 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"music": models, code, and papers
A Real-Time Tempo and Meter Tracking System for Rhythmic Improvis
Aug 31, 2022
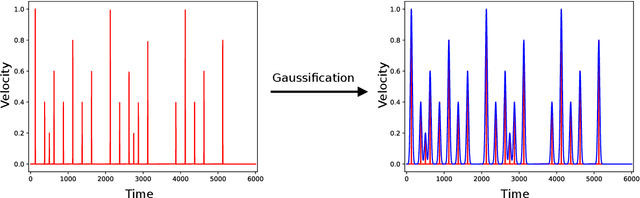
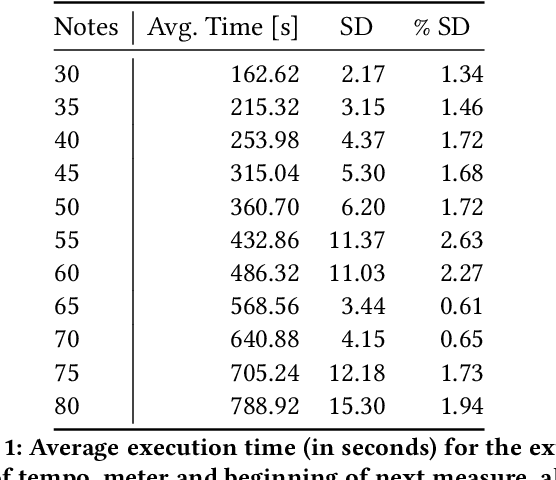
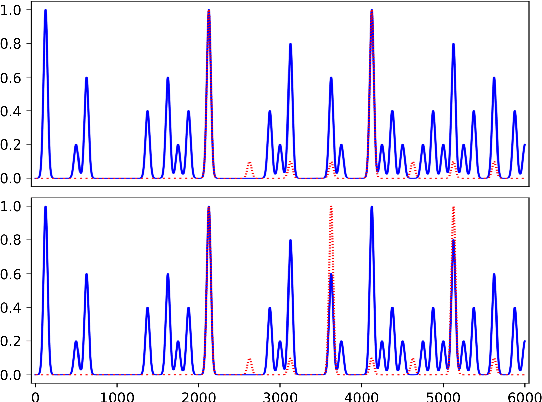
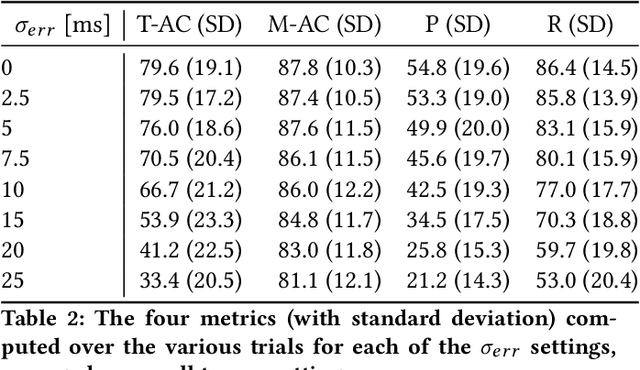
Music is a form of expression that often requires interaction between players. If one wishes to interact in such a musical way with a computer, it is necessary for the machine to be able to interpret the input given by the human to find its musical meaning. In this work, we propose a system capable of detecting basic rhythmic features that can allow an application to synchronize its output with the rhythm given by the user, without having any prior agreement or requirement on the possible input. The system is described in detail and an evaluation is given through simulation using quantitative metrics. The evaluation shows that the system can detect tempo and meter consistently under certain settings, and could be a solid base for further developments leading to a system robust to rhythmically changing inputs.
