 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
LAFS: Landmark-based Facial Self-supervised Learning for Face Recognition
Mar 13, 2024
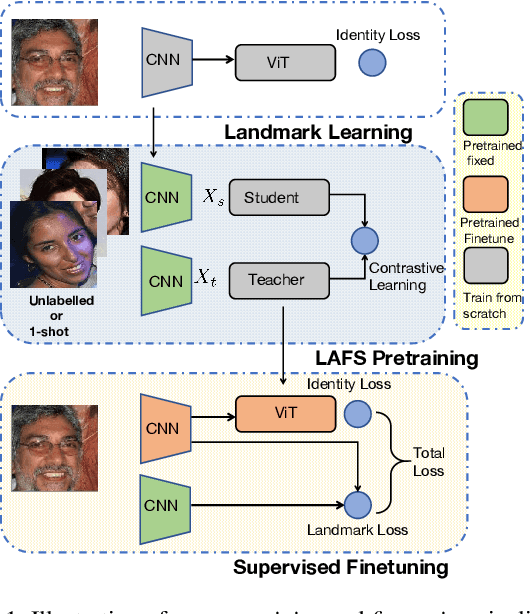
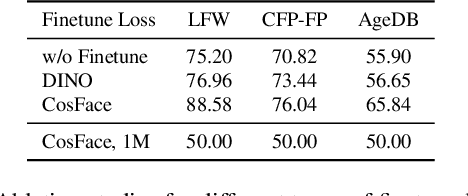
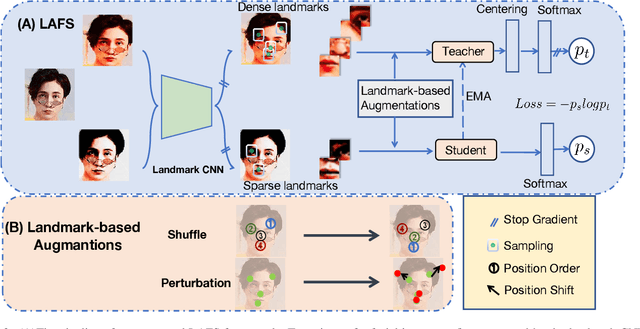
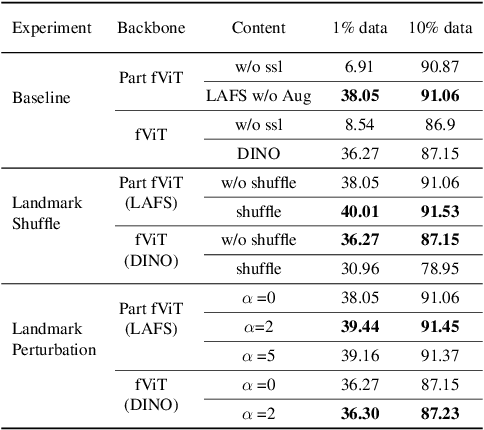
In this work we focus on learning facial representations that can be adapted to train effective face recognition models, particularly in the absence of labels. Firstly, compared with existing labelled face datasets, a vastly larger magnitude of unlabeled faces exists in the real world. We explore the learning strategy of these unlabeled facial images through self-supervised pretraining to transfer generalized face recognition performance. Moreover, motivated by one recent finding, that is, the face saliency area is critical for face recognition, in contrast to utilizing random cropped blocks of images for constructing augmentations in pretraining, we utilize patches localized by extracted facial landmarks. This enables our method - namely LAndmark-based Facial Self-supervised learning LAFS), to learn key representation that is more critical for face recognition. We also incorporate two landmark-specific augmentations which introduce more diversity of landmark information to further regularize the learning. With learned landmark-based facial representations, we further adapt the representation for face recognition with regularization mitigating variations in landmark positions. Our method achieves significant improvement over the state-of-the-art on multiple face recognition benchmarks, especially on more challenging few-shot scenarios.
