 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"facial": models, code, and papers
Talking Head Generation with Audio and Speech Related Facial Action Units
Oct 19, 2021
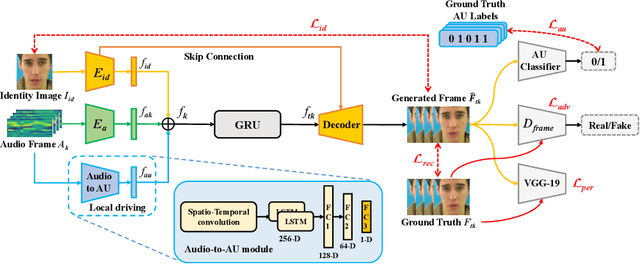
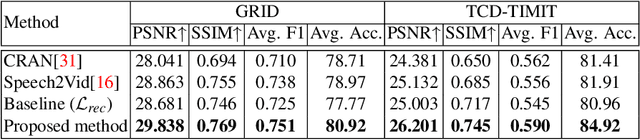


The task of talking head generation is to synthesize a lip synchronized talking head video by inputting an arbitrary face image and audio clips. Most existing methods ignore the local driving information of the mouth muscles. In this paper, we propose a novel recurrent generative network that uses both audio and speech-related facial action units (AUs) as the driving information. AU information related to the mouth can guide the movement of the mouth more accurately. Since speech is highly correlated with speech-related AUs, we propose an Audio-to-AU module in our system to predict the speech-related AU information from speech. In addition, we use AU classifier to ensure that the generated images contain correct AU information. Frame discriminator is also constructed for adversarial training to improve the realism of the generated face. We verify the effectiveness of our model on the GRID dataset and TCD-TIMIT dataset. We also conduct an ablation study to verify the contribution of each component in our model. Quantitative and qualitative experiments demonstrate that our method outperforms existing methods in both image quality and lip-sync accuracy.
Facial Expression Retargeting from Human to Avatar Made Easy
Aug 12, 2020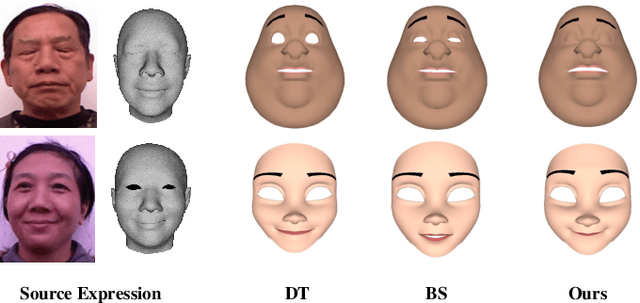

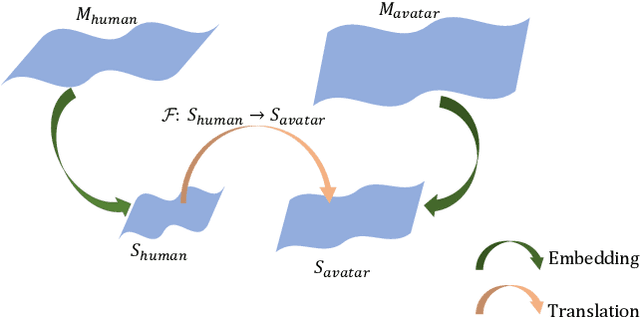
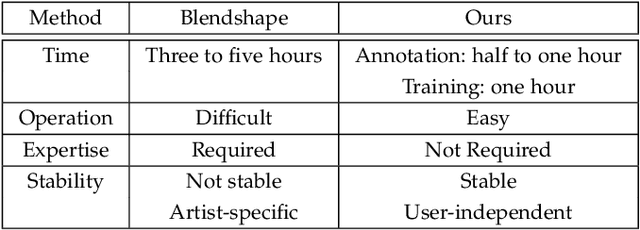
Facial expression retargeting from humans to virtual characters is a useful technique in computer graphics and animation. Traditional methods use markers or blendshapes to construct a mapping between the human and avatar faces. However, these approaches require a tedious 3D modeling process, and the performance relies on the modelers' experience. In this paper, we propose a brand-new solution to this cross-domain expression transfer problem via nonlinear expression embedding and expression domain translation. We first build low-dimensional latent spaces for the human and avatar facial expressions with variational autoencoder. Then we construct correspondences between the two latent spaces guided by geometric and perceptual constraints. Specifically, we design geometric correspondences to reflect geometric matching and utilize a triplet data structure to express users' perceptual preference of avatar expressions. A user-friendly method is proposed to automatically generate triplets for a system allowing users to easily and efficiently annotate the correspondences. Using both geometric and perceptual correspondences, we trained a network for expression domain translation from human to avatar. Extensive experimental results and user studies demonstrate that even nonprofessional users can apply our method to generate high-quality facial expression retargeting results with less time and effort.
