 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlearning Concepts from Text-to-Video Diffusion Models
Jul 19, 2024With the advancement of computer vision and natural language processing, text-to-video generation, enabled by text-to-video diffusion models, has become more prevalent. These models are trained using a large amount of data from the internet. However, the training data often contain copyrighted content, including cartoon character icons and artist styles, private portraits, and unsafe videos. Since filtering the data and retraining the model is challenging, methods for unlearning specific concepts from text-to-video diffusion models have been investigated. However, due to the high computational complexity and relative large optimization scale, there is little work on unlearning methods for text-to-video diffusion models. We propose a novel concept-unlearning method by transferring the unlearning capability of the text encoder of text-to-image diffusion models to text-to-video diffusion models. Specifically, the method optimizes the text encoder using few-shot unlearning, where several generated images are used. We then use the optimized text encoder in text-to-video diffusion models to generate videos. Our method costs low computation resources and has small optimization scale. We discuss the generated videos after unlearning a concept. The experiments demonstrates that our method can unlearn copyrighted cartoon characters, artist styles, objects and people's facial characteristics. Our method can unlearn a concept within about 100 seconds on an RTX 3070. Since there was no concept unlearning method for text-to-video diffusion models before, we make concept unlearning feasible and more accessible in the text-to-video domain.
SkySenseGPT: A Fine-Grained Instruction Tuning Dataset and Model for Remote Sensing Vision-Language Understanding
Jun 14, 2024Remote Sensing Large Multi-Modal Models (RSLMMs) are developing rapidly and showcase significant capabilities in remote sensing imagery (RSI) comprehension. However, due to the limitations of existing datasets, RSLMMs have shortcomings in understanding the rich semantic relations among objects in complex remote sensing scenes. To unlock RSLMMs' complex comprehension ability, we propose a large-scale instruction tuning dataset FIT-RS, containing 1,800,851 instruction samples. FIT-RS covers common interpretation tasks and innovatively introduces several complex comprehension tasks of escalating difficulty, ranging from relation reasoning to image-level scene graph generation. Based on FIT-RS, we build the FIT-RSFG benchmark. Furthermore, we establish a new benchmark to evaluate the fine-grained relation comprehension capabilities of LMMs, named FIT-RSRC. Based on combined instruction data, we propose SkySenseGPT, which achieves outstanding performance on both public datasets and FIT-RSFG, surpassing existing RSLMMs. We hope the FIT-RS dataset can enhance the relation comprehension capability of RSLMMs and provide a large-scale fine-grained data source for the remote sensing community. The dataset will be available at https://github.com/Luo-Z13/SkySenseGPT
MonoCD: Monocular 3D Object Detection with Complementary Depths
Apr 04, 2024Monocular 3D object detection has attracted widespread attention due to its potential to accurately obtain object 3D localization from a single image at a low cost. Depth estimation is an essential but challenging subtask of monocular 3D object detection due to the ill-posedness of 2D to 3D mapping. Many methods explore multiple local depth clues such as object heights and keypoints and then formulate the object depth estimation as an ensemble of multiple depth predictions to mitigate the insufficiency of single-depth information. However, the errors of existing multiple depths tend to have the same sign, which hinders them from neutralizing each other and limits the overall accuracy of combined depth. To alleviate this problem, we propose to increase the complementarity of depths with two novel designs. First, we add a new depth prediction branch named complementary depth that utilizes global and efficient depth clues from the entire image rather than the local clues to reduce the correlation of depth predictions. Second, we propose to fully exploit the geometric relations between multiple depth clues to achieve complementarity in form. Benefiting from these designs, our method achieves higher complementarity. Experiments on the KITTI benchmark demonstrate that our method achieves state-of-the-art performance without introducing extra data. In addition, complementary depth can also be a lightweight and plug-and-play module to boost multiple existing monocular 3d object detectors. Code is available at https://github.com/elvintanhust/MonoCD.