Toward Tiny and High-quality Facial Makeup with Data Amplify Learning
Mar 22, 2024Contemporary makeup approaches primarily hinge on unpaired learning paradigms, yet they grapple with the challenges of inaccurate supervision (e.g., face misalignment) and sophisticated facial prompts (including face parsing, and landmark detection). These challenges prohibit low-cost deployment of facial makeup models, especially on mobile devices. To solve above problems, we propose a brand-new learning paradigm, termed "Data Amplify Learning (DAL)," alongside a compact makeup model named "TinyBeauty." The core idea of DAL lies in employing a Diffusion-based Data Amplifier (DDA) to "amplify" limited images for the model training, thereby enabling accurate pixel-to-pixel supervision with merely a handful of annotations. Two pivotal innovations in DDA facilitate the above training approach: (1) A Residual Diffusion Model (RDM) is designed to generate high-fidelity detail and circumvent the detail vanishing problem in the vanilla diffusion models; (2) A Fine-Grained Makeup Module (FGMM) is proposed to achieve precise makeup control and combination while retaining face identity. Coupled with DAL, TinyBeauty necessitates merely 80K parameters to achieve a state-of-the-art performance without intricate face prompts. Meanwhile, TinyBeauty achieves a remarkable inference speed of up to 460 fps on the iPhone 13. Extensive experiments show that DAL can produce highly competitive makeup models using only 5 image pairs.
AI-KD: Towards Alignment Invariant Face Image Quality Assessment Using Knowledge Distillation
Apr 15, 2024Face Image Quality Assessment (FIQA) techniques have seen steady improvements over recent years, but their performance still deteriorates if the input face samples are not properly aligned. This alignment sensitivity comes from the fact that most FIQA techniques are trained or designed using a specific face alignment procedure. If the alignment technique changes, the performance of most existing FIQA techniques