Generative Neural Articulated Radiance Fields
Jun 28, 2022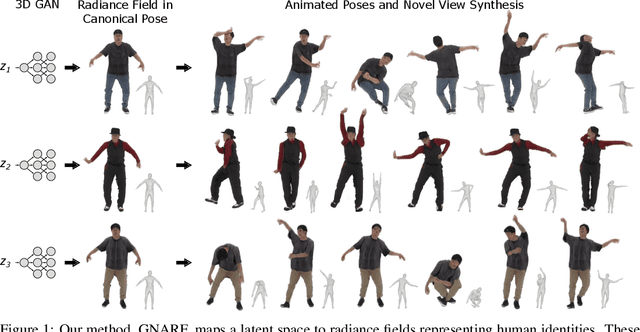
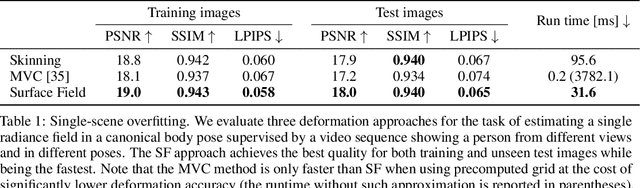
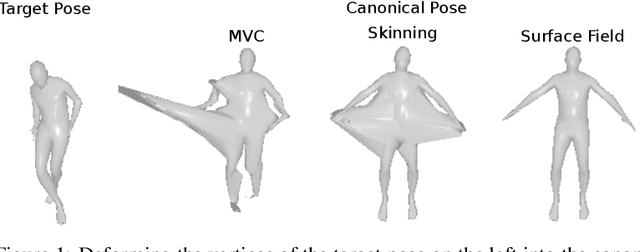
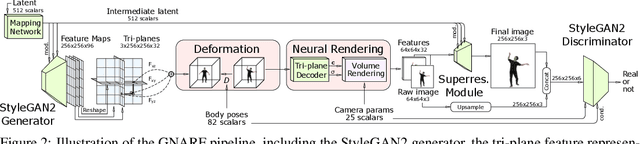
Unsupervised learning of 3D-aware generative adversarial networks (GANs) using only collections of single-view 2D photographs has very recently made much progress. These 3D GANs, however, have not been demonstrated for human bodies and the generated radiance fields of existing frameworks are not directly editable, limiting their applicability in downstream tasks. We propose a solution to these challenges by developing a 3D GAN framework that learns to generate radiance fields of human bodies or faces in a canonical pose and warp them using an explicit deformation field into a desired body pose or facial expression. Using our framework, we demonstrate the first high-quality radiance field generation results for human bodies. Moreover, we show that our deformation-aware training procedure significantly improves the quality of generated bodies or faces when editing their poses or facial expressions compared to a 3D GAN that is not trained with explicit deformations.