Modeling Perceptual Loudness of Piano Tone: Theory and Applications
Sep 21, 2022
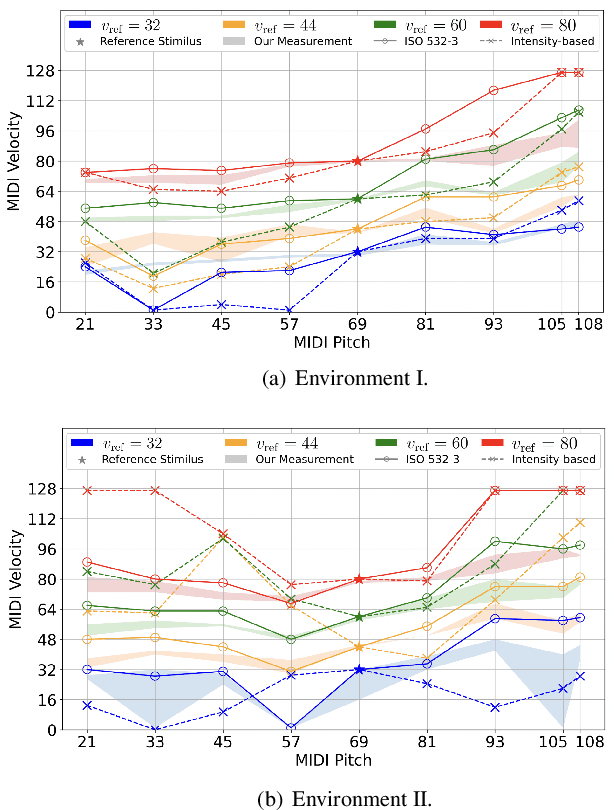
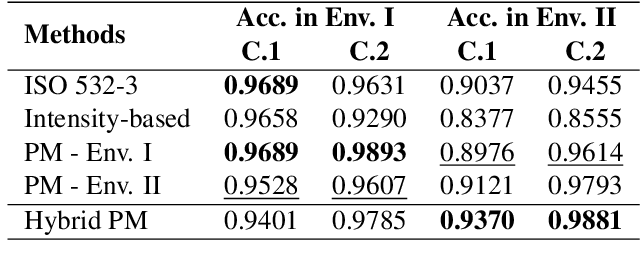
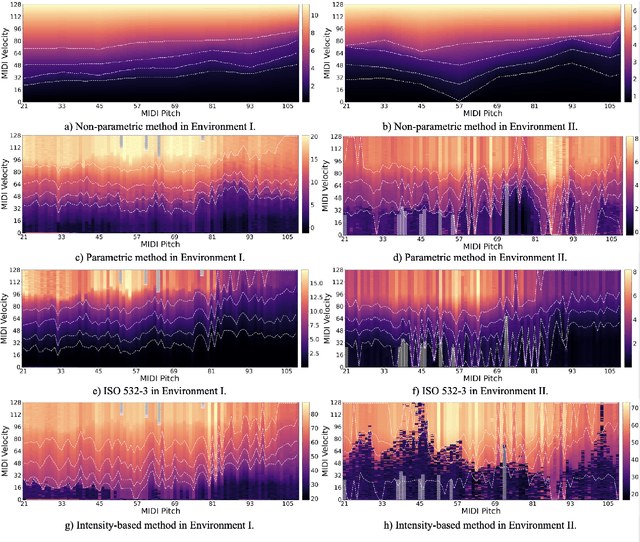
The relationship between perceptual loudness and physical attributes of sound is an important subject in both computer music and psychoacoustics. Early studies of "equal-loudness contour" can trace back to the 1920s and the measured loudness with respect to intensity and frequency has been revised many times since then. However, most studies merely focus on synthesized sound, and the induced theories on natural tones with complex timbre have rarely been justified. To this end, we investigate both theory and applications of natural-tone loudness perception in this paper via modeling piano tone. The theory part contains: 1) an accurate measurement of piano-tone equal-loudness contour of pitches, and 2) a machine-learning model capable of inferring loudness purely based on spectral features trained on human subject measurements. As for the application, we apply our theory to piano control transfer, in which we adjust the MIDI velocities on two different player pianos (in different acoustic environments) to achieve the same perceptual effect. Experiments show that both our theoretical loudness modeling and the corresponding performance control transfer algorithm significantly outperform their baselines.