quickly becomes suboptimal. To address this problem, we present in this paper a novel knowledge distillation approach, termed AI-KD that can extend on any existing FIQA technique, improving its robustness to alignment variations and, in turn, performance with different alignment procedures. To validate the proposed distillation approach, we conduct comprehensive experiments on 6 face datasets with 4 recent face recognition models and in comparison to 7 state-of-the-art FIQA techniques. Our results show that AI-KD consistently improves performance of the initial FIQA techniques not only with misaligned samples, but also with properly aligned facial images. Furthermore, it leads to a new state-of-the-art, when used with a competitive initial FIQA approach. The code for AI-KD is made publicly available from: https://github.com/LSIbabnikz/AI-KD.
rFaceNet: An End-to-End Network for Enhanced Physiological Signal Extraction through Identity-Specific Facial Contours
Mar 14, 2024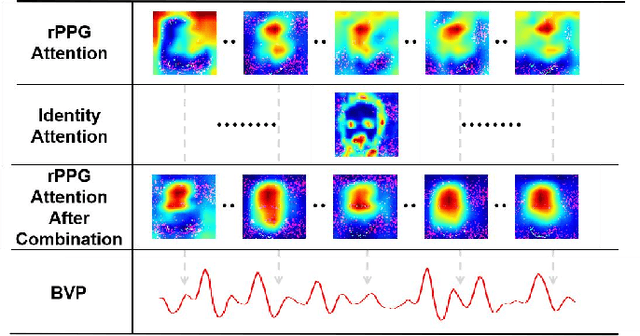
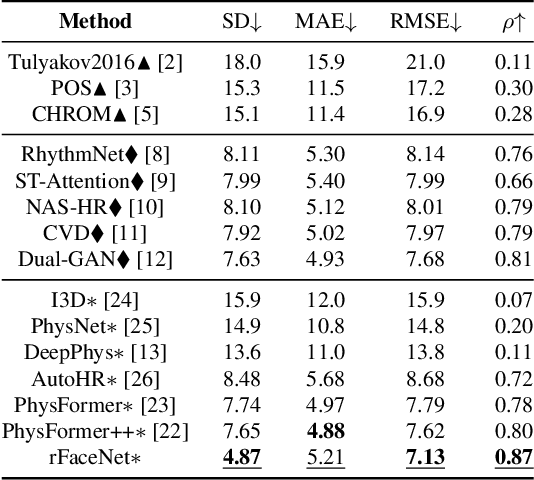
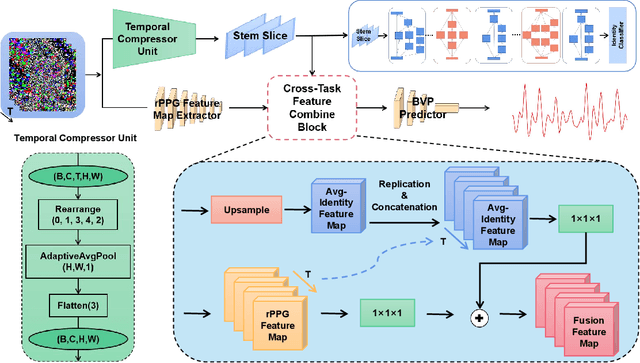
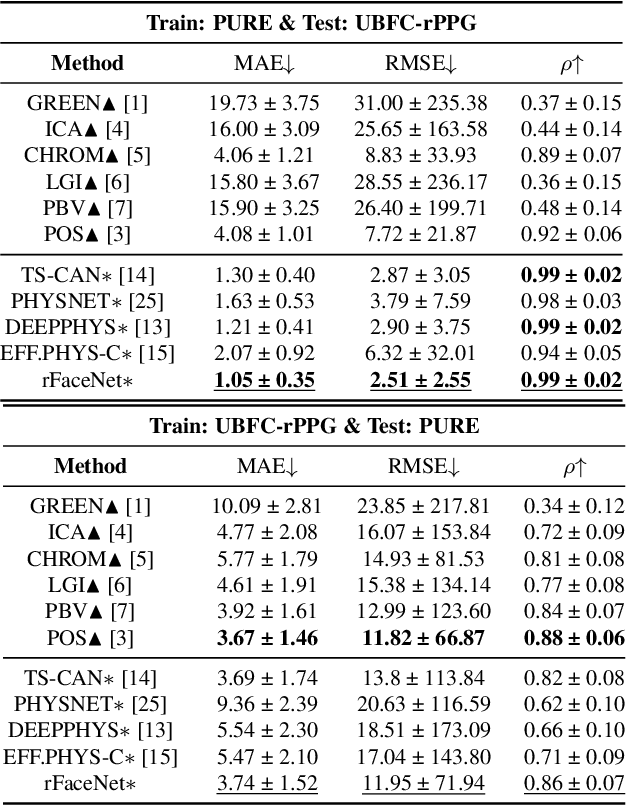
Remote photoplethysmography (rPPG) technique extracts blood volume pulse (BVP) signals from subtle pixel changes in video frames. This study introduces rFaceNet, an advanced rPPG method that enhances the extraction of facial BVP signals with a focus on facial contours. rFaceNet integrates identity-specific facial contour information and eliminates redundant data. It efficiently extracts facial contours from temporally normalized frame inputs through a Temporal Compressor Unit (TCU) and steers the model focus to relevant facial regions by using the Cross-Task Feature Combiner (CTFC). Through elaborate training, the quality and interpretability of facial physiological signals extracted by rFaceNet are greatly improved compared to previous methods. Moreover, our novel approach demonstrates superior performance than SOTA methods in various heart rate estimation benchmarks.
