 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Human Diving Endurance with a Field-Deployable, Untethered Exoskeleton
Jun 10, 2026Human endurance in underwater locomotion is fundamentally restricted by high energetic demands to overcome drag and the finite supply of self-contained breathing gas. While exoskeleton technology can reduce the metabolic cost of humans in terrestrial locomotion, its potential to enhance human endurance during underwater diving remains entirely unexplored. Here, we present DiveMate, a field-deployable, untethered exoskeleton designed to improve human diving endurance via adaptive kick assistance in real-world underwater environments. During naturalistic diving, DiveMate increases the travel distance using a given energy (breathing gas) by 42.9% and extends dive duration by 54.9% through reducing gas consumption rate. Marked reductions in muscle activation indicate a decrease in physiological exertion, with the net gas consumption rate decreasing by 47.0%. Kinematic characteristics and regularity improvements further underpin efficient energy economy. These results suggest that applying exoskeleton assistance is beneficial for improving human diving endurance and augmenting their ability to explore the aquatic world. This study extends the application frontier of exoskeletons and provides a potential reference for the design and assessment of future underwater assistive devices.
EEGDancer: Dynamic Emotion Latent Space Masked Modeling with Reinforcement Learning for EEG Continuous Emotion Prediction
Jun 04, 2026Continuous electroencephalography (EEG) emotion prediction aims to model the temporal evolution of human emotional states from EEG signals. Unlike conventional discrete emotion recognition, continuous prediction requires capturing long-range temporal dependencies and coherent emotional dynamics. However, existing methods mainly rely on point-wise regression and directly model noisy high-dimensional EEG features, limiting their ability to characterize continuous emotional evolution.To address these challenges, we propose EEGDancer, a dynamic emotional latent space learning framework for continuous EEG emotion prediction. The framework integrates vector-quantized representation learning, masked temporal modeling, and reinforcement learning-based trajectory optimization into a unified architecture.Specifically, a causal spatiotemporal Vector-Quantization Variational Autoencoder (VQ-VAE) is designed to learn structured emotional prototypes and construct a discrete-continuous emotional latent space from EEG signals. Based on the learned latent representations, a Transformer-based masked dynamic modeling strategy captures long-range emotional dependencies and temporal evolution patterns. Furthermore, continuous emotion prediction is formulated as a sequential decision-making problem, and a Soft Actor-Critic (SAC) framework is introduced to optimize emotional prediction trajectories at the sequence level instead of frame-wise local fitting.Extensive experiments on the SEED, SEED-IV, and Long-Term Naturalistic Emotion datasets demonstrate that EEGDancer consistently outperforms existing machine learning and deep learning methods. Ablation studies further verify the effectiveness of the proposed latent space and reinforcement learning-based trajectory optimization for modeling continuous EEG emotional dynamics.
Neural Tangent Knowledge Distillation for Optical Convolutional Networks
Aug 11, 2025Hybrid Optical Neural Networks (ONNs, typically consisting of an optical frontend and a digital backend) offer an energy-efficient alternative to fully digital deep networks for real-time, power-constrained systems. However, their adoption is limited by two main challenges: the accuracy gap compared to large-scale networks during training, and discrepancies between simulated and fabricated systems that further degrade accuracy. While previous work has proposed end-to-end optimizations for specific datasets (e.g., MNIST) and optical systems, these approaches typically lack generalization across tasks and hardware designs. To address these limitations, we propose a task-agnostic and hardware-agnostic pipeline that supports image classification and segmentation across diverse optical systems. To assist optical system design before training, we estimate achievable model accuracy based on user-specified constraints such as physical size and the dataset. For training, we introduce Neural Tangent Knowledge Distillation (NTKD), which aligns optical models with electronic teacher networks, thereby narrowing the accuracy gap. After fabrication, NTKD also guides fine-tuning of the digital backend to compensate for implementation errors. Experiments on multiple datasets (e.g., MNIST, CIFAR, Carvana Masking) and hardware configurations show that our pipeline consistently improves ONN performance and enables practical deployment in both pre-fabrication simulations and physical implementations.