Learning to Holistically Detect Bridges from Large-Size VHR Remote Sensing Imagery
Dec 05, 2023



Bridge detection in remote sensing images (RSIs) plays a crucial role in various applications, but it poses unique challenges compared to the detection of other objects. In RSIs, bridges exhibit considerable variations in terms of their spatial scales and aspect ratios. Therefore, to ensure the visibility and integrity of bridges, it is essential to perform holistic bridge detection in large-size very-high-resolution (VHR) RSIs. However, the lack of datasets with large-size VHR RSIs limits the deep learning algorithms' performance on bridge detection. Due to the limitation of GPU memory in tackling large-size images, deep learning-based object detection methods commonly adopt the cropping strategy, which inevitably results in label fragmentation and discontinuous prediction. To ameliorate the scarcity of datasets, this paper proposes a large-scale dataset named GLH-Bridge comprising 6,000 VHR RSIs sampled from diverse geographic locations across the globe. These images encompass a wide range of sizes, varying from 2,048*2,048 to 16,38*16,384 pixels, and collectively feature 59,737 bridges. Furthermore, we present an efficient network for holistic bridge detection (HBD-Net) in large-size RSIs. The HBD-Net presents a separate detector-based feature fusion (SDFF) architecture and is optimized via a shape-sensitive sample re-weighting (SSRW) strategy. Based on the proposed GLH-Bridge dataset, we establish a bridge detection benchmark including the OBB and HBB tasks, and validate the effectiveness of the proposed HBD-Net. Additionally, cross-dataset generalization experiments on two publicly available datasets illustrate the strong generalization capability of the GLH-Bridge dataset.
Bayesian Convolutional Neural Networks for Seven Basic Facial Expression Classifications
Jul 13, 2021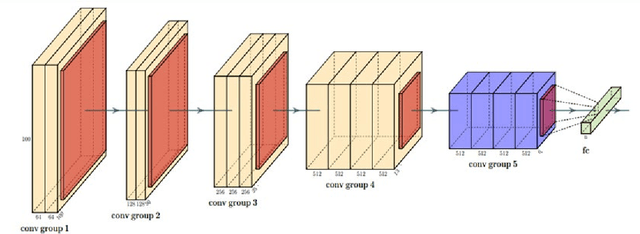
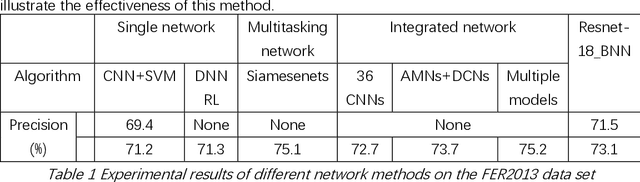
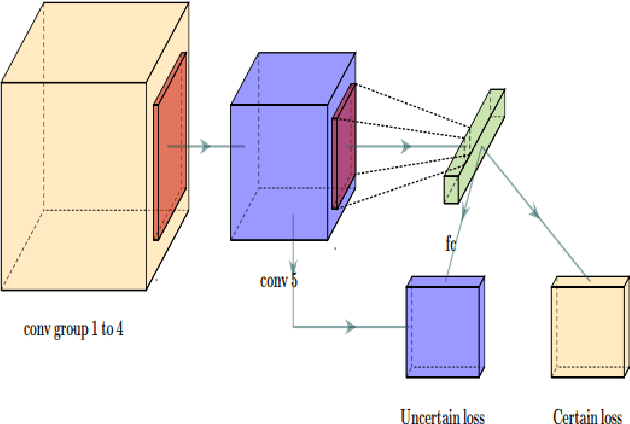
The seven basic facial expression classifications are a basic way to express complex human emotions and are an important part of artificial intelligence research. Based on the traditional Bayesian neural network framework, the ResNet18_BNN network constructed in this paper has been improved in the following three aspects: (1) A new objective function is proposed, which is composed of the KL loss of uncertain parameters and the intersection of specific parameters. Entropy loss composition. (2) Aiming at a special objective function, a training scheme for alternately updating these two parameters is proposed. (3) Only model the parameters of the last convolution group. Through testing on the FER2013 test set, we achieved 71.5% and 73.1% accuracy in PublicTestSet and PrivateTestSet, respectively. Compared with traditional Bayesian neural networks, our method brings the highest classification accuracy gain.
