 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFireRed-Image-Edit-1.0 Techinical Report
Feb 12, 2026We present FireRed-Image-Edit, a diffusion transformer for instruction-based image editing that achieves state-of-the-art performance through systematic optimization of data curation, training methodology, and evaluation design. We construct a 1.6B-sample training corpus, comprising 900M text-to-image and 700M image editing pairs from diverse sources. After rigorous cleaning, stratification, auto-labeling, and two-stage filtering, we retain over 100M high-quality samples balanced between generation and editing, ensuring strong semantic coverage and instruction alignment. Our multi-stage training pipeline progressively builds editing capability via pre-training, supervised fine-tuning, and reinforcement learning. To improve data efficiency, we introduce a Multi-Condition Aware Bucket Sampler for variable-resolution batching and Stochastic Instruction Alignment with dynamic prompt re-indexing. To stabilize optimization and enhance controllability, we propose Asymmetric Gradient Optimization for DPO, DiffusionNFT with layout-aware OCR rewards for text editing, and a differentiable Consistency Loss for identity preservation. We further establish REDEdit-Bench, a comprehensive benchmark spanning 15 editing categories, including newly introduced beautification and low-level enhancement tasks. Extensive experiments on REDEdit-Bench and public benchmarks (ImgEdit and GEdit) demonstrate competitive or superior performance against both open-source and proprietary systems. We release code, models, and the benchmark suite to support future research.
IGDMRec: Behavior Conditioned Item Graph Diffusion for Multimodal Recommendation
Dec 23, 2025



Multimodal recommender systems (MRSs) are critical for various online platforms, offering users more accurate personalized recommendations by incorporating multimodal information of items. Structure-based MRSs have achieved state-of-the-art performance by constructing semantic item graphs, which explicitly model relationships between items based on modality feature similarity. However, such semantic item graphs are often noisy due to 1) inherent noise in multimodal information and 2) misalignment between item semantics and user-item co-occurrence relationships, which introduces false links and leads to suboptimal recommendations. To address this challenge, we propose Item Graph Diffusion for Multimodal Recommendation (IGDMRec), a novel method that leverages a diffusion model with classifier-free guidance to denoise the semantic item graph by integrating user behavioral information. Specifically, IGDMRec introduces a Behavior-conditioned Graph Diffusion (BGD) module, incorporating interaction data as conditioning information to guide the denoising of the semantic item graph. Additionally, a Conditional Denoising Network (CD-Net) is designed to implement the denoising process with manageable complexity. Finally, we propose a contrastive representation augmentation scheme that leverages both the denoised item graph and the original item graph to enhance item representations. \LL{Extensive experiments on four real-world datasets demonstrate the superiority of IGDMRec over competitive baselines, with robustness analysis validating its denoising capability and ablation studies verifying the effectiveness of its key components.
Target-Driven Distillation: Consistency Distillation with Target Timestep Selection and Decoupled Guidance
Sep 02, 2024



Consistency distillation methods have demonstrated significant success in accelerating generative tasks of diffusion models. However, since previous consistency distillation methods use simple and straightforward strategies in selecting target timesteps, they usually struggle with blurs and detail losses in generated images. To address these limitations, we introduce Target-Driven Distillation (TDD), which (1) adopts a delicate selection strategy of target timesteps, increasing the training efficiency; (2) utilizes decoupled guidances during training, making TDD open to post-tuning on guidance scale during inference periods; (3) can be optionally equipped with non-equidistant sampling and x0 clipping, enabling a more flexible and accurate way for image sampling. Experiments verify that TDD achieves state-of-the-art performance in few-step generation, offering a better choice among consistency distillation models.
Grand Challenge of 106-Point Facial Landmark Localization
May 09, 2019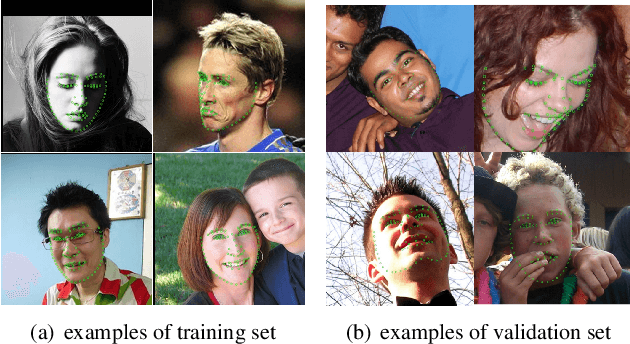
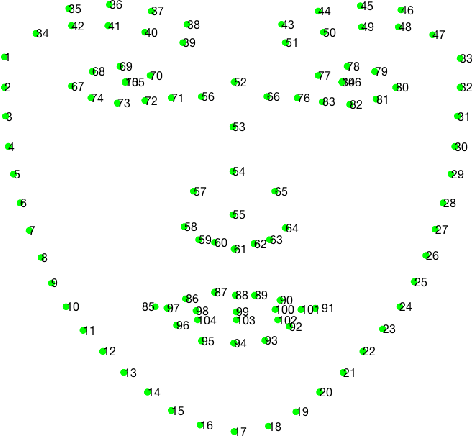

Facial landmark localization is a very crucial step in numerous face related applications, such as face recognition, facial pose estimation, face image synthesis, etc. However, previous competitions on facial landmark localization (i.e., the 300-W, 300-VW and Menpo challenges) aim to predict 68-point landmarks, which are incompetent to depict the structure of facial components. In order to overcome this problem, we construct a challenging dataset, named JD-landmark. Each image is manually annotated with 106-point landmarks. This dataset covers large variations on pose and expression, which brings a lot of difficulties to predict accurate landmarks. We hold a 106-point facial landmark localization competition1 on this dataset in conjunction with IEEE International Conference on Multimedia and Expo (ICME) 2019. The purpose of this competition is to discover effective and robust facial landmark localization approaches.