Bayesian Convolutional Neural Networks for Seven Basic Facial Expression Classifications
Jul 13, 2021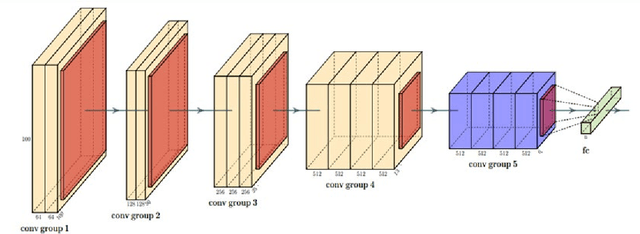
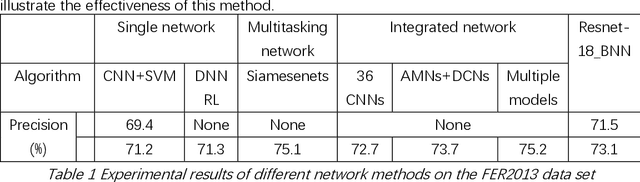
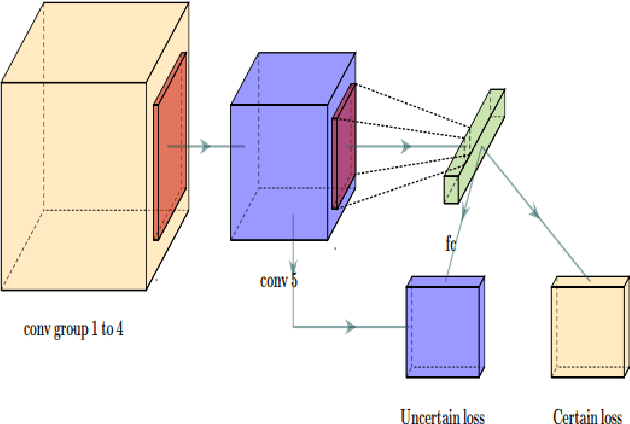
The seven basic facial expression classifications are a basic way to express complex human emotions and are an important part of artificial intelligence research. Based on the traditional Bayesian neural network framework, the ResNet18_BNN network constructed in this paper has been improved in the following three aspects: (1) A new objective function is proposed, which is composed of the KL loss of uncertain parameters and the intersection of specific parameters. Entropy loss composition. (2) Aiming at a special objective function, a training scheme for alternately updating these two parameters is proposed. (3) Only model the parameters of the last convolution group. Through testing on the FER2013 test set, we achieved 71.5% and 73.1% accuracy in PublicTestSet and PrivateTestSet, respectively. Compared with traditional Bayesian neural networks, our method brings the highest classification accuracy gain.
Real-Time Facial Expression Emoji Masking with Convolutional Neural Networks and Homography
Dec 24, 2020



Neural network based algorithms has shown success in many applications. In image processing, Convolutional Neural Networks (CNN) can be trained to categorize facial expressions of images of human faces. In this work, we create a system that masks a student's face with a emoji of the respective emotion. Our system consists of three building blocks: face detection using Histogram of Gradients (HoG) and Support Vector Machine (SVM), facial expression categorization using CNN trained on FER2013 dataset, and finally masking the respective emoji back onto the student's face via homography estimation. (Demo: https://youtu.be/GCjtXw1y8Pw) Our results show that this pipeline is deploy-able in real-time, and is usable in educational settings.