An Illumination-Robust Feature Extractor Augmented by Relightable 3D Reconstruction
Oct 01, 2024
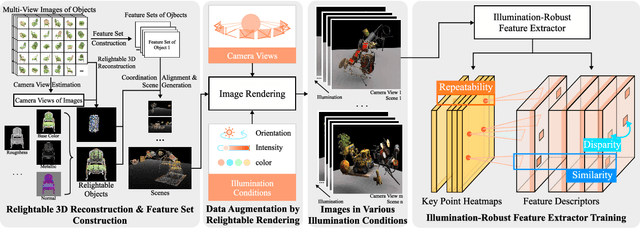


Visual features, whose description often relies on the local intensity and gradient direction, have found wide applications in robot navigation and localization in recent years. However, the extraction of visual features is usually disturbed by the variation of illumination conditions, making it challenging for real-world applications. Previous works have addressed this issue by establishing datasets with variations in illumination conditions, but can be costly and time-consuming. This paper proposes a design procedure for an illumination-robust feature extractor, where the recently developed relightable 3D reconstruction techniques are adopted for rapid and direct data generation with varying illumination conditions. A self-supervised framework is proposed for extracting features with advantages in repeatability for key points and similarity for descriptors across good and bad illumination conditions. Experiments are conducted to demonstrate the effectiveness of the proposed method for robust feature extraction. Ablation studies also indicate the effectiveness of the self-supervised framework design.
Emotion-Agent: Unsupervised Deep Reinforcement Learning with Distribution-Prototype Reward for Continuous Emotional EEG Analysis
Aug 22, 2024Continuous electroencephalography (EEG) signals are widely used in affective brain-computer interface (aBCI) applications. However, not all continuously collected EEG signals are relevant or meaningful to the task at hand (e.g., wondering thoughts). On the other hand, manually labeling the relevant parts is nearly impossible due to varying engagement patterns across different tasks and individuals. Therefore, effectively and efficiently identifying the important parts from continuous EEG recordings is crucial for downstream BCI tasks, as it directly impacts the accuracy and reliability of the results. In this paper, we propose a novel unsupervised deep reinforcement learning framework, called Emotion-Agent, to automatically identify relevant and informative emotional moments from continuous EEG signals. Specifically, Emotion-Agent involves unsupervised deep reinforcement learning combined with a heuristic algorithm. We first use the heuristic algorithm to perform an initial global search and form prototype representations of the EEG signals, which facilitates the efficient exploration of the signal space and identify potential regions of interest. Then, we design distribution-prototype reward functions to estimate the interactions between samples and prototypes, ensuring that the identified parts are both relevant and representative of the underlying emotional states. Emotion-Agent is trained using Proximal Policy Optimization (PPO) to achieve stable and efficient convergence. Our experiments compare the performance with and without Emotion-Agent. The results demonstrate that selecting relevant and informative emotional parts before inputting them into downstream tasks enhances the accuracy and reliability of aBCI applications.
Joint Contrastive Learning with Feature Alignment for Cross-Corpus EEG-based Emotion Recognition
Apr 15, 2024The integration of human emotions into multimedia applications shows great potential for enriching user experiences and enhancing engagement across various digital platforms. Unlike traditional methods such as questionnaires, facial expressions, and voice analysis, brain signals offer a more direct and objective understanding of emotional states. However, in the field of electroencephalography (EEG)-based emotion recognition, previous studies have primarily concentrated on training and testing EEG models within a single dataset, overlooking the variability across different datasets. This oversight leads to significant performance degradation when applying EEG models to cross-corpus scenarios. In this study, we propose a novel Joint Contrastive learning framework with Feature Alignment (JCFA) to address cross-corpus EEG-based emotion recognition. The JCFA model operates in two main stages. In the pre-training stage, a joint domain contrastive learning strategy is introduced to characterize generalizable time-frequency representations of EEG signals, without the use of labeled data. It extracts robust time-based and frequency-based embeddings for each EEG sample, and then aligns them within a shared latent time-frequency space. In the fine-tuning stage, JCFA is refined in conjunction with downstream tasks, where the structural connections among brain electrodes are considered. The model capability could be further enhanced for the application in emotion detection and interpretation. Extensive experimental results on two well-recognized emotional datasets show that the proposed JCFA model achieves state-of-the-art (SOTA) performance, outperforming the second-best method by an average accuracy increase of 4.09% in cross-corpus EEG-based emotion recognition tasks.
HouYi: An open-source large language model specially designed for renewable energy and carbon neutrality field
Jul 31, 2023Renewable energy is important for achieving carbon neutrality goal. With the great success of Large Language Models (LLMs) like ChatGPT in automatic content generation, LLMs are playing an increasingly important role. However, there has not been a specially designed LLM for renewable energy. Meanwhile, there has not been any dataset of renewable energy for training LLMs. Therefore, this paper published the first open-source Renewable Energy Academic Paper (REAP) dataset for non-commercial LLM research of renewable energy. REAP dataset is collected through searching the title and abstract of 1,168,970 academic literatures from Web of Science. Based on REAP dataset, HouYi model, the first LLM for renewable energy, is developed through finetuning general LLMs. HouYi demonstrated powerful academic paper paragraph generation ability in renewable energy field. Experiments show that its ability to generate academic papers on renewable energy is comparable to ChatGPT, slightly outperforms Claude, ERNIE Bot and SparkDesk, and significantly outperforms open-source LLaMA-13B model.