A Categorical Approach for Recognizing Emotional Effects of Music
Sep 17, 2017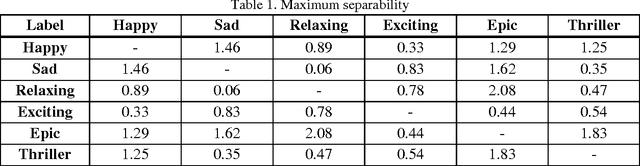
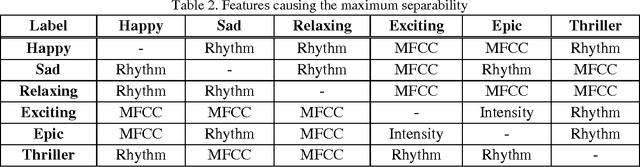


Recently, digital music libraries have been developed and can be plainly accessed. Latest research showed that current organization and retrieval of music tracks based on album information are inefficient. Moreover, they demonstrated that people use emotion tags for music tracks in order to search and retrieve them. In this paper, we discuss separability of a set of emotional labels, proposed in the categorical emotion expression, using Fisher's separation theorem. We determine a set of adjectives to tag music parts: happy, sad, relaxing, exciting, epic and thriller. Temporal, frequency and energy features have been extracted from the music parts. It could be seen that the maximum separability within the extracted features occurs between relaxing and epic music parts. Finally, we have trained a classifier using Support Vector Machines to automatically recognize and generate emotional labels for a music part. Accuracy for recognizing each label has been calculated; where the results show that epic music can be recognized more accurately (77.4%), comparing to the other types of music.
Deep Learning Based DOA Estimation for Hybrid Massive MIMO Receive Array with Overlapped Subarrays
Sep 11, 2022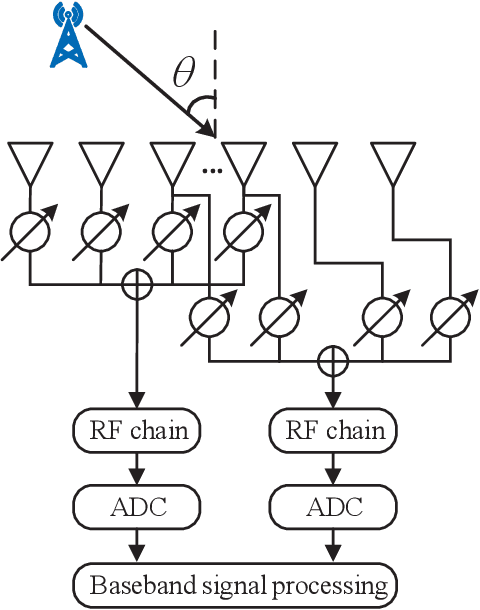
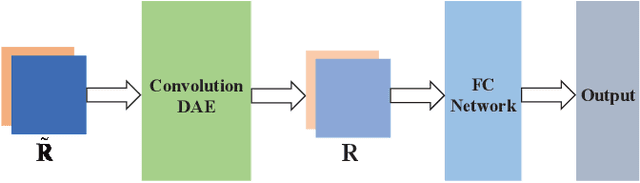
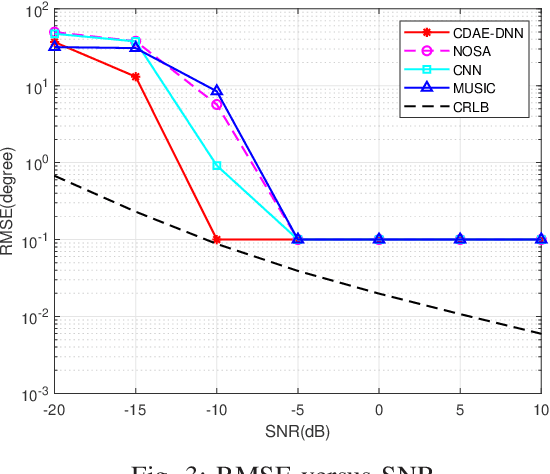
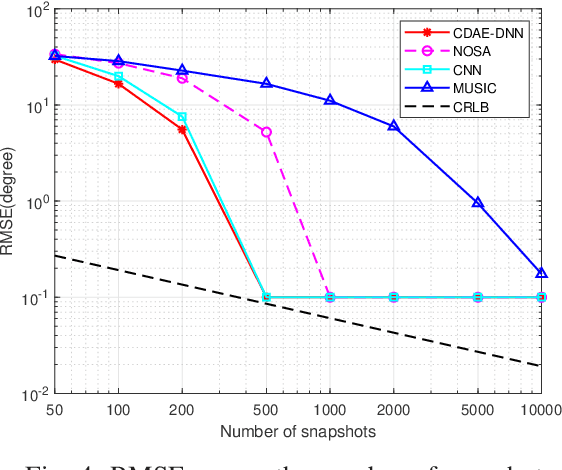
To improve the accuracy of direction-of-arrival (DOA) estimation, a deep learning (DL)-based method called CDAE-DNN is proposed for hybrid analog and digital (HAD) massive MIMO receive array with overlapped subarray (OSA) architecture in this paper. In the proposed method, the sample