Leveraging Synthetic Data for Generalizable and Fair Facial Action Unit Detection
Mar 15, 2024

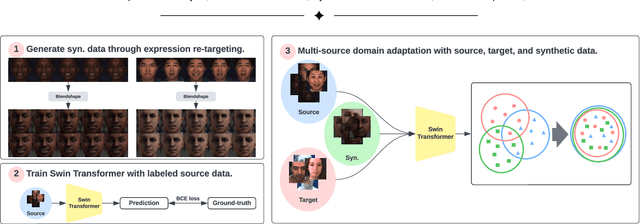
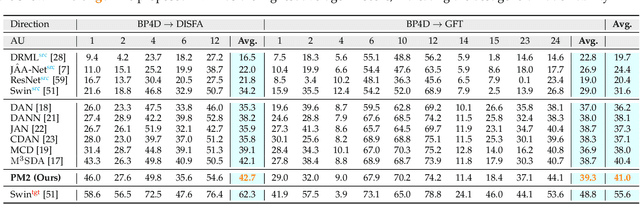
Facial action unit (AU) detection is a fundamental block for objective facial expression analysis. Supervised learning approaches require a large amount of manual labeling which is costly. The limited labeled data are also not diverse in terms of gender which can affect model fairness. In this paper, we propose to use synthetically generated data and multi-source domain adaptation (MSDA) to address the problems of the scarcity of labeled data and the diversity of subjects. Specifically, we propose to generate a diverse dataset through synthetic facial expression re-targeting by transferring the expressions from real faces to synthetic avatars. Then, we use MSDA to transfer the AU detection knowledge from a real dataset and the synthetic dataset to a target dataset. Instead of aligning the overall distributions of different domains, we propose Paired Moment Matching (PM2) to align the features of the paired real and synthetic data with the same facial expression. To further improve gender fairness, PM2 matches the features of the real data with a female and a male synthetic image. Our results indicate that synthetic data and the proposed model improve both AU detection performance and fairness across genders, demonstrating its potential to solve AU detection in-the-wild.
HSEmotion Team at the 6th ABAW Competition: Facial Expressions, Valence-Arousal and Emotion Intensity Prediction
Mar 18, 2024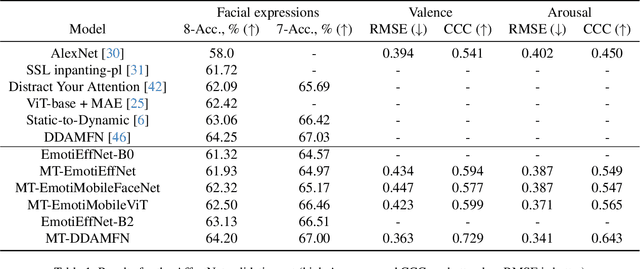
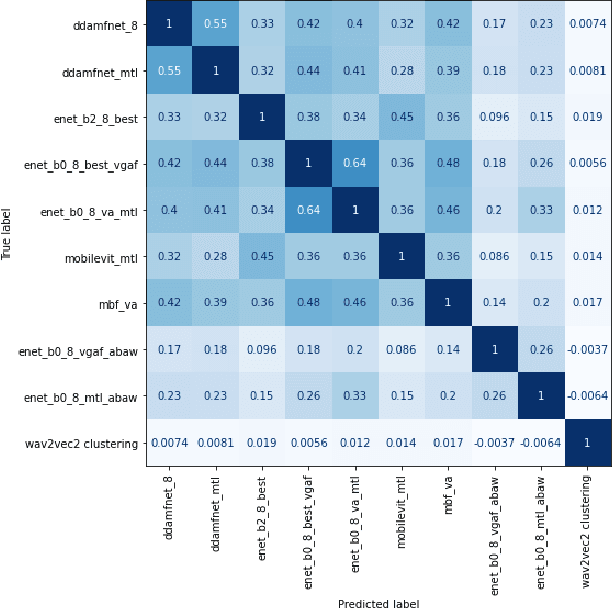
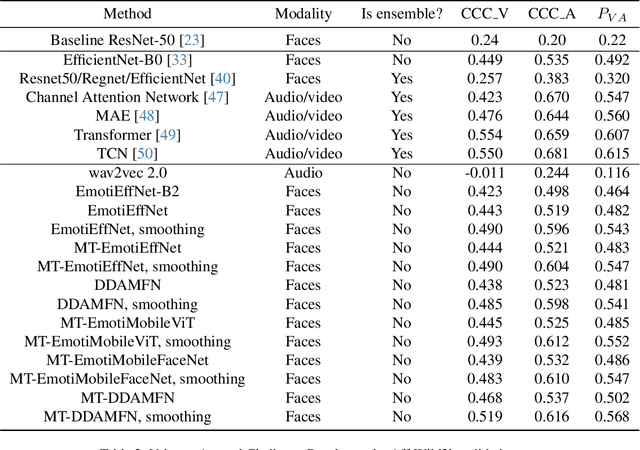
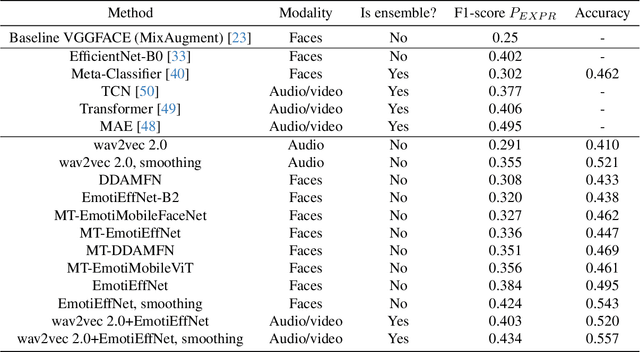
This article presents our results for the sixth Affective Behavior Analysis in-the-wild (ABAW) competition. To improve the trustworthiness of facial analysis, we study the possibility of using pre-trained deep models that extract reliable emotional features without the need to fine-tune the neural networks for a downstream task. In particular, we introduce several lightweight models based on MobileViT, MobileFaceNet, EfficientNet, and DDAMFN architectures trained in multi-task scenarios to recognize facial expressions, valence, and arousal on static photos. These neural networks extract frame-level features fed into a simple classifier, e.g., linear feed-forward neural network, to predict emotion intensity, compound expressions, action units, facial expressions, and valence/arousal. Experimental results for five tasks from the sixth ABAW challenge demonstrate that our approach lets us significantly improve quality metrics on validation sets compared to existing non-ensemble techniques.
Comparing Apples to Oranges: LLM-powered Multimodal Intention Prediction in an Object Categorization Task