Paper Abstract Writing through Editing Mechanism
May 15, 2018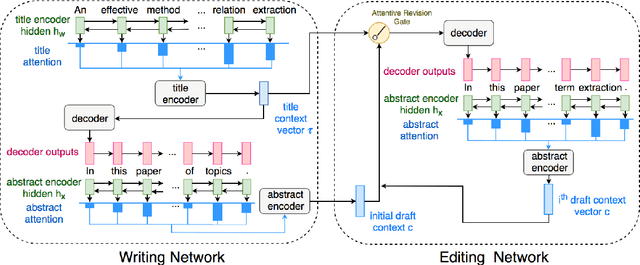
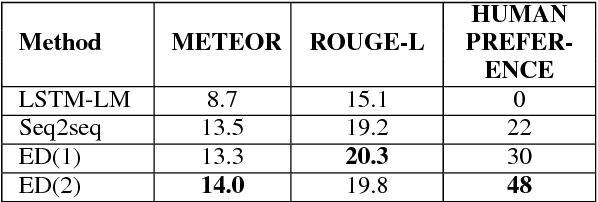
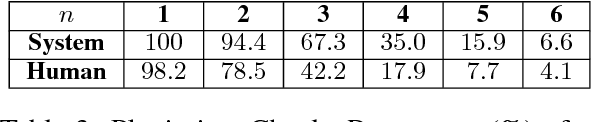
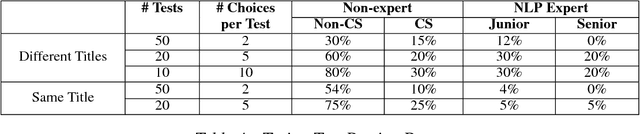
We present a paper abstract writing system based on an attentive neural sequence-to-sequence model that can take a title as input and automatically generate an abstract. We design a novel Writing-editing Network that can attend to both the title and the previously generated abstract drafts and then iteratively revise and polish the abstract. With two series of Turing tests, where the human judges are asked to distinguish the system-generated abstracts from human-written ones, our system passes Turing tests by junior domain experts at a rate up to 30% and by non-expert at a rate up to 80%.
Learning Phrase Embeddings from Paraphrases with GRUs
Oct 13, 2017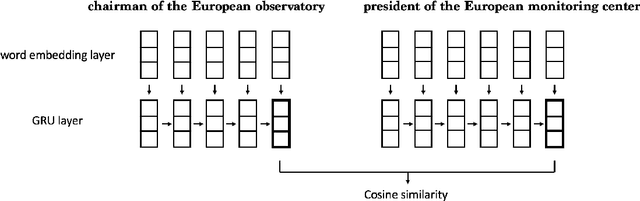
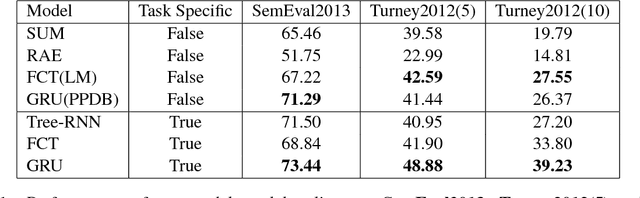
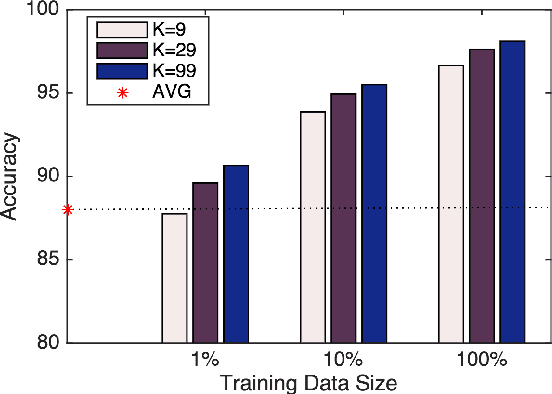

Learning phrase representations has been widely explored in many Natural Language Processing (NLP) tasks (e.g., Sentiment Analysis, Machine Translation) and has shown promising improvements. Previous studies either learn non-compositional phrase representations with general word embedding learning techniques or learn compositional phrase representations based on syntactic structures, which either require huge amounts of human annotations or cannot be easily generalized to all phrases. In this work, we propose to take advantage of large-scaled paraphrase database and present a pair-wise gated recurrent units (pairwise-GRU) framework to generate compositional phrase representations. Our framework can be re-used to generate representations for any phrases. Experimental results show that our framework achieves state-of-the-art results on several phrase similarity tasks.