Evons: A Dataset for Fake and Real News Virality Analysis and Prediction
Sep 16, 2022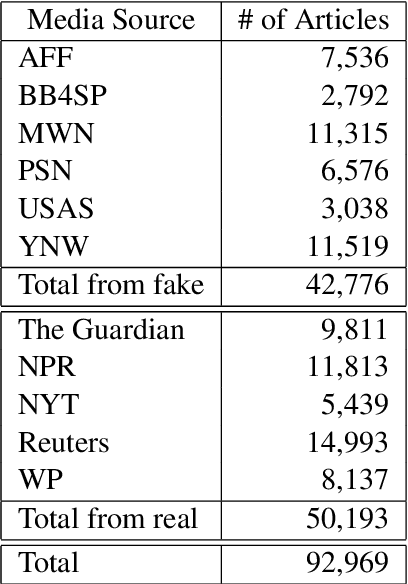
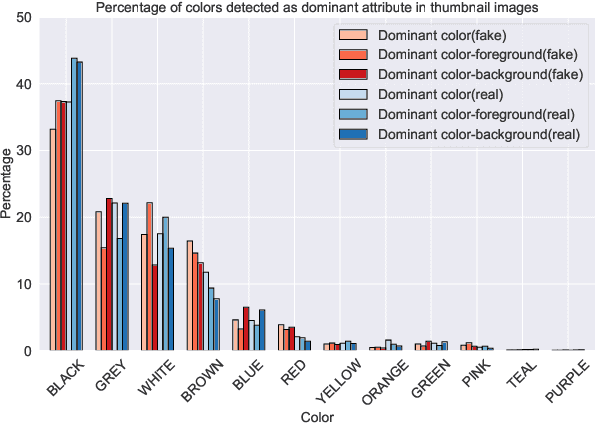

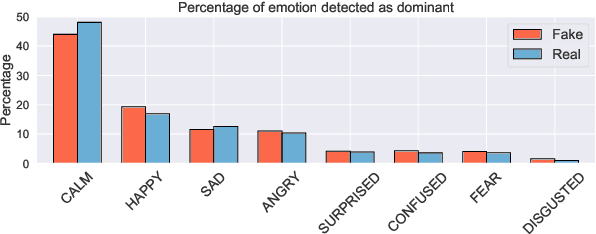
We present a novel collection of news articles originating from fake and real news media sources for the analysis and prediction of news virality. Unlike existing fake news datasets which either contain claims or news article headline and body, in this collection each article is supported with a Facebook engagement count which we consider as an indicator of the article virality. In addition we also provide the article description and thumbnail image with which the article was shared on Facebook. These images were automatically annotated with object tags and color attributes. Using cloud based vision analysis tools, thumbnail images were also analyzed for faces and detected faces were annotated with facial attributes. We empirically investigate the use of this collection on an example task of article virality prediction.
Towards Inclusive HRI: Using Sim2Real to Address Underrepresentation in Emotion Expression Recognition
Aug 15, 2022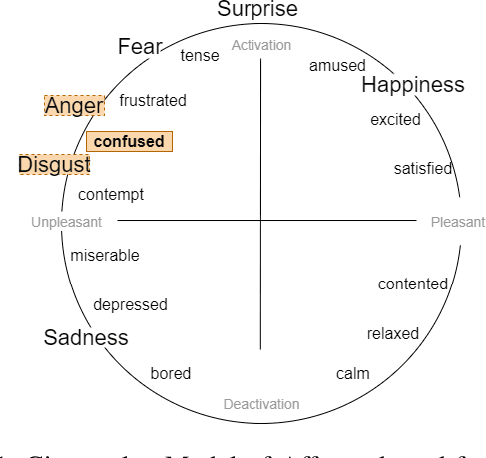



Robots and artificial agents that interact with humans should be able to do so without bias and inequity, but facial perception systems have notoriously been found to work more poorly for certain groups of people than others. In our work, we aim to build a system that can perceive humans in a more transparent and inclusive manner. Specifically, we focus on dynamic expressions on the human face, which are difficult to collect for a broad set of people due to privacy concerns and the fact that faces are inherently identifiable. Furthermore, datasets collected from the Internet are not necessarily representative of the general population. We address this problem by offering a Sim2Real approach in which we use a suite of 3D simulated human models that enables us to create an auditable synthetic dataset covering 1) underrepresented facial expressions, outside of the six basic emotions, such as confusion; 2) ethnic or gender minority groups; and 3) a wide range of viewing angles that a robot may encounter a human in the real world. By augmenting a small dynamic emotional expression dataset containing 123 samples with a synthetic dataset containing 4536 samples, we achieved an improvement in accuracy of 15% on our own dataset and 11% on an external benchmark dataset, compared to the performance of the same model architecture without synthetic training data. We also show that this additional step improves accuracy specifically for racial minorities when the architecture's feature extraction weights are trained from scratch.