Unsupervised Learning Framework of Interest Point Via Properties Optimization
Jul 26, 2019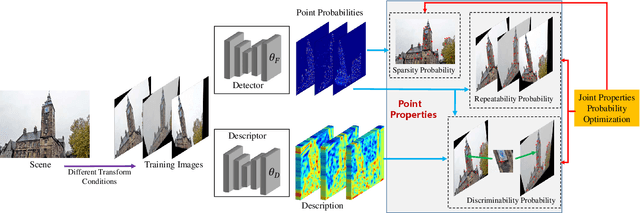
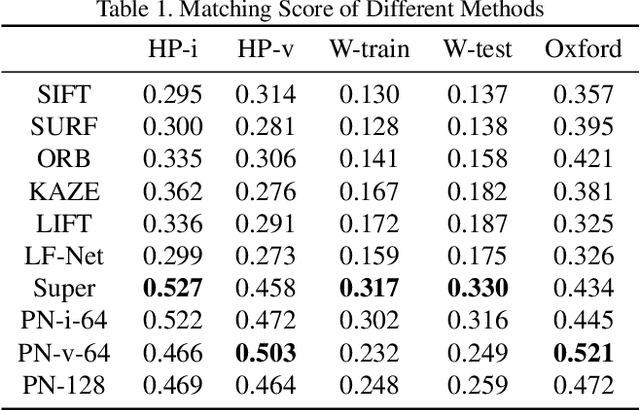

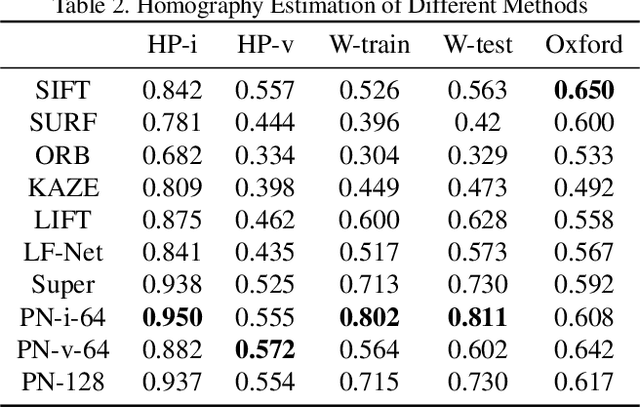
This paper presents an entirely unsupervised interest point training framework by jointly learning detector and descriptor, which takes an image as input and outputs a probability and a description for every image point. The objective of the training framework is formulated as joint probability distribution of the properties of the extracted points. The essential properties are selected as sparsity, repeatability and discriminability which are formulated by the probabilities. To maximize the objective efficiently, latent variable is introduced to represent the probability of that a point satisfies the required properties. Therefore, original maximization can be optimized with Expectation Maximization algorithm (EM). Considering high computation cost of EM on large scale image set, we implement the optimization process with an efficient strategy as Mini-Batch approximation of EM (MBEM). In the experiments both detector and descriptor are instantiated with fully convolutional network which is named as Property Network (PN). The experiments demonstrate that PN outperforms state-of-the-art methods on a number of image matching benchmarks without need of retraining. PN also reveals that the proposed training framework has high flexibility to adapt to diverse types of scenes.