covariance matrix (SCM) is first input to a convolution denoise autoencoder (CDAE) to remove the approximation error, then the output of CDAE is imported to a fully-connected (FC) network to get the estimation result. Based on the simulation results, the proposed CDAE-DNN has great performance advantages over traditional MUSIC algorithm and CNN-based method, especially in the situations with low signal to noise ratio (SNR) and low snapshot numbers. And the OSA architecture has also been shown to significantly improve the estimation accuracy compared to non-overlapped subarray (NOSA) architecture. In addition, the Cramer-Rao lower bound (CRLB) for the HAD-OSA architecture is presented.
A Brief History of Recommender Systems
Sep 05, 2022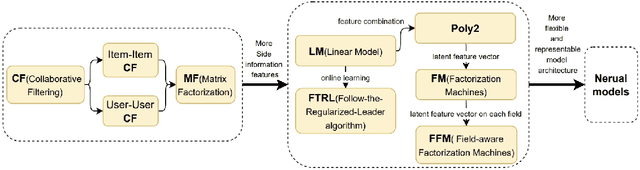
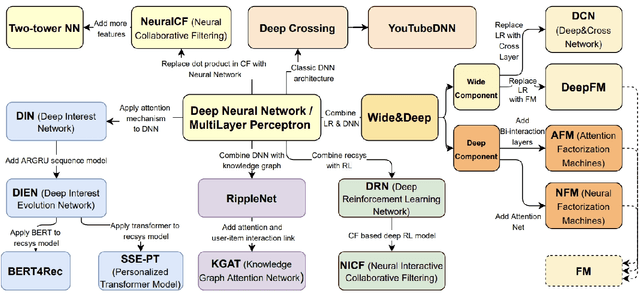
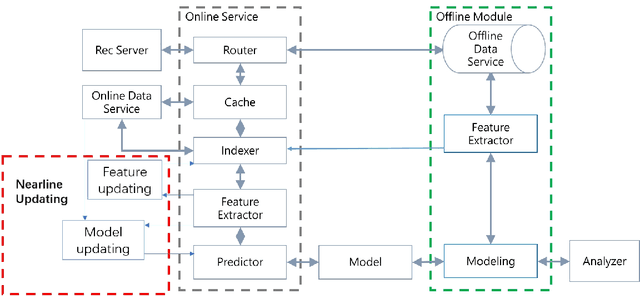
Soon after the invention of the Internet, the recommender system emerged and related technologies have been extensively studied and applied by both academia and industry. Currently, recommender system has become one of the most successful web applications, serving billions of people in each day through recommending different kinds of contents, including news feeds, videos, e-commerce products, music, movies, books, games, friends, jobs etc. These successful stories have proved that recommender system can transfer big data to high values. This article briefly reviews the history of web recommender systems, mainly from two aspects: (1) recommendation models, (2) architectures of typical recommender systems. We hope the brief review can help us to know the dots about the progress of web recommender systems, and the dots will somehow connect in the future, which inspires us to build more advanced recommendation services for changing the world better.