Apr 12, 2024Intention-based Human-Robot Interaction (HRI) systems allow robots to perceive and interpret user actions to proactively interact with humans and adapt to their behavior. Therefore, intention prediction is pivotal in creating a natural interactive collaboration between humans and robots. In this paper, we examine the use of Large Language Models (LLMs) for inferring human intention during a collaborative object categorization task with a physical robot. We introduce a hierarchical approach for interpreting user non-verbal cues, like hand gestures, body poses, and facial expressions and combining them with environment states and user verbal cues captured using an existing Automatic Speech Recognition (ASR) system. Our evaluation demonstrates the potential of LLMs to interpret non-verbal cues and to combine them with their context-understanding capabilities and real-world knowledge to support intention prediction during human-robot interaction.
Joint Contrastive Learning with Feature Alignment for Cross-Corpus EEG-based Emotion Recognition
Apr 15, 2024The integration of human emotions into multimedia applications shows great potential for enriching user experiences and enhancing engagement across various digital platforms. Unlike traditional methods such as questionnaires, facial expressions, and voice analysis, brain signals offer a more direct and objective understanding of emotional states. However, in the field of electroencephalography (EEG)-based emotion recognition, previous studies have primarily concentrated on training and testing EEG models within a single dataset, overlooking the variability across different datasets. This oversight leads to significant performance degradation when applying EEG models to cross-corpus scenarios. In this study, we propose a novel Joint Contrastive learning framework with Feature Alignment (JCFA) to address cross-corpus EEG-based emotion recognition. The JCFA model operates in two main stages. In the pre-training stage, a joint domain contrastive learning strategy is introduced to characterize generalizable time-frequency representations of EEG signals, without the use of labeled data. It extracts robust time-based and frequency-based embeddings for each EEG sample, and then aligns them within a shared latent time-frequency space. In the fine-tuning stage, JCFA is refined in conjunction with downstream tasks, where the structural connections among brain electrodes are considered. The model capability could be further enhanced for the application in emotion detection and interpretation. Extensive experimental results on two well-recognized emotional datasets show that the proposed JCFA model achieves state-of-the-art (SOTA) performance, outperforming the second-best method by an average accuracy increase of 4.09% in cross-corpus EEG-based emotion recognition tasks.
