using machine learning, a large amount of labeled audio data is required to train the model. However, a classical model pre-trained on data from one domain (source), e.g., songs of a particular singer or genre, may not perform comparatively well in extracting melody from other domains (target). The performance of such models can be boosted by adapting the model using very little annotated data from the target domain. In this work, we propose an efficient interactive melody adaptation method. Our method selects the regions in the target audio that require human annotation using a confidence criterion based on normalized true class probability. The annotations are used by the model to adapt itself to the target domain using meta-learning. Our method also provides a novel meta-learning approach that handles class imbalance, i.e., a few representative samples from a few classes are available for adaptation in the target domain. Experimental results show that the proposed method outperforms other adaptive melody extraction baselines. The proposed method is model-agnostic and hence can be applied to other non-adaptive melody extraction models to boost their performance. Also, we released a Hindustani Alankaar and Raga (HAR) dataset containing 523 audio files of about 6.86 hours of duration intended for singing melody extraction tasks.