SUSing: SU-net for Singing Voice Synthesis
May 24, 2022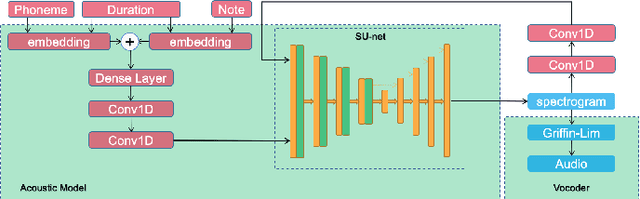
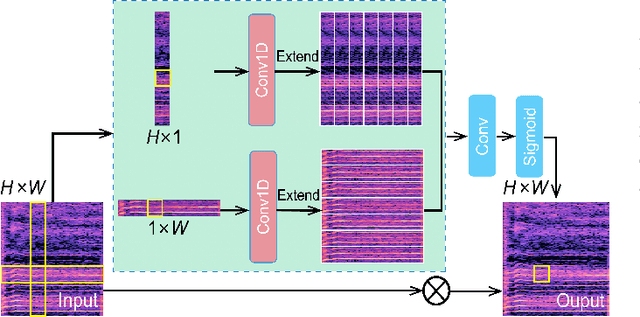
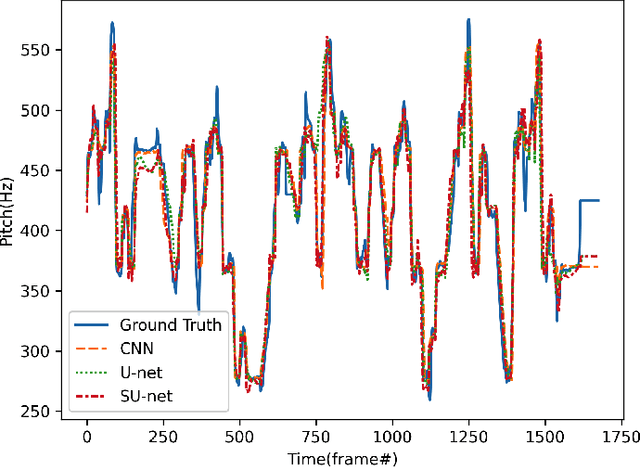
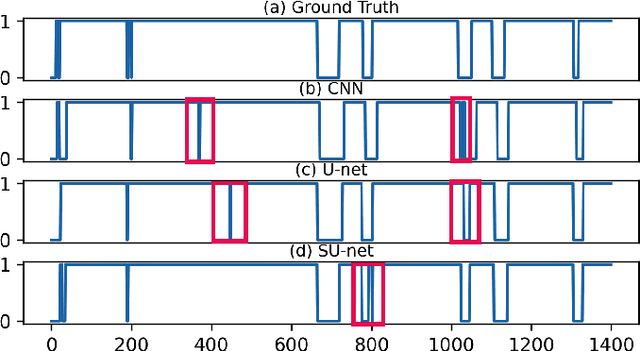
Singing voice synthesis is a generative task that involves multi-dimensional control of the singing model, including lyrics, pitch, and duration, and includes the timbre of the singer and singing skills such as vibrato. In this paper, we proposed SU-net for singing voice synthesis named SUSing. Synthesizing singing voice is treated as a translation task between lyrics and music score and spectrum. The lyrics and music score information is encoded into a two-dimensional feature representation through the convolution layer. The two-dimensional feature and its frequency spectrum are mapped to the target spectrum in an autoregressive manner through a SU-net network. Within the SU-net the stripe pooling method is used to replace the alternate global pooling method to learn the vertical frequency relationship in the spectrum and the changes of frequency in the time domain. The experimental results on the public dataset Kiritan show that the proposed method can synthesize more natural singing voices.