Optimize TSK Fuzzy Systems for Big Data Regression Problems: Mini-Batch Gradient Descent with Regularization, DropRule and AdaBound
Mar 26, 2019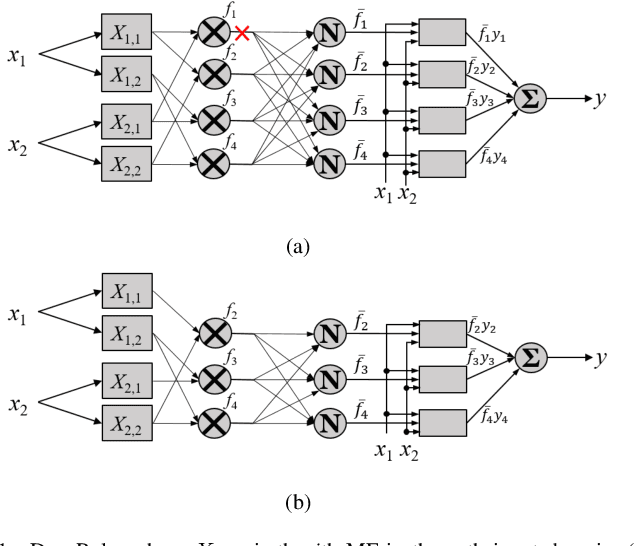
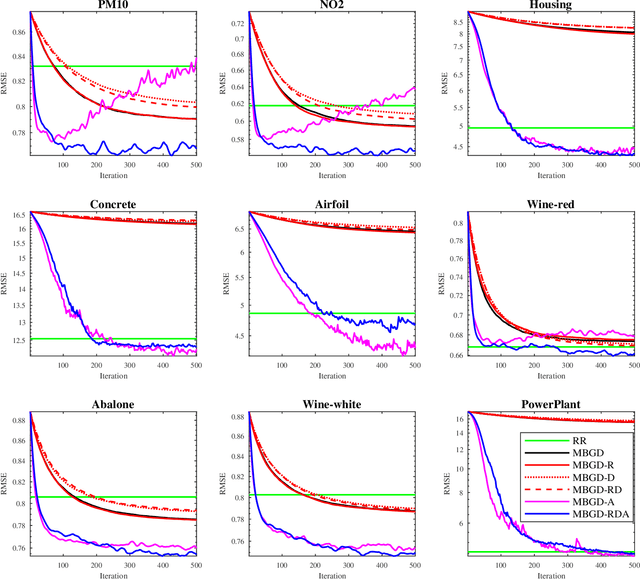
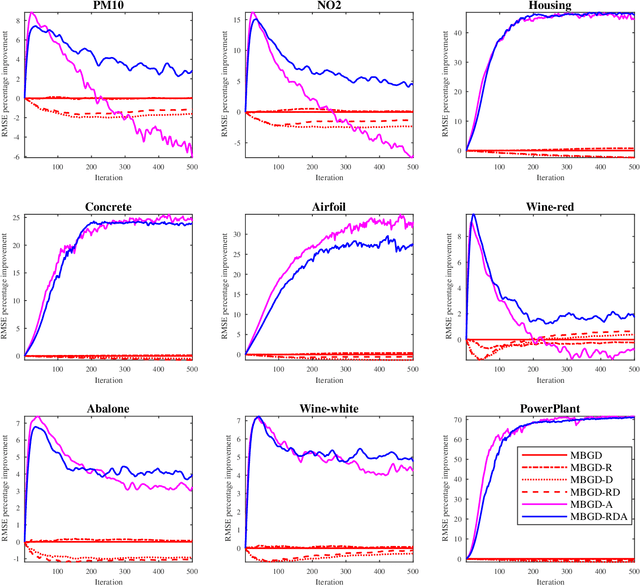
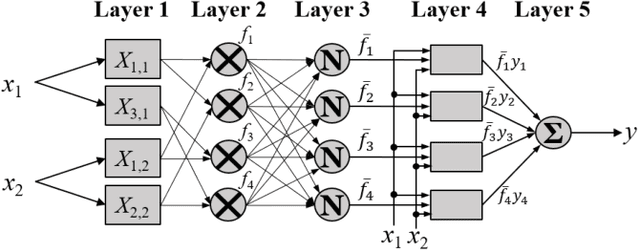
Takagi-Sugeno-Kang (TSK) fuzzy systems are very useful machine learning models for regression problems. However, to our knowledge, there has not existed an efficient and effective training algorithm that enables them to deal with big data. Inspired by the connections between TSK fuzzy systems and neural networks, we extend three powerful neural network optimization techniques, i.e., mini-batch gradient descent, regularization, and AdaBound, to TSK fuzzy systems, and also propose a novel DropRule technique specifically for training TSK fuzzy systems. Our final algorithm, mini-batch gradient descent with regularization, DropRule and AdaBound (MBGD-RDA), can achieve fast convergence in training TSK fuzzy systems, and also superior generalization performance in testing. It can be used for training TSK fuzzy systems on datasets of any size; however, it is particularly useful for big datasets, on which currently no other efficient training algorithms exist.