Customizable Avatars with Dynamic Facial Action Coded Expressions (CADyFACE) for Improved User Engagement
Mar 12, 2024

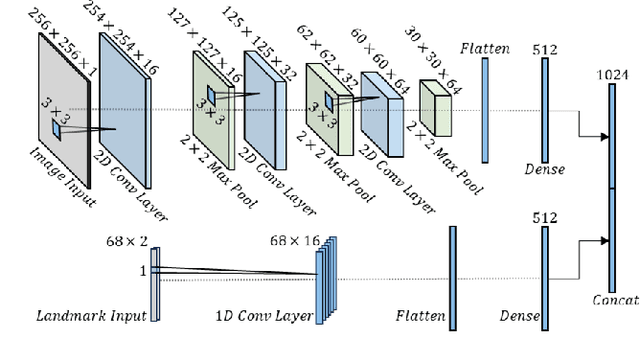
Customizable 3D avatar-based facial expression stimuli may improve user engagement in behavioral biomarker discovery and therapeutic intervention for autism, Alzheimer's disease, facial palsy, and more. However, there is a lack of customizable avatar-based stimuli with Facial Action Coding System (FACS) action unit (AU) labels. Therefore, this study focuses on (1) FACS-labeled, customizable avatar-based expression stimuli for maintaining subjects' engagement, (2) learning-based measurements that quantify subjects' facial responses to such stimuli, and (3) validation of constructs represented by stimulus-measurement pairs. We propose Customizable Avatars with Dynamic Facial Action Coded Expressions (CADyFACE) labeled with AUs by a certified FACS expert. To measure subjects' AUs in response to CADyFACE, we propose a novel Beta-guided Correlation and Multi-task Expression learning neural network (BeCoME-Net) for multi-label AU detection. The beta-guided correlation loss encourages feature correlation with AUs while discouraging correlation with subject identities for improved generalization. We train BeCoME-Net for unilateral and bilateral AU detection and compare with state-of-the-art approaches. To assess construct validity of CADyFACE and BeCoME-Net, twenty healthy adult volunteers complete expression recognition and mimicry tasks in an online feasibility study while webcam-based eye-tracking and video are collected. We test validity of multiple constructs, including face preference during recognition and AUs during mimicry.
DiffusionFace: Towards a Comprehensive Dataset for Diffusion-Based Face Forgery Analysis
Mar 27, 2024The rapid progress in deep learning has given rise to hyper-realistic facial forgery methods, leading to concerns related to misinformation and security risks. Existing face forgery datasets have limitations in generating high-quality facial images and addressing the challenges posed by evolving generative techniques. To combat this, we present DiffusionFace, the first diffusion-based face forgery dataset, covering various forgery categories, including unconditional and Text Guide facial image generation, Img2Img, Inpaint, and Diffusion-based facial exchange algorithms. Our DiffusionFace dataset stands out with its extensive collection of 11 diffusion models and the high-quality of the generated images, providing essential metadata and a real-world internet-sourced forgery facial image dataset for evaluation. Additionally, we provide an in-depth analysis of the data and introduce practical evaluation protocols to rigorously assess discriminative models' effectiveness in detecting counterfeit facial images, aiming to enhance security in facial image authentication processes. The dataset is available for download at \url{https://github.com/Rapisurazurite/DiffFace}.