Tunable high-resolution synthetic aperture radar imaging
Aug 02, 2022
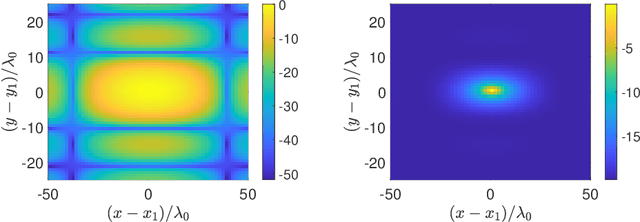
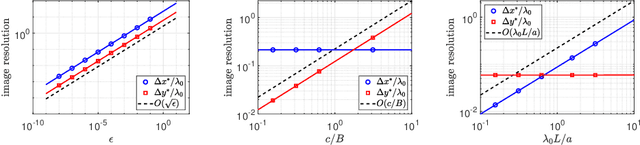
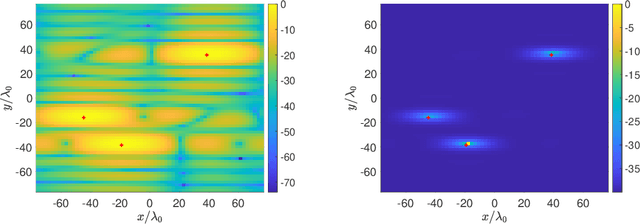
We have recently introduced a modification of the multiple signal classification (MUSIC) method for synthetic aperture radar. This method depends on a tunable, user-defined parameter, $\epsilon$, that allows for quantitative high-resolution imaging. It requires however, relative large single-to-noise ratios (SNR) to work effectively. Here, we first identify the fundamental mechanism in that method that produces high-resolution images. Then we introduce a modification to Kirchhoff Migration (KM) that uses the same mechanism to produces tunable, high-resolution images. This modified KM method can be applied to low SNR measurements. We show simulation results that demonstrate the features of this method.
Towards Score Following in Sheet Music Images
Dec 15, 2016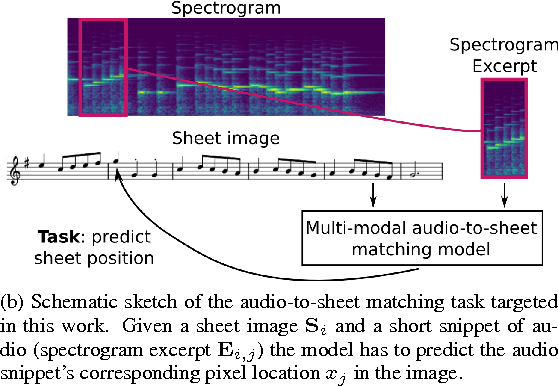

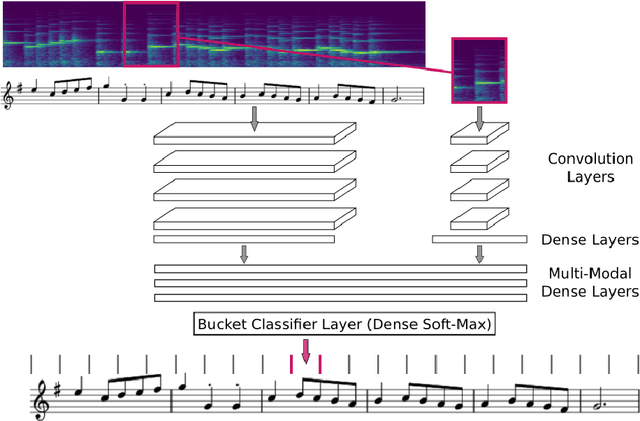
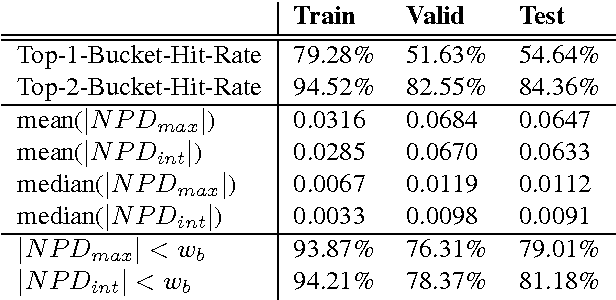
This paper addresses the matching of short music audio snippets to the corresponding pixel location in images of sheet music. A system is presented that simultaneously learns to read notes, listens to music and matches the currently played music to its corresponding notes in the sheet. It consists of an end-to-end multi-modal convolutional neural network that takes as input images of sheet music and spectrograms of the respective audio snippets. It learns to predict, for a given unseen audio snippet (covering approximately one bar of music), the corresponding position in the respective score line. Our results suggest that with the use of (deep) neural networks -- which have proven to be powerful image processing models -- working with sheet music becomes feasible and a promising future research direction.