Dive into Ambiguity: Latent Distribution Mining and Pairwise Uncertainty Estimation for Facial Expression Recognition
Apr 01, 2021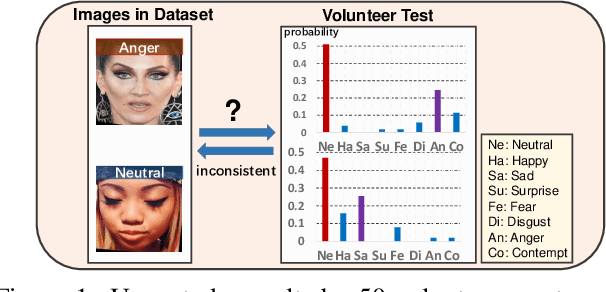
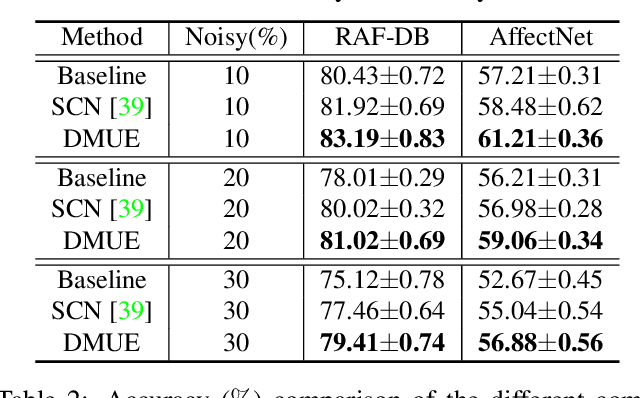
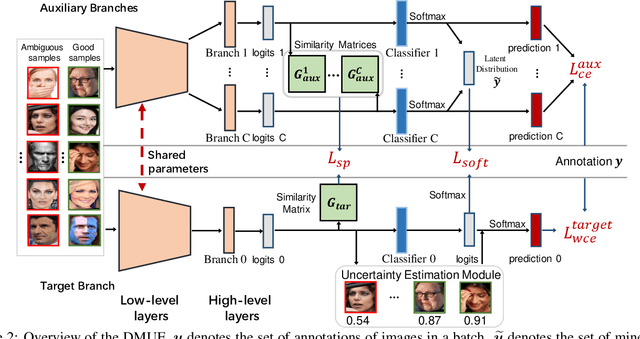
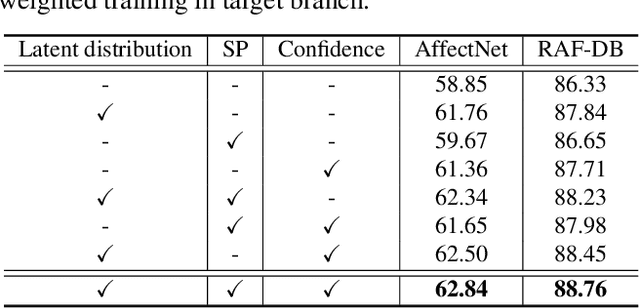
Due to the subjective annotation and the inherent interclass similarity of facial expressions, one of key challenges in Facial Expression Recognition (FER) is the annotation ambiguity. In this paper, we proposes a solution, named DMUE, to address the problem of annotation ambiguity from two perspectives: the latent Distribution Mining and the pairwise Uncertainty Estimation. For the former, an auxiliary multi-branch learning framework is introduced to better mine and describe the latent distribution in the label space. For the latter, the pairwise relationship of semantic feature between instances are fully exploited to estimate the ambiguity extent in the instance space. The proposed method is independent to the backbone architectures, and brings no extra burden for inference. The experiments are conducted on the popular real-world benchmarks and the synthetic noisy datasets. Either way, the proposed DMUE stably achieves leading performance.