Zero-shot Learning and Knowledge Transfer in Music Classification and Tagging
Jun 20, 2019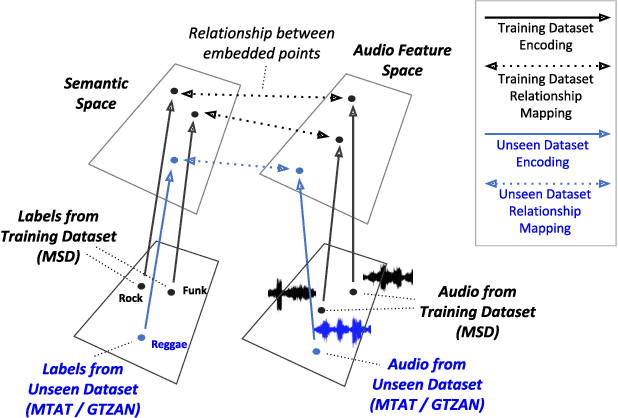
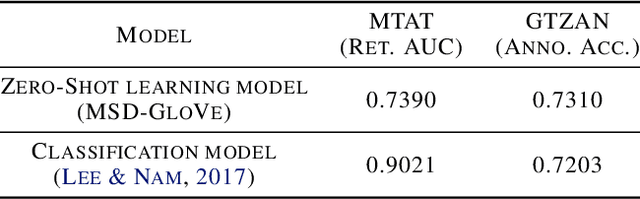
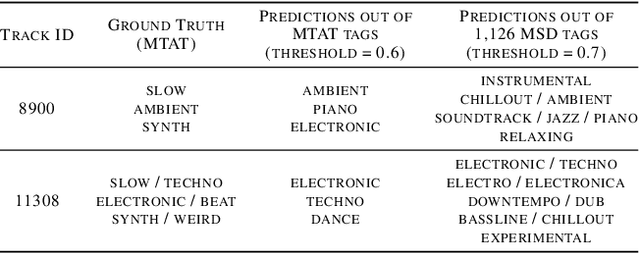

Music classification and tagging is conducted through categorical supervised learning with a fixed set of labels. In principle, this cannot make predictions on unseen labels. Zero-shot learning is an approach to solve the problem by using side information about the semantic labels. We recently investigated this concept of zero-shot learning in music classification and tagging task by projecting both audio and label space on a single semantic space. In this work, we extend the work to verify the generalization ability of zero-shot learning model by conducting knowledge transfer to different music corpora.
Pop Music Highlighter: Marking the Emotion Keypoints
Sep 25, 2018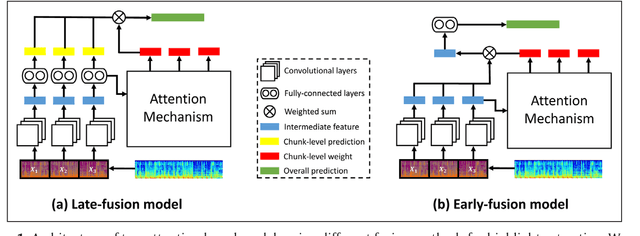
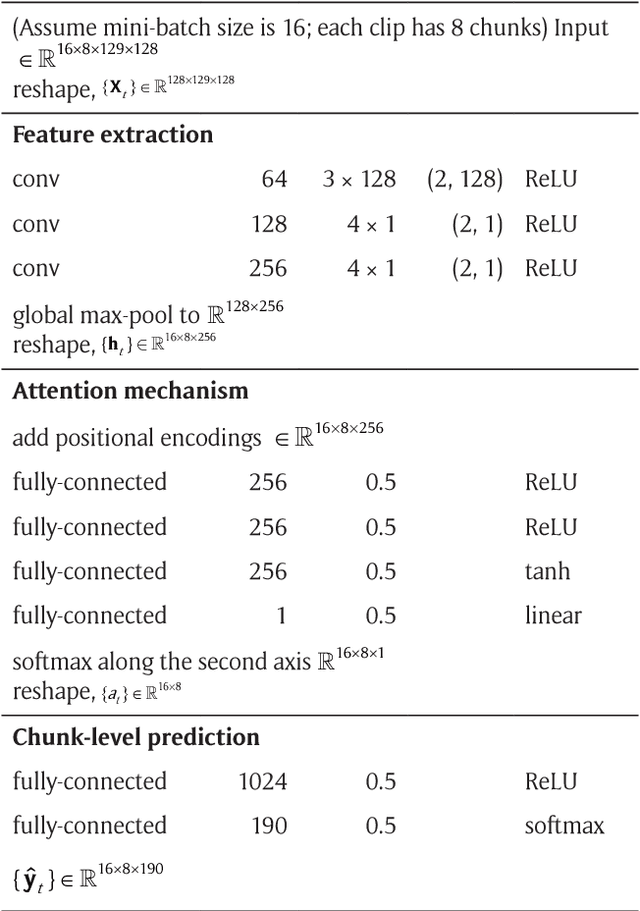
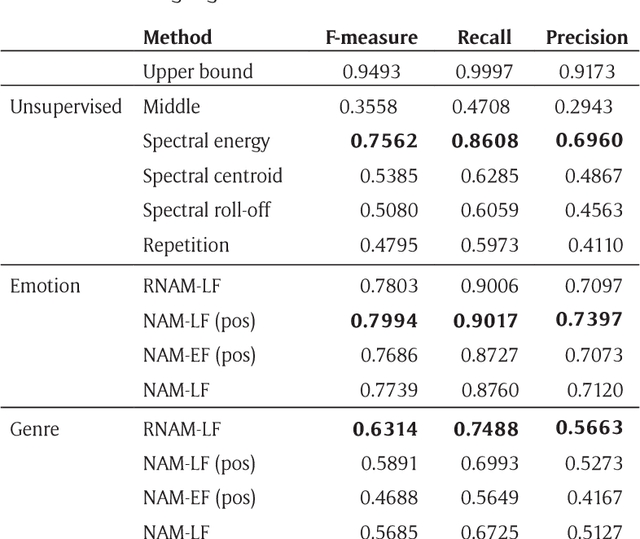
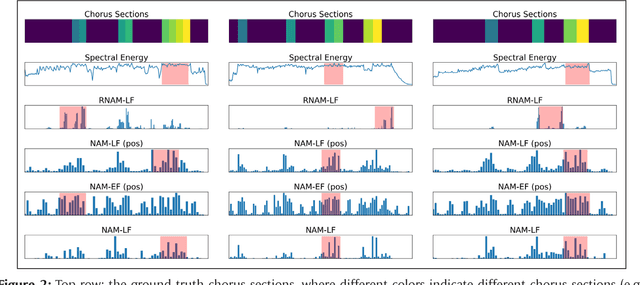
The goal of music highlight extraction is to get a short consecutive segment of a piece of music that provides an effective representation of the whole piece. In a previous work, we introduced an attention-based convolutional recurrent neural network that uses music emotion classification as a surrogate task for music highlight extraction, for Pop songs. The rationale behind that approach is that the highlight of a song is usually the most emotional part. This paper extends our previous work in the following two aspects. First, methodology-wise we experiment with a new architecture that does not need any recurrent layers, making the training process faster. Moreover, we compare a late-fusion variant and an early-fusion variant to study which one better exploits the attention mechanism. Second, we conduct and report an extensive set of experiments comparing the proposed attention-based methods against a heuristic energy-based method, a structural repetition-based method, and a few other simple feature-based methods for this task. Due to the lack of public-domain labeled data for highlight extraction, following our previous work we use the RWC POP 100-song data set to evaluate how the detected highlights overlap with any chorus sections of the songs. The experiments demonstrate the effectiveness of our methods over competing methods. For reproducibility, we open source the code and pre-trained model at https://github.com/remyhuang/pop-music-highlighter/.