Feature Level Fusion from Facial Attributes for Face Recognition
Sep 28, 2019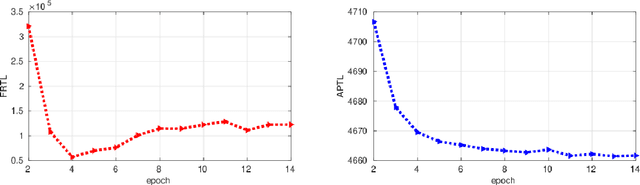


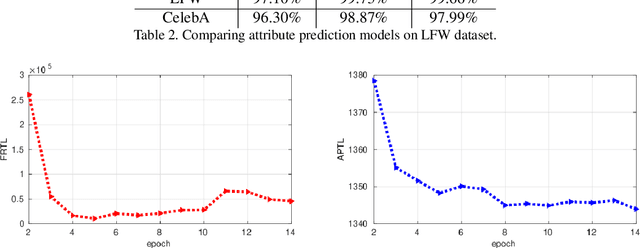
We introduce a deep convolutional neural networks (CNN) architecture to classify facial attributes and recognize face images simultaneously via a shared learning paradigm to improve the accuracy for facial attribute prediction and face recognition performance. In this method, we use facial attributes as an auxiliary source of information to assist CNN features extracted from the face images to improve the face recognition performance. Specifically, we use a shared CNN architecture that jointly predicts facial attributes and recognize face images simultaneously via a shared learning parameters, and then we use facial attribute features an an auxiliary source of information concatenated by face features to increase the discrimination of the CNN for face recognition. This process assists the CNN classifier to better recognize face images. The experimental results show that our model increases both the face recognition and facial attribute prediction performance, especially for the identity attributes such as gender and race. We evaluated our method on several standard datasets labeled by identities and face attributes and the results show that the proposed method outperforms state-of-the-art face recognition models.
Grand Challenge of 106-Point Facial Landmark Localization
May 09, 2019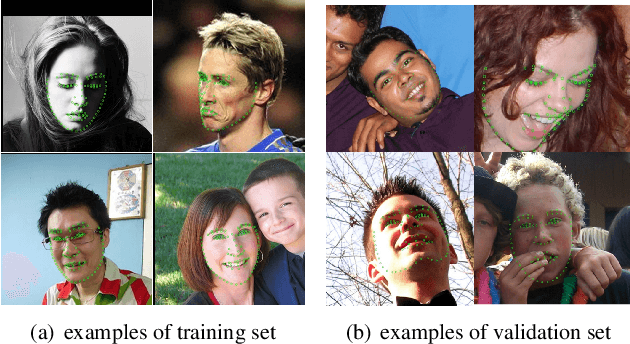
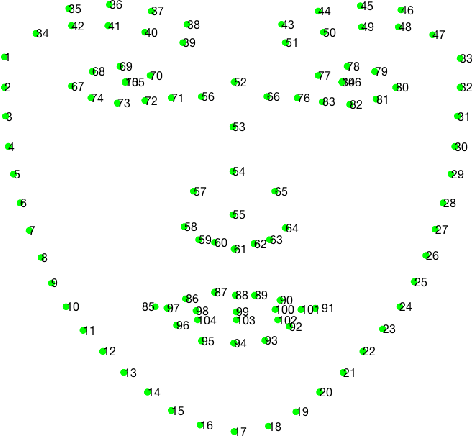

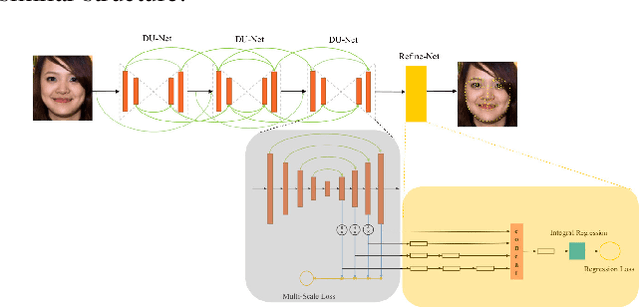
Facial landmark localization is a very crucial step in numerous face related applications, such as face recognition, facial pose estimation, face image synthesis, etc. However, previous competitions on facial landmark localization (i.e., the 300-W, 300-VW and Menpo challenges) aim to predict 68-point landmarks, which are incompetent to depict the structure of facial components. In order to overcome this problem, we construct a challenging dataset, named JD-landmark. Each image is manually annotated with 106-point landmarks. This dataset covers large variations on pose and expression, which brings a lot of difficulties to predict accurate landmarks. We hold a 106-point facial landmark localization competition1 on this dataset in conjunction with IEEE International Conference on Multimedia and Expo (ICME) 2019. The purpose of this competition is to discover effective and robust facial landmark localization approaches.